https://github.com/ehewes/pyframe
PyFrame splits GIFs into equal time windows and picks the frame with the highest motion delta from each one. This way you get good scene coverage and catch peak frames without sending every frame to AWS Rekognition cuts costs by ~93% with minimal accuracy loss.
https://github.com/ehewes/pyframe
aws aws-image-moderation aws-rek huggingface huggingface-transformers image-moderation moderation opencv opencv-python pillow python
Last synced: about 1 month ago
JSON representation
PyFrame splits GIFs into equal time windows and picks the frame with the highest motion delta from each one. This way you get good scene coverage and catch peak frames without sending every frame to AWS Rekognition cuts costs by ~93% with minimal accuracy loss.
- Host: GitHub
- URL: https://github.com/ehewes/pyframe
- Owner: ehewes
- License: mit
- Created: 2026-02-08T00:02:43.000Z (5 months ago)
- Default Branch: main
- Last Pushed: 2026-06-01T00:07:48.000Z (about 1 month ago)
- Last Synced: 2026-06-01T02:00:20.467Z (about 1 month ago)
- Topics: aws, aws-image-moderation, aws-rek, huggingface, huggingface-transformers, image-moderation, moderation, opencv, opencv-python, pillow, python
- Language: Python
- Homepage: https://ellishewes.com/blogs/PyFrame
- Size: 501 KB
- Stars: 15
- Watchers: 0
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# PyFrame
NSFW moderation for GIFs, videos, and images using local [HuggingFace](https://huggingface.co) models and/or [AWS Rekognition](https://aws.amazon.com/rekognition/content-moderation/).
PyFrame uses **temporal segmentation** to avoid moderating every frame: it splits an animation into equal time buckets and extracts the most significant frame from each, capturing diverse scene coverage at a fraction of the cost. It also offers an optional **two-stage cascade** (`--prescreen`): a free local model soft-screens densely, and only the flagged time windows get escalated to the precise (e.g. AWS) backend. See the [pipeline diagram](#pipeline) for a visual of the approach.
## Install
```bash
pip install "pyframe-gif-video-image-moderation[local]" # free local HuggingFace backend
pip install "pyframe-gif-video-image-moderation[aws]" # AWS Rekognition backend
pip install "pyframe-gif-video-image-moderation[all]" # everything (local + aws + video)
```
Or with [uv](https://docs.astral.sh/uv/):
```bash
uv add "pyframe-gif-video-image-moderation[local]"
# or, ad-hoc: uv pip install "pyframe-gif-video-image-moderation[local]"
```
The base install is intentionally light (just `opencv-python-headless`, `numpy`, `Pillow`); the heavy backends (`boto3`, `transformers`/`torch`, `moviepy`) are optional extras you only pull in if you use them.
## Python API
`Pipe` is the high-level facade: build it, call `run()`.
```python
from pyframe import Pipe
result = Pipe("clip.gif", backend="local").run()
print(result.verdict) # clean
print(result.is_nsfw) # False
```
Swap the backend, or turn on the two-pass cascade:
```python
Pipe("clip.gif", backend="aws").run() # AWS Rekognition
Pipe("clip.gif", backend="aws", prescreen=True).run() # local screens, AWS confirms
```
### Tuning the two-pass
Every knob is a `Pipe` param with a sensible default:
```python
Pipe(
"clip.gif",
backend="aws", # precise backend used on escalation
prescreen=True, # two-pass cascade on
escalate_threshold=0.15, # escalate on the faintest local signal (lower = more recall, more cost)
max_escalations=2, # hard cap on AWS calls per file
frames_per_batch=2, # frames merged into each grid sent to AWS
screen_fps=2.0, # soft-screen sample rate
min_confidence=0.5, # NSFW threshold (defaults to the backend's recall-safe value)
).run()
```
## CLI
The same pipeline as a command, no script to edit:
```bash
pyframe clip.gif # auto backend, prints a verdict
pyframe clip.gif --backend local # free local model
pyframe clip.gif --backend aws --region us-east-1 # AWS Rekognition
pyframe clip.gif --prescreen --backend aws # cascade: local gate then AWS
pyframe a.gif b.gif c.png --json # batch, machine-readable
```
Exit code: `0` clean, `1` NSFW (per `--fail-on`), `2` bad input, `3` backend not installed, so it drops straight into a shell gate: `pyframe upload.gif || reject`. Equivalent module form: `python -m pyframe clip.gif`.
