https://github.com/eellak/nlpbuddy
A text analysis application for performing common NLP tasks through a web dashboard interface and an API
https://github.com/eellak/nlpbuddy
fasttext gensim natural-language-processing spacy text-analysis text-classification
Last synced: over 1 year ago
JSON representation
A text analysis application for performing common NLP tasks through a web dashboard interface and an API
- Host: GitHub
- URL: https://github.com/eellak/nlpbuddy
- Owner: eellak
- License: agpl-3.0
- Created: 2018-07-27T10:23:42.000Z (almost 8 years ago)
- Default Branch: master
- Last Pushed: 2019-01-18T18:06:35.000Z (over 7 years ago)
- Last Synced: 2025-04-12T06:03:33.392Z (over 1 year ago)
- Topics: fasttext, gensim, natural-language-processing, spacy, text-analysis, text-classification
- Language: HTML
- Homepage: http://www.nlpbuddy.io/
- Size: 929 KB
- Stars: 125
- Watchers: 19
- Forks: 28
- Open Issues: 5
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# NLPBuddy - Open Source Text Analysis Tool
## About the project
NLPBuddy is a text analysis application for performing common NLP tasks through a web dashboard interface and an API.
It leverages [Spacy](https://spacy.io) for the NLP tasks plus [Gensim's](https://github.com/RaRe-Technologies/gensim) implementation of the TextRank algorithm for text summarization.
It supports texts in the following languages: Greek, English, German, Spanish, Portoguese, French, Italian and Dutch. Language identification is performed automatically through [langid](https://github.com/saffsd/langid.py)
Tasks include:
1. Text tokenization
2. Sentence splitting (lemmatized sentences too)
3. Part of Speech tags identification (verbs, nouns etc)
4. Named Entity Recognition (Location, Person, Organisation etc)
5. Text summarization (using TextRank algorithm, implemented by Gensim)
6. Keywords extraction
7. Language identification
8. For the Greek language, Categorization of text
Text can either be provided or imported after specifying a url - we use library [python readability](https://github.com/buriy/python-readability) for this plus [BeautifulSoup4](https://www.crummy.com/software/BeautifulSoup/)
The Greek classifier is built with [FastText](https://fasttext.cc) and is trained in 20.000 articles labeled in these categories.
## Demo
A working demo can be found on [http://www.nlpbuddy.io/](http://www.nlpbuddy.io/)
## Usage
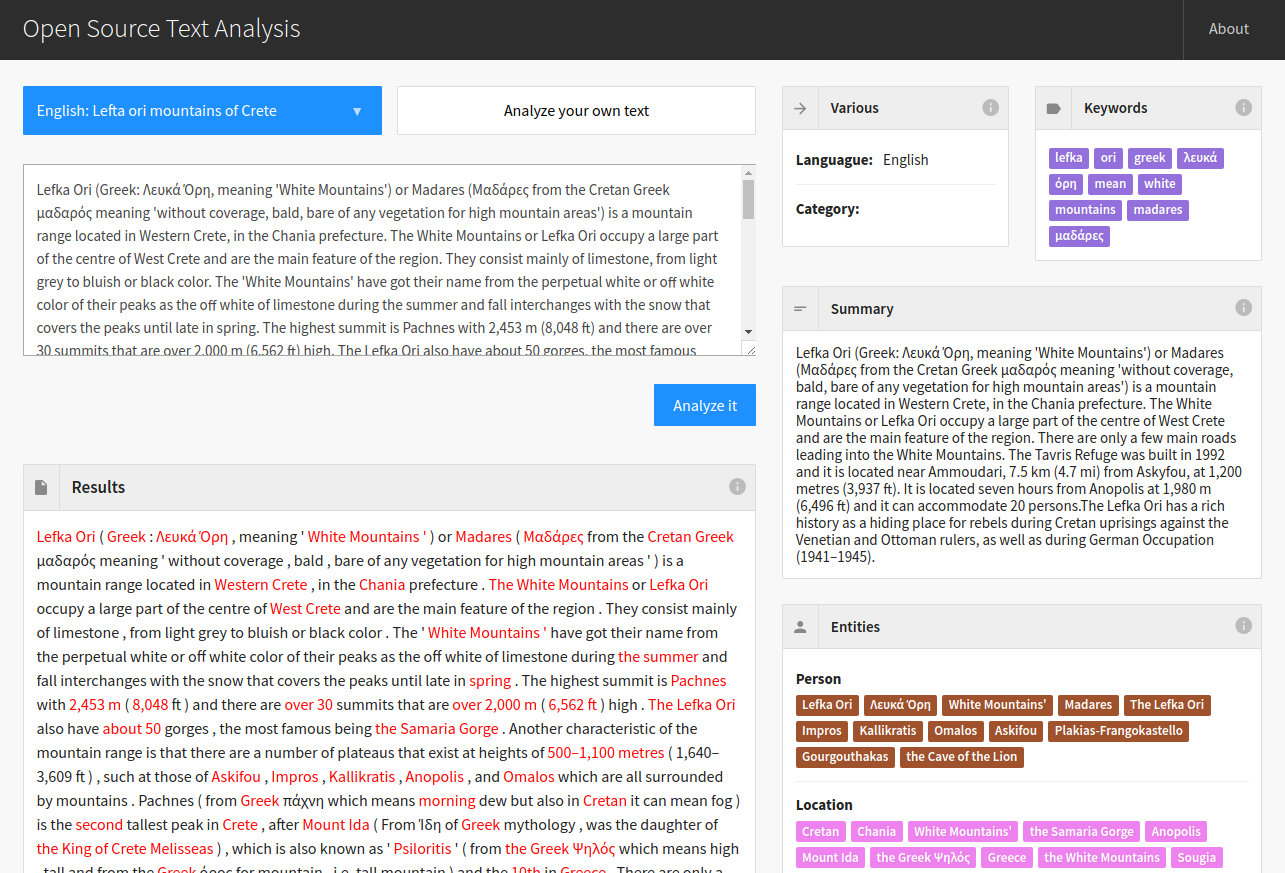
Enter text and hit 'Analyze it',
## API Usage
[https://github.com/eellak/text-analysis/wiki/API-usage](https://github.com/eellak/text-analysis/wiki/API-usage)
## Installation
Find development and deployment instructions here: https://github.com/eellak/text-analysis/wiki/Install
## License
The code is provided under the GNU AGPL v3.0 License.