https://github.com/dltcollab/dcurl
Hardware-accelerated Multi-threaded IOTA PoW, drop-in replacement for ccurl
https://github.com/dltcollab/dcurl
biilabs fpga iota nonce opencl pearldiver pow simd tangle trytes
Last synced: about 1 year ago
JSON representation
Hardware-accelerated Multi-threaded IOTA PoW, drop-in replacement for ccurl
- Host: GitHub
- URL: https://github.com/dltcollab/dcurl
- Owner: DLTcollab
- License: mit
- Created: 2018-01-09T10:07:50.000Z (over 8 years ago)
- Default Branch: develop
- Last Pushed: 2021-06-11T16:40:52.000Z (about 5 years ago)
- Last Synced: 2025-04-07T13:06:11.405Z (over 1 year ago)
- Topics: biilabs, fpga, iota, nonce, opencl, pearldiver, pow, simd, tangle, trytes
- Language: C
- Homepage:
- Size: 849 KB
- Stars: 41
- Watchers: 11
- Forks: 23
- Open Issues: 3
-
Metadata Files:
- Readme: README.md
- Changelog: changelog.hbs
- License: LICENSE
- Authors: AUTHORS
Awesome Lists containing this project
README
# dcurl - Multi-threaded Curl implementation
[](https://buildkite.com/dltcollab/dcurl-test)


Hardware-accelerated implementation for IOTA PearlDiver, which utilizes multi-threaded SIMD, FPGA and GPU.
## Introduction
dcurl exploits SIMD instructions on CPU and OpenCL on GPU. Both CPU and GPU accelerations can be
enabled in multi-threaded execuction fashion, resulting in much faster [proof-of-work (PoW) for IOTA](https://docs.iota.org/docs/the-tangle/0.1/concepts/proof-of-work).
In addition, dcurl supports FPGA-accelerated PoW, described in [docs/fpga-accelerator.md](docs/fpga-accelerator.md).
dcurl can be regarded as the drop-in replacement for [ccurl](https://github.com/iotaledger/ccurl).
IOTA Reference Implementation (IRI) adaptation is available to benefit from hardware-accelerated PoW.
## Build Instructions
Check [docs/build-n-test.md](docs/build-n-test.md) for details.
## Source Code Naming Convention
Check [docs/naming-convention.md](docs/naming-convention.md) for details.
## Generate Document
```
$ make doc
```
## Performance
After integrating dcurl into IRI, performance of [attachToTangle](https://docs.iota.org/docs/node-software/0.1/iri/references/api-reference#attachtotangle) is measured as the following.
* Setting: MWM = 14, 200 attachToTangle API requests with each containing 2 transactions
* Local CPU:
* AMD Ryzen Threadripper 2990WX 32-Core Processor
* 2 PoW tasks at the same time
* Each task uses 32 CPU threads to find nonce
* SIMD enabled
* Remote worker:
* The board with Intel/Altera Cyclone V SoC
* 1 PoW task at the same time in a board
* FPGA acceleration enabled
* Connected with local network
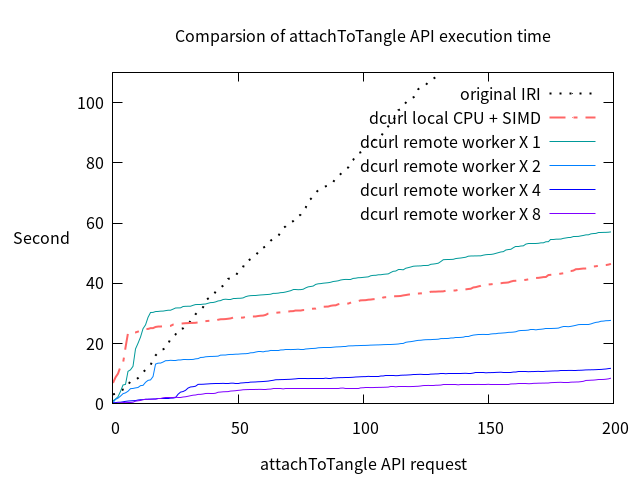
### Conclusion
Except the original IRI, the other instances use the [DLTcollab/IRI](https://github.com/DLTcollab/iri) instead of [iotaledger/IRI](https://github.com/iotaledger/iri).