### Options
| Flag | Default | Meaning |
|------|---------|---------|
| `--backend` | `auto` | `local`, `aws`, or `local:` |
| `--model` | model default | HuggingFace model id (local backend) |
| `--region` | `us-east-1` | AWS region (aws backend) |
| `--max-frames` | `10` | frames to extract from a GIF/video |
| `--min-confidence` | backend default | NSFW threshold (0-1); `0.5` local, `0.8` aws |
| `--sampler` | `motion` | `motion` (bucketing) or `dense` (uniform) |
| `--prescreen` | off | enable the two-stage cascade |
| `--escalate-threshold` | `0.15` | cascade gate (low = recall-safe) |
| `--max-escalations` | `2` | hard cap on precise (AWS) calls per file |
| `--screen-fps` | `2.0` | soft-screen sample rate |
| `--use-merged` / `--frames-per-batch` | off / `2` | merge frames into a grid before classifying |
| `--save-frames DIR` | off | write the classified frames to `DIR` |
| `--json` / `--fail-on` | off / `nsfw` | output format / exit-code policy |
## How it works
- `Pipe` - facade you construct (mirrors the old main.py flow)
- `Scanner` - engine: single-pass, or the two-stage cascade
- `Backend` - local (HuggingFace) or aws (Rekognition), normalized results
- `Sampler` - motion bucketing, dense uniform, or suspicion
**Single-pass** (default): extract `max_frames` via motion bucketing, then classify each with one backend.
**Cascade** (`--prescreen`): a free local model densely soft-screens the whole clip; if any frame scores above `--escalate-threshold` (a deliberately *low* recall gate), the most-suspicious frames are merged into grids and sent to the precise backend, capped at `--max-escalations` calls per file (default 2) so a heavily-flagged clip can never cost more than a single-pass scan. Clean media short-circuits to ~$0 and never hits the expensive backend. Because the soft-screen looks at *content* (not motion), it won't discard a unique suspicious frame the way motion bucketing can, and it fails *open*: a decode/inference error escalates rather than silently clearing.
## Cost
AWS Rekognition bills ~$1.00 / 1,000 images. A 150-frame GIF costs $0.15 to moderate every frame; PyFrame's 10-bucket extraction drops that to ~$0.01 (a ~93% reduction). With `--prescreen`, clean clips cost $0 (local only) and flagged clips incur at most `--max-escalations` AWS calls (default 2), so the cascade never costs more than a single-pass scan.
> Tune the cascade on labeled data before relying on it: the local gate's recall bounds the system's recall. Keep `--escalate-threshold` low (catch anything *potentially* NSFW) and sample densely enough (`--screen-fps`) that brief events don't fall between samples.
