https://github.com/emalagoli92/gcvit-tensorflow
TensorFlow 2.X reimplementation of Global Context Vision Transformers, Ali Hatamizadeh, Hongxu (Danny) Yin, Jan Kautz Pavlo Molchanov.
https://github.com/emalagoli92/gcvit-tensorflow
computer-vision deep-learning image-classification python pytorch tensorflow transformers
Last synced: over 1 year ago
JSON representation
TensorFlow 2.X reimplementation of Global Context Vision Transformers, Ali Hatamizadeh, Hongxu (Danny) Yin, Jan Kautz Pavlo Molchanov.
- Host: GitHub
- URL: https://github.com/emalagoli92/gcvit-tensorflow
- Owner: EMalagoli92
- License: mit
- Created: 2022-08-28T14:40:22.000Z (almost 4 years ago)
- Default Branch: main
- Last Pushed: 2023-01-25T17:19:13.000Z (over 3 years ago)
- Last Synced: 2025-04-06T18:51:10.727Z (over 1 year ago)
- Topics: computer-vision, deep-learning, image-classification, python, pytorch, tensorflow, transformers
- Language: Python
- Homepage:
- Size: 338 KB
- Stars: 7
- Watchers: 1
- Forks: 1
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README



# GCViT-TensorFlow
TensorFlow 2.X reimplementation of [Global Context Vision Transformers](https://arxiv.org/abs/2206.09959) [Ali Hatamizadeh](http://web.cs.ucla.edu/~ahatamiz),
[Hongxu (Danny) Yin](https://scholar.princeton.edu/hongxu), [Jan Kautz](https://jankautz.com/) [Pavlo Molchanov](https://www.pmolchanov.com/).
- Exact TensorFlow reimplementation of official PyTorch repo, including `timm` modules used by authors, preserving models and layers structure.
- ImageNet pretrained weights ported from PyTorch official implementation.
## Table of contents
- [Abstract](#abstract)
- [Results](#results)
- [Installation](#installation)
- [Usage](#usage)
- [Acknowledgement](#acknowledgement)
- [Citations](#citations)
- [License](#license)
## Abstract
*GC ViT achieves state-of-the-art results across image classification, object detection and semantic segmentation tasks. On ImageNet-1K dataset for classification, the tiny, small and base variants of GC ViT with `28M`, `51M` and `90M`, surpass comparably-sized prior art such as CNN-based ConvNeXt and ViT-based Swin Transformer by a large margin. Pre-trained GC ViT backbones in downstream tasks of object detection, instance segmentation,
and semantic segmentation using MS COCO and ADE20K datasets outperform prior work consistently, sometimes by large margins.*
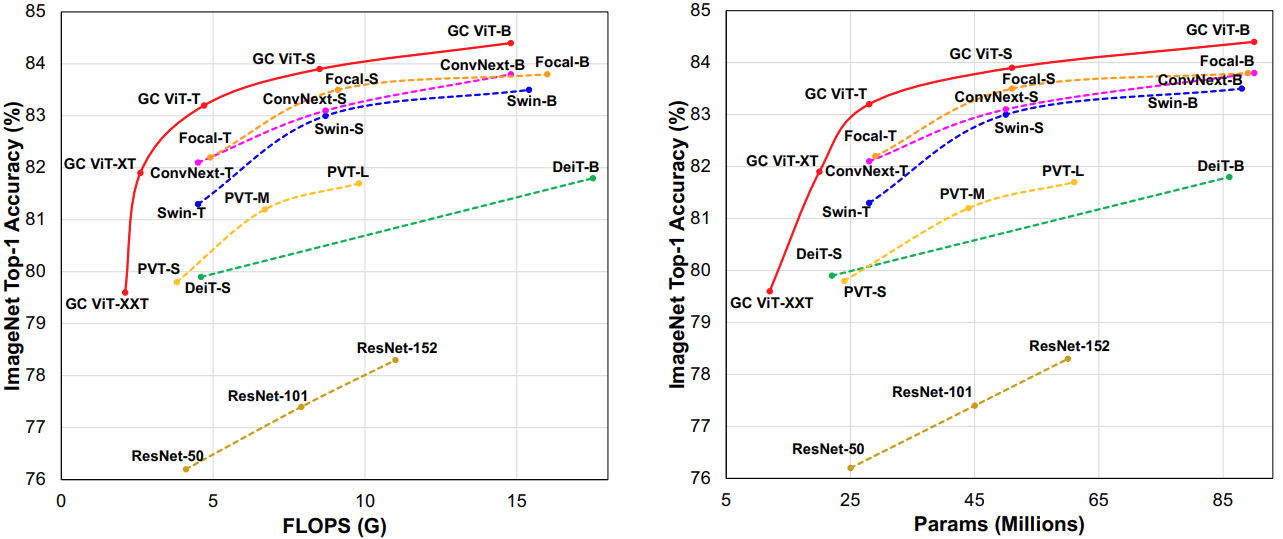
Top-1 accuracy vs. model FLOPs/parameter size on ImageNet-1K dataset. GC ViT achieves
new SOTA benchmarks for different model sizes as well as FLOPs, outperforming competing approaches by a
significant margin.

