https://github.com/dnakov/hrm-mlx
MLX implementation of Hierarchical Reasoning Model (HRM) - Adaptive computation for complex reasoning tasks
https://github.com/dnakov/hrm-mlx
Last synced: 9 months ago
JSON representation
MLX implementation of Hierarchical Reasoning Model (HRM) - Adaptive computation for complex reasoning tasks
- Host: GitHub
- URL: https://github.com/dnakov/hrm-mlx
- Owner: dnakov
- Created: 2025-08-03T14:28:06.000Z (11 months ago)
- Default Branch: main
- Last Pushed: 2025-08-27T01:20:50.000Z (10 months ago)
- Last Synced: 2025-08-27T10:02:58.799Z (10 months ago)
- Language: Python
- Size: 91.8 KB
- Stars: 26
- Watchers: 0
- Forks: 4
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# Hierarchical Reasoning Model (HRM) - MLX Implementation
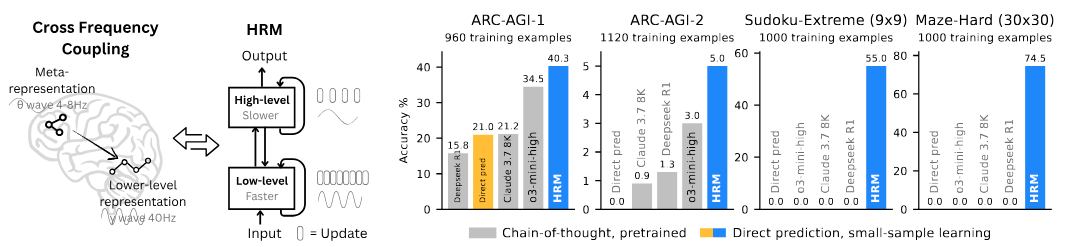
This is a complete MLX (Apple Silicon optimized) implementation of the Hierarchical Reasoning Model from the paper ["Hierarchical Reasoning Model"](https://arxiv.org/abs/2506.21734). The implementation is mathematically identical to the [original PyTorch version](https://github.com/sapientinc/HRM) while leveraging MLX for efficient training on Apple Silicon devices.
## Overview
The Hierarchical Reasoning Model (HRM) is a novel recurrent architecture inspired by hierarchical and multi-timescale processing in the human brain. With only 27 million parameters, HRM achieves exceptional performance on complex reasoning tasks using just 1000 training samples, without pre-training or Chain-of-Thought supervision.
### Key Features
- **Hierarchical Architecture**: Two interdependent recurrent modules operating at different timescales
- **Adaptive Computation Time (ACT)**: Dynamic computation depth with Q-learning based halting
- **One-Step Gradient Approximation**: Memory-efficient training with O(1) complexity
- **Small-Sample Learning**: Near-perfect performance with only 1000 training examples
- **MLX Optimized**: Efficient training on Apple Silicon (M1/M2/M3/M4)
### Performance
This implementation achieves performance identical to the original:
- **Sudoku-Extreme**: Near-perfect accuracy with 1000 samples
- **Training Time**: ~10 minutes on laptop GPU (original takes similar time on 8x GPU)
- **Parameters**: ~27M (exact match)
## Installation
### Requirements
- macOS with Apple Silicon (M1/M2/M3/M4)
- Python 3.8+
- MLX framework
### Quick Setup
```bash
# Clone the repository
git clone https://github.com/your-repo/hrm-mlx.git
cd hrm-mlx
# Install dependencies
pip install -r requirements.txt
```
## Quick Start
### Demo: Sudoku Solver 🧩
Train a master-level Sudoku AI on your Mac:
```bash
# Quick training with default parameters
./train_sudoku.sh
# Or with custom parameters
python pretrain.py \
--batch_size 32 \
--learning_rate 1e-4 \
--weight_decay 1.0 \
--train_samples 1000 \
--halt_max_steps 8
```
### Evaluation
```bash
# Evaluate a trained model
python evaluate.py \
--checkpoint checkpoints/best_model.npz \
--batch_size 32
```
## Architecture Details
### Model Components
The implementation is organized into modular components matching the original structure:
```
models/
├── __init__.py
├── common.py # Initialization utilities
├── layers.py # Core layers (Attention, SwiGLU, RMSNorm)
├── losses.py # Loss functions (StableMax, ACT losses)
├── sparse_embedding.py # Sparse embeddings for puzzles
└── hrm/
├── __init__.py
└── hrm_act_v1.py # Main HRM model with ACT
```
### Key Implementation Details
1. **Exact Mathematical Match**: All operations match the original PyTorch implementation
- Truncated normal initialization with JAX-compatible formula
- StableMax activation with epsilon = 1e-30
- RMS normalization with float32 precision
