https://github.com/dselivanov/rsparse
Fast and accurate machine learning on sparse matrices - matrix factorizations, regression, classification, top-N recommendations.
https://github.com/dselivanov/rsparse
collaborative-filtering factorization-machines matrix-completion matrix-factorization r recommender-system sparse-matrices svd
Last synced: about 1 year ago
JSON representation
Fast and accurate machine learning on sparse matrices - matrix factorizations, regression, classification, top-N recommendations.
- Host: GitHub
- URL: https://github.com/dselivanov/rsparse
- Owner: dselivanov
- Created: 2017-05-10T07:57:16.000Z (about 9 years ago)
- Default Branch: master
- Last Pushed: 2025-02-17T01:00:08.000Z (over 1 year ago)
- Last Synced: 2025-05-12T07:52:51.271Z (about 1 year ago)
- Topics: collaborative-filtering, factorization-machines, matrix-completion, matrix-factorization, r, recommender-system, sparse-matrices, svd
- Language: R
- Homepage: https://www.slideshare.net/DmitriySelivanov/matrix-factorizations-for-recommender-systems
- Size: 1.09 MB
- Stars: 174
- Watchers: 16
- Forks: 31
- Open Issues: 4
-
Metadata Files:
- Readme: README.md
- Changelog: NEWS.md
Awesome Lists containing this project
README
# rsparse 
[](https://github.com/dselivanov/rsparse/actions)
[](https://app.codecov.io/gh/rexyai/rsparse/branch/master)
[](http://www.gnu.org/licenses/gpl-2.0.html)
[](https://lifecycle.r-lib.org/articles/stages.html#maturing)
`rsparse` is an R package for statistical learning primarily on **sparse matrices** - **matrix factorizations, factorization machines, out-of-core regression**. Many of the implemented algorithms are particularly useful for **recommender systems** and **NLP**.
We've paid some attention to the implementation details - we try to avoid data copies, utilize multiple threads via OpenMP and use SIMD where appropriate. Package **allows to work on datasets with millions of rows and millions of columns**.
# Features
### Classification/Regression
1. [Follow the proximally-regularized leader](http://proceedings.mlr.press/v15/mcmahan11b/mcmahan11b.pdf) which allows to solve **very large linear/logistic regression** problems with elastic-net penalty. Solver uses stochastic gradient descent with adaptive learning rates (so can be used for online learning - not necessary to load all data to RAM). See [Ad Click Prediction: a View from the Trenches](https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/41159.pdf) for more examples.
- Only logistic regerssion implemented at the moment
- Native format for matrices is CSR - `Matrix::RsparseMatrix`. However common R `Matrix::CsparseMatrix` (`dgCMatrix`) will be converted automatically.
1. [Factorization Machines](https://cseweb.ucsd.edu/classes/fa17/cse291-b/reading/Rendle2010FM.pdf) supervised learning algorithm which learns second order polynomial interactions in a factorized way. We provide highly optimized SIMD accelerated implementation.
### Matrix Factorizations
1. Vanilla **Maximum Margin Matrix Factorization** - classic approch for "rating" prediction. See `WRMF` class and constructor option `feedback = "explicit"`. Original paper which indroduced MMMF could be found [here](https://ttic.uchicago.edu/~nati/Publications/MMMFnips04.pdf).
* 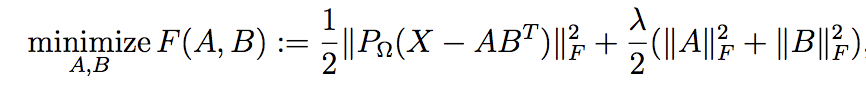
1. **Weighted Regularized Matrix Factorization (WRMF)** from [Collaborative Filtering for Implicit Feedback Datasets](http://yifanhu.net/PUB/cf.pdf). See `WRMF` class and constructor option `feedback = "implicit"`.
We provide 2 solvers:
1. Exact based on Cholesky Factorization
1. Approximated based on fixed number of steps of **Conjugate Gradient**.
See details in [Applications of the Conjugate Gradient Method for Implicit Feedback Collaborative Filtering](https://dl.acm.org/doi/10.1145/2043932.2043987) and [Faster Implicit Matrix Factorization](http://www.benfrederickson.com/fast-implicit-matrix-factorization/).