Architecture of the Global Context ViT. The authors use alternating blocks of local and global
context self attention layers in each stage of the architecture.
## Results
TensorFlow implementation and ImageNet ported weights have been compared to the official PyTorch implementation on [ImageNet-V2](https://www.tensorflow.org/datasets/catalog/imagenet_v2) test set.
| Configuration | Top-1 (Original) | Top-1 (Ported) | Top-5 (Original) | Top-5 (Ported) | #Params
| ------------- | ------------- | ------------- | ------------- | ------------- | ------------- |
| GCViT-XXTiny | 68.79 | 68.73 | 88.52 | 88.47 | 12M |
| GCViT-XTiny | 70.97 | 71 | 89.8 | 89.79 | 20M |
| GCViT-Tiny | 72.93 | 72.9| 90.7 | 90.7 | 28M |
| GCViT-Small | 73.46 | 73.5 | 91.14 | 91.08 | 51M |
| GCViT-Base | 74.13 | 74.16 | 91.66 | 91.69 | 90M |
Mean metrics difference: `3e-4`.
## Installation
- Install from PyPI
```
pip install gcvit-tensorflow
```
- Install from Github
```
pip install git+https://github.com/EMalagoli92/GCViT-TensorFlow
```
- Clone the repo and install necessary packages
```
git clone https://github.com/EMalagoli92/GCViT-TensorFlow.git
pip install -r requirements.txt
```
Tested on *Ubuntu 20.04.4 LTS x86_64*, *python 3.9.7*.
## Usage
- Define a custom GCViT configuration.
```python
from gcvit_tensorflow import GCViT
# Define a custom GCViT configuration
model = GCViT(
depths=[2, 2, 6, 2],
num_heads=[2, 4, 8, 16],
window_size=[7, 7, 14, 7],
dim=64,
resolution=224,
in_chans=3,
mlp_ratio=3,
drop_path_rate=0.2,
data_format="channels_last",
num_classes=100,
classifier_activation="softmax",
)
```
- Use a predefined GCViT configuration.
```python
from gcvit_tensorflow import GCViT
model = GCViT(configuration="xxtiny")
model.build((None, 224, 224, 3))
print(model.summary())
```
```
Model: "xxtiny"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
patch_embed (PatchEmbed) (None, 56, 56, 64) 45632
pos_drop (Dropout) (None, 56, 56, 64) 0
levels/0 (GCViTLayer) (None, 28, 28, 128) 185766
levels/1 (GCViTLayer) (None, 14, 14, 256) 693258
levels/2 (GCViTLayer) (None, 7, 7, 512) 5401104
levels/3 (GCViTLayer) (None, 7, 7, 512) 5400546
norm (LayerNorm_) (None, 7, 7, 512) 1024
avgpool (AdaptiveAveragePoo (None, 512, 1, 1) 0
ling2D)
head (Linear_) (None, 1000) 513000
=================================================================
Total params: 12,240,330
Trainable params: 11,995,428
Non-trainable params: 244,902
_________________________________________________________________
```
- Train from scratch the model.
```python
# Example
model.compile(
optimizer="sgd",
loss="sparse_categorical_crossentropy",
metrics=["accuracy", "sparse_top_k_categorical_accuracy"],
)
model.fit(x, y)
```
- Use ported ImageNet pretrained weights
```python
# Example
from gcvit_tensorflow import GCViT
model = GCViT(configuration="base", pretrained=True, classifier_activation="softmax")
y_pred = model(image)
```
## Acknowledgement
- [GCViT](https://github.com/nvlabs/gcvit) (Official PyTorch implementation)
- [gcvit_tf](https://github.com/awsaf49/gcvit-tf)
- [tfgcvit](https://github.com/shkarupa-alex/tfgcvit)
## Citations
```bibtex
@article{hatamizadeh2022global,
title={Global Context Vision Transformers},
author={Hatamizadeh, Ali and Yin, Hongxu and Kautz, Jan and Molchanov, Pavlo},
journal={arXiv preprint arXiv:2206.09959},
year={2022}
}
```
## License
This work is made available under the [MIT License](https://github.com/EMalagoli92/GCViT-TensorFlow/blob/main/LICENSE)
The pre-trained weights are shared under [CC-BY-NC-SA-4.0](https://creativecommons.org/licenses/by-nc-sa/4.0/)