Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/eugeneyan/visualizing-finetunes
https://github.com/eugeneyan/visualizing-finetunes
Last synced: about 12 hours ago
JSON representation
- Host: GitHub
- URL: https://github.com/eugeneyan/visualizing-finetunes
- Owner: eugeneyan
- License: apache-2.0
- Created: 2023-11-05T22:22:34.000Z (about 1 year ago)
- Default Branch: main
- Last Pushed: 2024-05-27T18:01:00.000Z (6 months ago)
- Last Synced: 2024-05-28T03:23:21.680Z (5 months ago)
- Language: Jupyter Notebook
- Size: 2.45 MB
- Stars: 21
- Watchers: 2
- Forks: 3
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# Visualizing Finetunes
Accompanying repo for [Out-of-Domain Finetuning to Bootstrap Hallucination Detection](https://eugeneyan.com/writing/finetuning/)
---
In this repo, we demonstrate finetuning a model to detect hallucination summaries on the [Factual Inconsistency Benchmark (FIB)](https://arxiv.org/abs/2211.08412v1). The benchmark is hard, and using a non-finetuned model achieves ROC AUC and PR AUC of 0.56. Also, the probability distributions between hallucinating and non-hallucinating summaries is inseparable, making it unusable in production (right below).
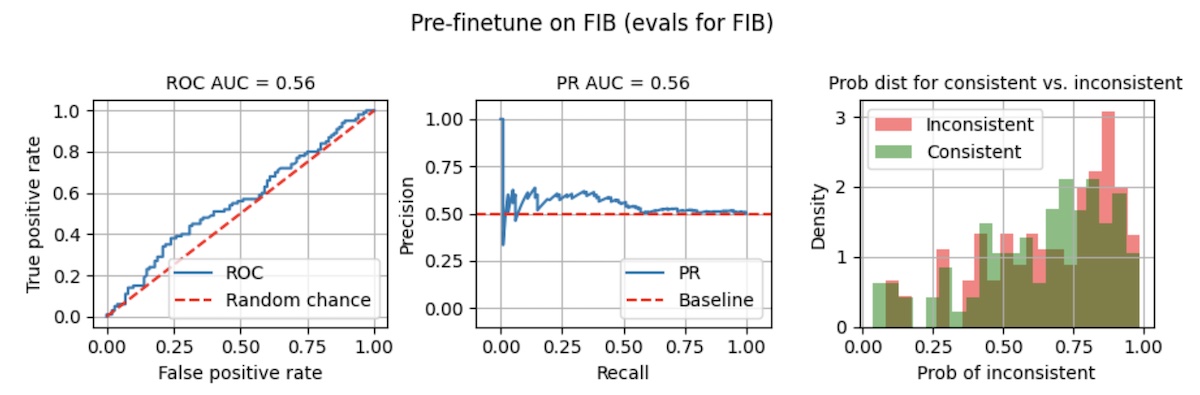
After finetuning it for 10 epochs ([notebook](https://github.com/eugeneyan/visualizing-finetunes/blob/main/2_ft_fib.ipynb)), ROC AUC and PR AUC improved slightly to 0.68 - 0.69. However, the separation of probabilities is still poor. Taking a threshold of 0.8, recall is a measly 0.02 while precision is 0.67.
