https://github.com/echo-devim/bugzilladatamining
This repository contains some datasets extracted from bugzilla, software to analyze them and some results.
https://github.com/echo-devim/bugzilladatamining
Last synced: over 1 year ago
JSON representation
This repository contains some datasets extracted from bugzilla, software to analyze them and some results.
- Host: GitHub
- URL: https://github.com/echo-devim/bugzilladatamining
- Owner: echo-devim
- Created: 2016-05-24T19:50:21.000Z (about 10 years ago)
- Default Branch: master
- Last Pushed: 2016-07-22T17:32:21.000Z (almost 10 years ago)
- Last Synced: 2025-02-10T08:12:26.973Z (over 1 year ago)
- Language: Java
- Size: 39.6 MB
- Stars: 2
- Watchers: 4
- Forks: 1
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# BugzillaAnalyzer
This is a project developed to analyze bugs reported with Bugzilla. I used Spark and HBase.
## Architecture
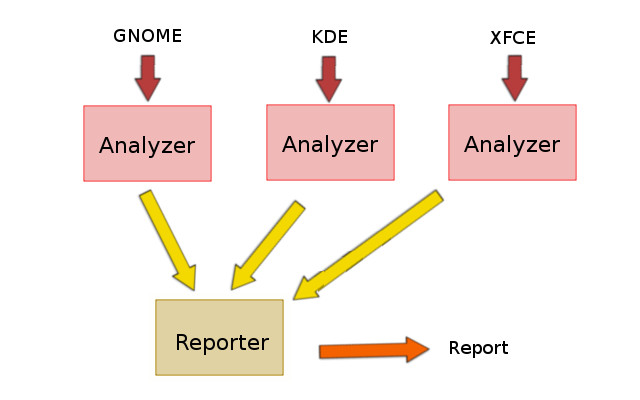
The system is formed by two parts.
#### Analyzer
This component takes a dataset of bugs as input and makes some analysis saving the results into HBase. Each row in the database is associated with a specific dataset and each column contains a result (e.g. number of total bugs, number of security bugs, etc.).
#### Reporter
This component takes all the partial results from HBase (i.e. from all the datasets) and creates a report with global analysis. The report will be saved on the HDFS in html format.
------------
If you have few really big datasets you can use the following architecture.

Otherwise if you have a lot of small datasets you can use this variant.
## Datasets
* gnome_all.csv.bz2 (uncompressed: 83.4 MB, bugs from 2002 to 2016, 555050 bugs )
* kde_all.csv.bz2 (uncompressed: 47.7 MB, bugs from 2002 to 2016, 339822 bugs )
* xfce_all.csv.bz2 (uncompressed: 1.3 MB, bugs from 2004 to 2016, 10198 bugs )
* names.txt (list of most common Italian's names).
I got all the information using:
> https://SITE.bugzilla.org/buglist.cgi?bug_status=UNCONFIRMED&bug_status=CONFIRMED&bug_status=ASSIGNED&bug_status=REOPENED&bug_status=RESOLVED&bug_status=NEEDSINFO&bug_status=VERIFIED&bug_status=CLOSED&chfieldfrom=2003-06-29&chfieldto=2004-05-31&limit=20000&query_format=advanced&ctype=csv&human=1&order=Last+Changed
Slicing the time window you can download all the bugs, the maximum number of bugs retrieved by a single query is 10000 (also if you set limit with a value greater than it).
CSV format:
*"Bug ID","Product","Component","Assignee","Status","Resolution","Summary","Changed"*
## Requirements
You need the following library to check the language used in the reports.
[language-detection library](https://github.com/echo-devim/language-detection)
You can use HDFS, but you can run the project also as standalone on your local machine. In this last case, use the original language detection library.
## Execution
1. Start HBase (e.g. `$ hbase-1.2.1/bin/start-hbase.sh`)
2. Run the Analyzer with `$ spark-1.6.1-bin-hadoop2.4/bin/spark-submit --class "main.Analyzer" --master local[*] --driver-class-path "$(/opt/shared/hbase-1.2.1/bin/hbase classpath):/opt/shared/libs/langdetect-hdfs.jar:/opt/shared/libs/jsonic-1.2.7.jar" /opt/shared/project/buganalyzer.jar file:///opt/shared/project/datasets/xfce_all.csv /opt/shared/project/languages/profiles`
3. Run the Reporter with `$ spark-1.6.1-bin-hadoop2.4/bin/spark-submit --class "main.Reporter" --master local[*] --driver-class-path "$(/opt/shared/hbase-1.2.1/bin/hbase classpath):/opt/shared/libs/langdetect-hdfs.jar:/opt/shared/libs/jsonic-1.2.7.jar" /opt/shared/project/buganalyzer.jar hdfs://172.97.0.9:9000/user/root/output`