Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/dustin-decker/lognom
Simple script for processing streaming data from Redis using Apache Spark
https://github.com/dustin-decker/lognom
elasticsearch kafka redis spark
Last synced: 15 days ago
JSON representation
Simple script for processing streaming data from Redis using Apache Spark
- Host: GitHub
- URL: https://github.com/dustin-decker/lognom
- Owner: dustin-decker
- License: other
- Created: 2016-06-20T05:12:18.000Z (over 8 years ago)
- Default Branch: master
- Last Pushed: 2016-06-21T13:01:17.000Z (over 8 years ago)
- Last Synced: 2024-12-01T23:20:50.928Z (2 months ago)
- Topics: elasticsearch, kafka, redis, spark
- Language: Scala
- Homepage:
- Size: 50.8 KB
- Stars: 3
- Watchers: 3
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# LogNom
Provides wicked fast and scalable streaming log nomming via Apache Spark.
Spark is useful for simple processing and filtering distributed tasks to
complex data analysis.
data -> message broker -> Apache Spark nomming -> message broker -> elasticsearch

## Minimal requirements
- Apache Spark v1.6.1 (provided by maven)
Using a local cluster for now.
If you want to use an external Spark cluster (I didn't test this yet):
```
docker run -it --rm --volume "$(pwd)":/lognom -p 8088:8088 -p 8042:8042 -p 4040:4040 --name spark --hostname sandbox sequenceiq/spark:1.4.1 bash
```
- Scala v2.11.8 (provided by maven)
- Jedis v2.7 (provided by maven)
- spark-redis (packaged internally)
- Redis v3.2.1 (external)
- Elasticsearch-spark 2.3.2 (provided by maven)
- Elasticsearch 2.3.2 (external)
```
docker run --rm --name redis-logs redis
```
## Starting it
Clean and build packages:
```
mvn clean package -DskipTests
```
Start it up:
```
mvn exec:java -Dexec.mainClass="org.squishyspace.lognom.LogNom"
```
## Processing data
Make your changes in ./src/main/scala/org.squishyspace/LogNom.scala
### Redis/Kafka streams
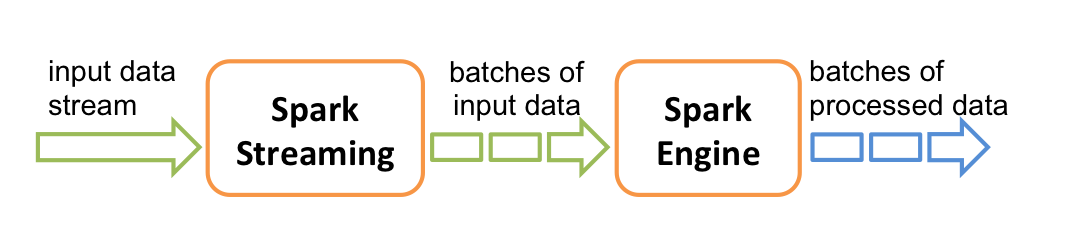
Redis/Kafka data comes into Apache Spark as a data stream (DStream).
A sliding window is used to batch up the stream in _n_ seconds batches.
Batch processing happens on the Spark cluster.
The DStream object is an RDD (Resilient Distributed Dataset) over time.
### Elasticsearch
Elasticsearch data is represented as a native RDD.
### Operations
Best to read [Spark's guide](http://spark.apache.org/docs/latest/programming-guide.html#rdd-operations), but i'll sum the main points up here.
RDDs support _transformations_ and _actions_. Transformations create a
new data set from an existing one, [changed in some way](http://spark.apache.org/docs/latest/programming-guide.html#transformations), and an action [does something with the changed data](http://spark.apache.org/docs/latest/programming-guide.html#actions). Transformations are instantaneously queued up and
computation does not actually begin across the cluster until an action is performed.