## Pipeline
A 150-frame GIF flows through temporal segmentation down to a handful of extracted frames, optionally merged into grids, then sent to the backend:
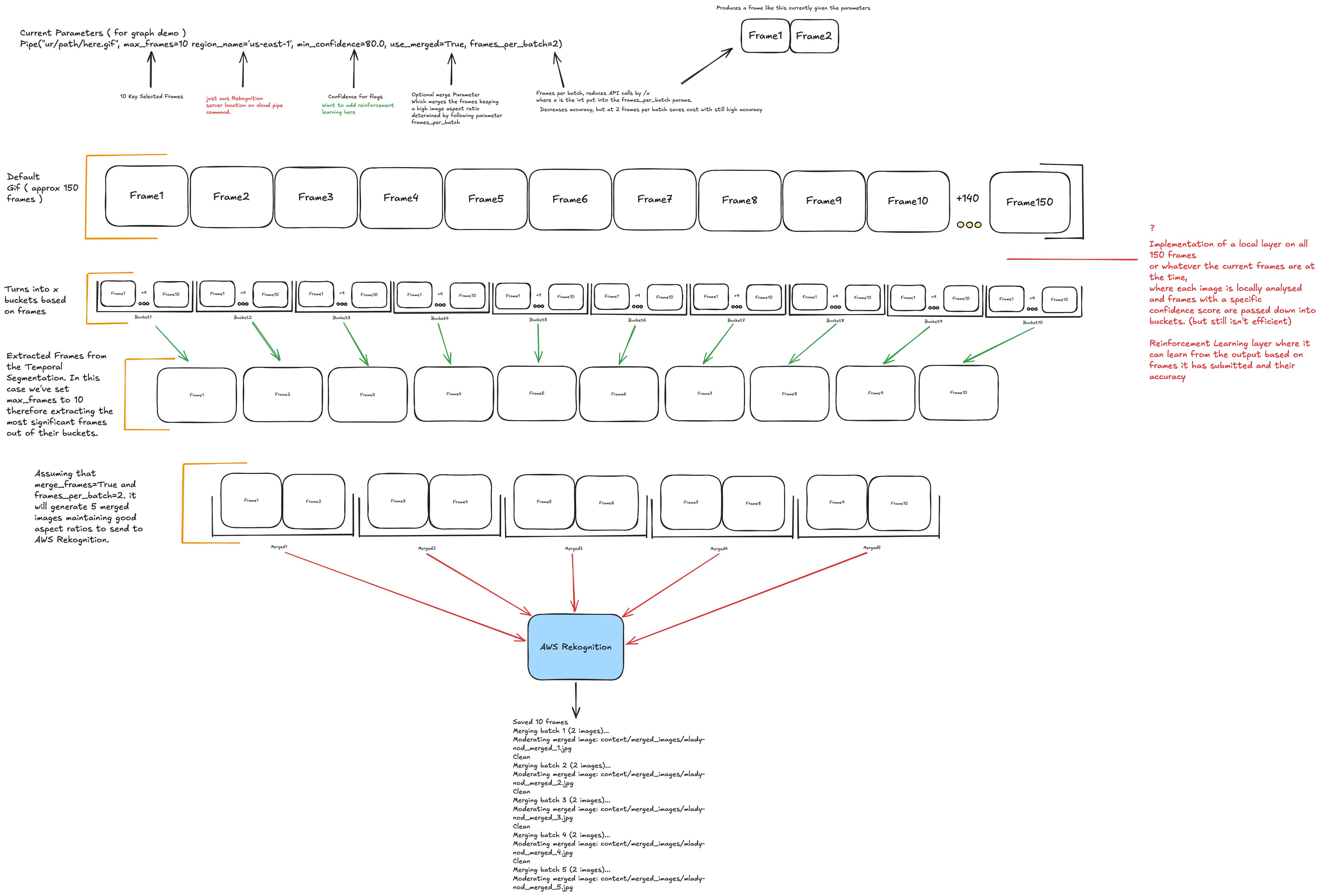
## Notes
- The `aws` backend needs credentials: install with `pip install "pyframe-gif-video-image-moderation[aws]"`, then run `aws configure` (or set `AWS_ACCESS_KEY_ID`, `AWS_SECRET_ACCESS_KEY`, and `AWS_DEFAULT_REGION`).
- `[video]` (video to GIF) needs `moviepy`, which requires a system **ffmpeg** (`brew install ffmpeg`).
- HuggingFace **model weights** have their own licenses, separate from this package's MIT license.
## Development
```bash
uv pip install -e ".[dev]" # or: pip install -e ".[dev]"
pytest
python -m build # or: uv build
twine check dist/* # or: uv publish (to PyPI)
```