* 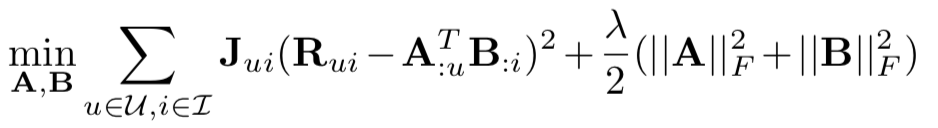
1. **Linear-Flow** from [Practical Linear Models for Large-Scale One-Class Collaborative Filtering](http://www.bkveton.com/docs/ijcai2016.pdf). Algorithm looks for factorized low-rank item-item similarity matrix (in some sense it is similar to [SLIM](https://ieeexplore.ieee.org/document/6137254))
* 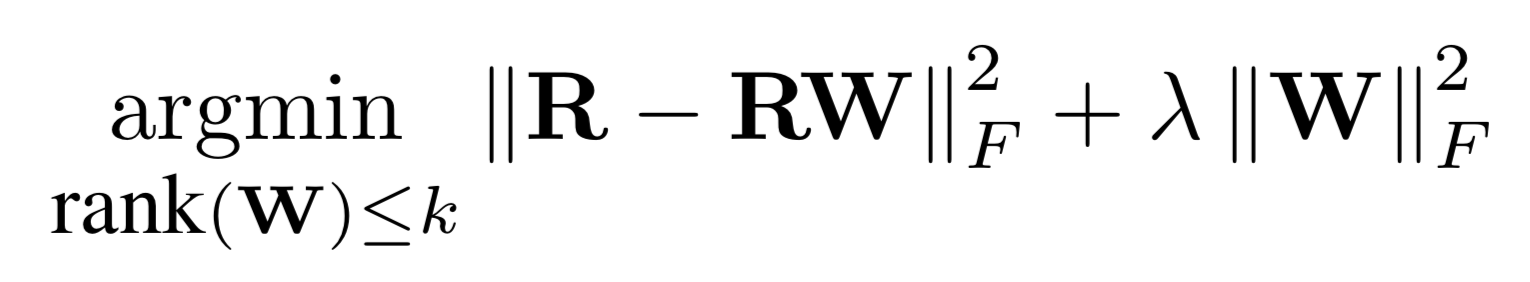
1. Fast **Truncated SVD** and **Truncated Soft-SVD** via Alternating Least Squares as described in [Matrix Completion and Low-Rank SVD via Fast Alternating Least Squares](http://arxiv.org/pdf/1410.2596). Works for both sparse and dense matrices. Works on [float](https://github.com/wrathematics/float) matrices as well! For certain problems may be even faster than [irlba](https://github.com/bwlewis/irlba) package.
* 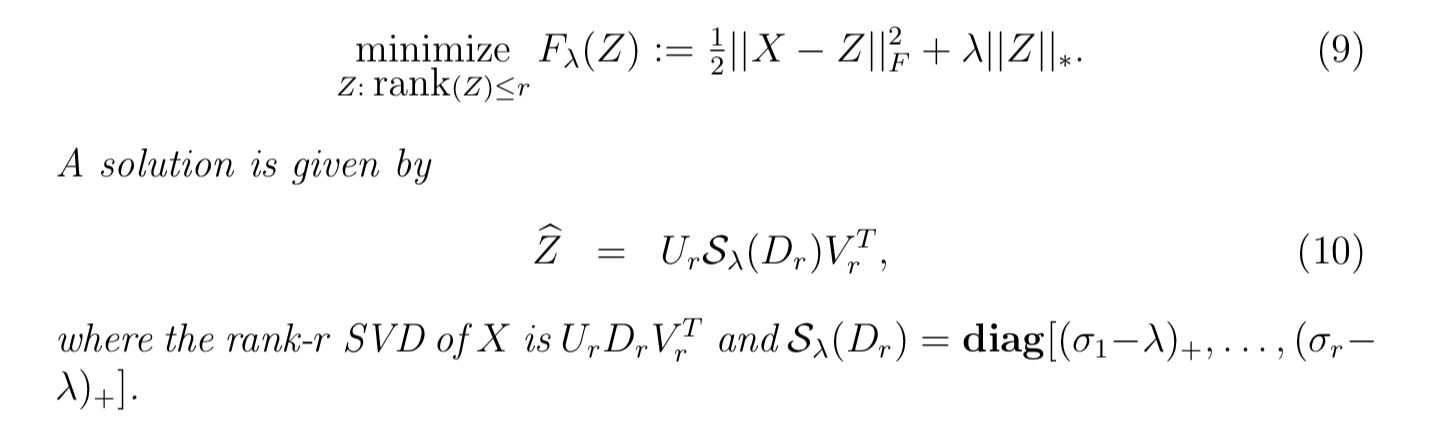
1. **Soft-Impute** via fast Alternating Least Squares as described in [Matrix Completion and Low-Rank SVD via Fast Alternating Least Squares](https://arxiv.org/pdf/1410.2596).