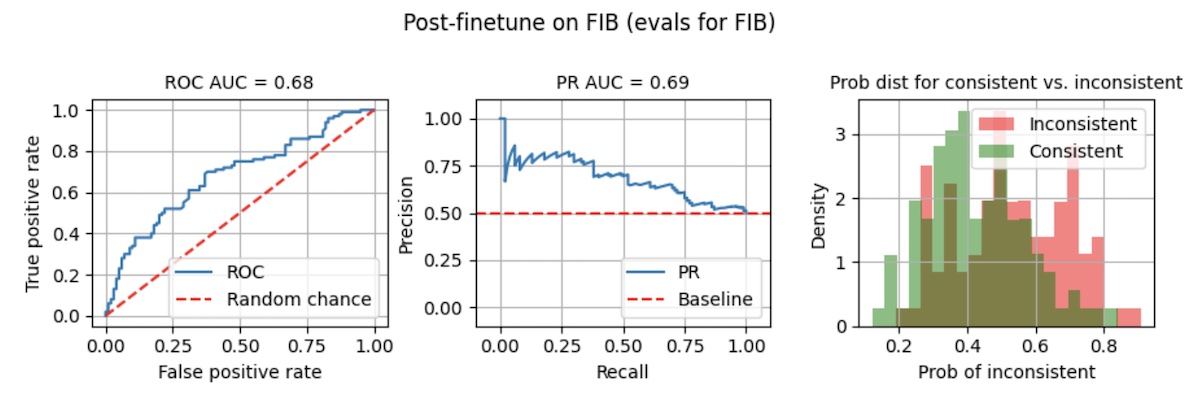
Now, let's start from scratch and pre-finetune in on another dataset, the [Unified Summarization Benchmark (USB)](https://arxiv.org/abs/2305.14296). While the FIB is based on _news articles_, and USB is based on _Wikipedia_, let's try it and see what happens.
We finetune for 10 epochs on USB, followed by 10 epochs on FIB ([notebook](https://github.com/eugeneyan/visualizing-finetunes/blob/main/3_ft_usb_then_fib.ipynb)). When we run evals on FIB, we see that the model now achieves ROC AUC and PR AUC of 0.84 - 0.85, and the probability distribution is well separated. At the same threshold of 0.8, we’ve increased recall from 0.02 to 0.50 (25x) and precision from 0.67 to 0.91 (+35%).
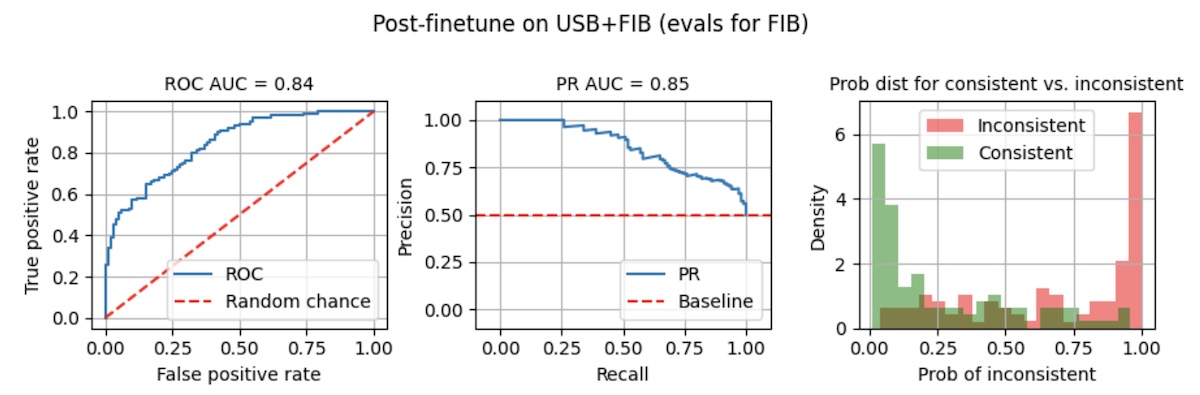
**Takeaway**: Pre-finetuning on _Wikipedia_ summaries improved hallucination detection in _news_ summaries, even though the former is out-of-domain.
In other words, we bootstrapped on Wikipedia summaries to identify factually inconsistent news summaries. Thus, we may not need to collect as much finetuning data for our tasks if there are open-source, permissive-use datasets that are somewhat related.
See more details on the NLI model, how we update it for hallucination detection, and examples of the FIB and USB data in [this write-up](https://eugeneyan.com/writing/finetuning/).