| IRI version | attachToTangle API behavior | Effect |
|:-|:-|:-|
| IOTA IRI | One transaction bundle at the same time **(Synchronized)** | Transactions of a bundle are calculated one by one |
| DLTCollab IRI | Multiple transaction bundles at the same time | Transactions of different bundles compete for the PoW calculation resources |
The original IRI should be the slowest one since it does not contain any PoW acceleration.
However, the graph is different from the expectation.
This is caused by 2 factors:
* The graph shows the execution time of each API request instead of the overall throughput.
* The table shows that there are competition of the PoW resources, which means the execution time would be longer than expected.
And from the graph we can see that 4 remote workers would be a good choice to accelerate PoW.
## IRI Adaptation
[Modified IRI accepting external PoW Library](https://github.com/DLTcollab/iri)
Supported IRI version: 1.7.0
Load the external dcurl shared library from the installed JAR file
* ```$ cd ~/iri && make check```
* ```$ java -jar target/iri.jar -p --pearldiver-exlib dcurl```
## Adoptions
Here is a partial list of open source projects that have adopted dcurl. If you
are using dcurl and would like your projects added to the list, please send
pull requests to dcurl.
1. [iota-gpu-pow](https://github.com/gagathos/iota-gpu-pow): IOTA PoW node
* You can construct a IOTA PoW node, which uses `ccurl` by default
* Generate a drop-in replacement for `ccurl` and acquire performance boost.
* ```$ make BUILD_COMPAT=1 check```
* ```$ cp ./build/libdcurl.so /libccurl.so```
2. [iota.keccak.pow.node.js](https://github.com/SteppoFF/iota.keccak.pow.node.js): IOTA PoW node using the iota.keccak.js implementation
* [iota.keccak.js](https://github.com/SteppoFF/iota.keccak.js) can be used to
build high performance node-js spammers but is also capable of signing
inputs for value bundles. Using a smart implementation and remote PoW,
it is capable of performing > 100 TPS for IRI.
3. [IOTA PoW Hardware Accelerator FPGA for Raspberry Pi](https://microengineer.eu/2018/04/25/iota-pearl-diver-fpga/) took dcurl for prototyping.
* Check [shufps/dcurl](https://github.com/shufps/dcurl) and [shufps/iota_vhdl_pow](https://github.com/shufps/iota_vhdl_pow)
for tracking historical changes outperforming 200x speedup than a Raspberry Pi without hardware hccelerator.
4. [tangle-accelerator](https://github.com/DLTcollab/tangle-accelerator): caching proxy server for IOTA, which can cache API requests and rewrite their responses as needed to be routed through full nodes.
* An instance of Tangle-accelerator can serve thousands of Tangle requests
at once without accessing remote full nodes frequently.
* As an intermediate server accelerateing interactions with the Tangle,
it faciliates dcurl to perform hardware-accelerated PoW operations on
edge devices.
## FAQ
- What is **binary encoded ternary**?
It is a skill to transform the ternary trit value to two separate bits value.\
Hence multiple trits can be compressed to two separate data of the same data type and fully utilize the space.
- Can the project [Batch Binary Encoded Ternary Curl](https://github.com/luca-moser/bct_curl) be applied to dcurl?
The answer is no.\
They both use the same skill, **binary encoded ternary**.\
However, their purpose are totally different.
- **bct_curl**:
Focus on hashing the multiple data of the same length at the same time.\
It ends when the hashing is finished.
- **dcurl**:
Focus on trying the different values of one transaction at the same time to find the nonce value.\
The procedure of finding the nonce value also does the hashing.\
However, it ends when the nonce value is found, which means one of the values is acceptable.
## Licensing
`dcurl` is freely redistributable under the MIT License.
Use of this source code is governed by a MIT-style license that can be
found in the `LICENSE` file.