* 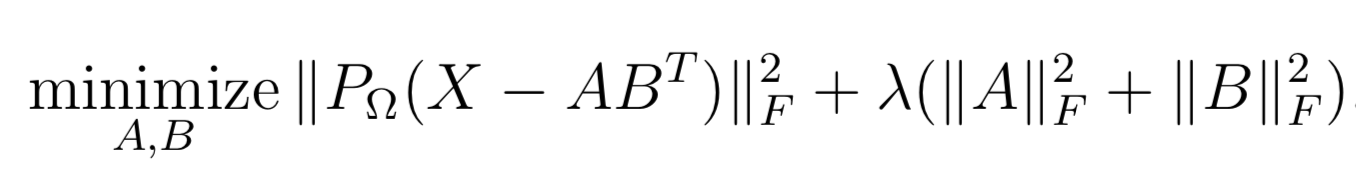
* with a solution in SVD form 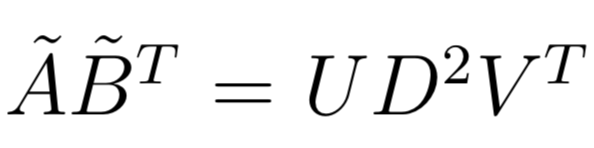
1. **GloVe** as described in [GloVe: Global Vectors for Word Representation](https://nlp.stanford.edu/pubs/glove.pdf).
* This is usually used to train word embeddings, but actually also very useful for recommender systems.
1. Matrix scaling as descibed in [EigenRec: Generalizing PureSVD for Effective and Efficient Top-N Recommendations](http://arxiv.org/pdf/1511.06033)
*********************
_Note: the optimized matrix operations which `rparse` used to offer have been moved to a [separate package](https://github.com/david-cortes/MatrixExtra)_
# Installation
Most of the algorithms benefit from OpenMP and many of them could utilize high-performance implementations of BLAS. If you want to make the maximum out of this package, please read the section below carefully.
It is recommended to:
1. Use high-performance BLAS (such as OpenBLAS, MKL, Apple Accelerate).
1. Add proper compiler optimizations in your `~/.R/Makevars`. For example on recent processors (with AVX support) and compiler with OpenMP support, the following lines could be a good option:
```
CXX11FLAGS += -O3 -march=native -fopenmp
CXXFLAGS += -O3 -march=native -fopenmp
```
### Mac OS
If you are on **Mac** follow the instructions at [https://mac.r-project.org/openmp/](https://mac.r-project.org/openmp/). After `clang` configuration, additionally put a `PKG_CXXFLAGS += -DARMA_USE_OPENMP` line in your `~/.R/Makevars`. After that, install `rsparse` in the usual way.
Also we recommend to use [vecLib](https://developer.apple.com/documentation/accelerate/veclib) - Apple’s implementations of BLAS.
```sh
ln -sf /System/Library/Frameworks/Accelerate.framework/Frameworks/vecLib.framework/Versions/Current/libBLAS.dylib /Library/Frameworks/R.framework/Resources/lib/libRblas.dylib
```
### Linux
On Linux, it's enough to just create this file if it doesn't exist (`~/.R/Makevars`).
If using OpenBLAS, it is highly recommended to use the `openmp` variant rather than the `pthreads` variant. On Linux, it is usually available as a separate package in typical distribution package managers (e.g. for Debian, it can be obtained by installing `libopenblas-openmp-dev`, which is not the default version), and if there are multiple BLASes installed, can be set as the default through the [Debian alternatives system](https://wiki.debian.org/DebianScience/LinearAlgebraLibraries) - which can also be used [for MKL](https://stackoverflow.com/a/49842944/5941695).
### Windows
By default, R for Windows comes with unoptimized BLAS and LAPACK libraries, and `rsparse` will prefer using Armadillo's replacements instead. In order to use BLAS, **install `rsparse` from source** (not from CRAN), removing the option `-DARMA_DONT_USE_BLAS` from `src/Makevars.win` and ideally adding `-march=native` (under `PKG_CXXFLAGS`). See [this tutorial](https://github.com/david-cortes/R-openblas-in-windows) for instructions on getting R for Windows to use OpenBLAS. Alternatively, Microsoft's MRAN distribution for Windows comes with MKL.
# Materials
**Note that syntax is these posts/slides is not up to date since package was under active development**
1. [Slides from DataFest Tbilisi(2017-11-16)](https://www.slideshare.net/DmitriySelivanov/matrix-factorizations-for-recommender-systems)
Here is example of `rsparse::WRMF` on [lastfm360k](https://www.upf.edu/web/mtg/lastfm360k) dataset in comparison with other good implementations:

# API
We follow [mlapi](https://github.com/dselivanov/mlapi) conventions.
# Release and configure
## Making release
Don't forget to add `DARMA_NO_DEBUG` to `PKG_CXXFLAGS` to skip bound checks (this has significant impact on NNLS solver)
```
PKG_CXXFLAGS = ... -DARMA_NO_DEBUG
```
## Configure
Generate configure:
```sh
autoconf configure.ac > configure && chmod +x configure
```