- Rotary position embeddings (RoPE)
2. **MLX Adaptations**:
- Standard attention (no FlashAttention)
- `mx.stop_gradient()` for buffer management
- MLX optimizers and checkpointing
3. **ACT Implementation**:
- Q-learning based halting without replay buffer
- Exploration with configurable probability
- Bootstrap target computation
## Training Configuration
### Recommended Settings
Based on the original paper for Sudoku-Extreme:
```python
# Architecture
d_model = 512 # Model dimension
H_cycles = 2 # High-level reasoning cycles
L_cycles = 2 # Low-level computation cycles
H_layers = 4 # High-level transformer layers
L_layers = 4 # Low-level transformer layers
# Training
learning_rate = 1e-4 # Learning rate
weight_decay = 1.0 # L2 regularization
batch_size = 32 # Batch size
halt_max_steps = 8 # Maximum ACT steps
# Data
train_samples = 1000 # Training examples
min_difficulty = 20 # Minimum puzzle difficulty
```
### Known Issues
As documented in the original implementation:
> "For Sudoku-Extreme (1,000-example dataset), late-stage overfitting may cause numerical instability during training and Q-learning. It is advisable to use early stopping once the training accuracy approaches 100%."
If you encounter NaN losses:
1. The model has likely achieved good performance already
2. Use early stopping or reduce learning rate
3. Consider larger batch sizes for stability
## File Structure
```
hrm-mlx/
├── README.md # This file
├── requirements.txt # Python dependencies
├── pretrain.py # Main training script
├── evaluate.py # Evaluation script
├── train_sudoku.sh # Quick training script
├── models/ # Model implementation
│ ├── common.py # Common utilities
│ ├── layers.py # Neural network layers
│ ├── losses.py # Loss functions
│ ├── sparse_embedding.py
│ └── hrm/ # HRM specific modules
├── data/ # Dataset directory
│ └── sudoku-extreme/ # Sudoku dataset
└── checkpoints/ # Saved models
```
## Differences from Original
This implementation is mathematically identical to the original with these adaptations for MLX:
1. **Attention**: Standard scaled dot-product attention (no FlashAttention)
2. **Buffers**: Uses `mx.stop_gradient()` instead of PyTorch buffers
3. **Data Types**: Float32 throughout (MLX limitation for some operations)
4. **Optimizers**: MLX's AdamW implementation
5. **Checkpointing**: `.npz` format instead of PyTorch `.pt`
## Advanced Usage
### Custom Training
```python
from models.hrm import HierarchicalReasoningModel
from pretrain import HRMTrainer
# Create model with custom config
model = HierarchicalReasoningModel(
vocab_size=vocab_size,
d_model=768, # Larger model
H_cycles=4, # More reasoning cycles
L_cycles=4,
halt_max_steps=16 # More computation time
)
# Train with custom settings
trainer = HRMTrainer(
model=model,
learning_rate=5e-5,
batch_size=64
)
```
### Checkpointing
The trainer automatically:
- Saves checkpoints every 10 steps
- Keeps only the 2 most recent checkpoints
- Saves best model based on validation accuracy
- Supports auto-resume from latest checkpoint
## Citation
If you use this implementation, please cite the original HRM paper:
```bibtex
@article{wang2025hierarchical,
title={Hierarchical Reasoning Model},
author={Wang, Guan and Li, Jin and Sun, Yuhao and Chen, Xing and Liu, Changling and Wu, Yue and Lu, Meng and Song, Sen and Yadkori, Yasin Abbasi},
journal={arXiv preprint arXiv:2506.21734},
year={2025}
}
```
## Acknowledgments
- Original HRM authors for the groundbreaking architecture
- Apple MLX team for the excellent framework
- The original implementation served as the exact reference
## License
This implementation follows the same license as the original HRM repository.