https://github.com/evolvinglmms-lab/aero-1
https://github.com/evolvinglmms-lab/aero-1
Last synced: 12 months ago
JSON representation
- Host: GitHub
- URL: https://github.com/evolvinglmms-lab/aero-1
- Owner: EvolvingLMMs-Lab
- License: apache-2.0
- Created: 2025-04-29T13:02:00.000Z (about 1 year ago)
- Default Branch: main
- Last Pushed: 2025-05-04T03:00:17.000Z (about 1 year ago)
- Last Synced: 2025-07-04T17:16:37.332Z (12 months ago)
- Language: Python
- Size: 83 KB
- Stars: 72
- Watchers: 5
- Forks: 6
- Open Issues: 3
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
## What is Aero-1-Audio?
[Github](https://github.com/EvolvingLMMs-Lab/Aero-1/blob/main/README.md) | [Playground](https://huggingface.co/spaces/lmms-lab/Aero-1-Audio-Demo) | [Models](https://huggingface.co/lmms-lab/Aero-1-Audio-1.5B) | [Evaluation Results](https://github.com/EvolvingLMMs-Lab/lmms-eval/pull/658) | [Cookbook](https://www.lmms-lab.com/posts/lmms-lab-docs/aero_audio/)
`Aero-1-Audio` is a compact yet powerful audio-language model designed for a wide range of audio tasks, including automatic speech recognition (ASR), audio understanding, and instruction following. It is part of the `Aero-1 series`, the first generation of lightweight multimodal models developed by `LMMs-Lab`, with future expansions planned across additional modalities.
1. Built upon Qwen-2.5-1.5B, Aero-1-Audio achieves competitive performance on multiple audio benchmarks while maintaining exceptional parameter efficiency. **It performs on par with or even surpasses larger models such as Whisper, Qwen-2-Audio, and Phi-4-Multimodal**, as well as commercial services like ElevenLabs and Scribe.
2. **Trained in just one day** on 16 H100 GPUs using 50K hours of high-quality, filtered audio data, Aero-1-Audio demonstrates that audio model training can be highly sample-efficient when using curated datasets.
3. Aero-1-Audio handles **continuous audio inputs of up to 15 minutes without splitting**, delivering accurate ASR and understanding—a capability that remains challenging for many existing models.
## ASR & Audio Understanding Performance
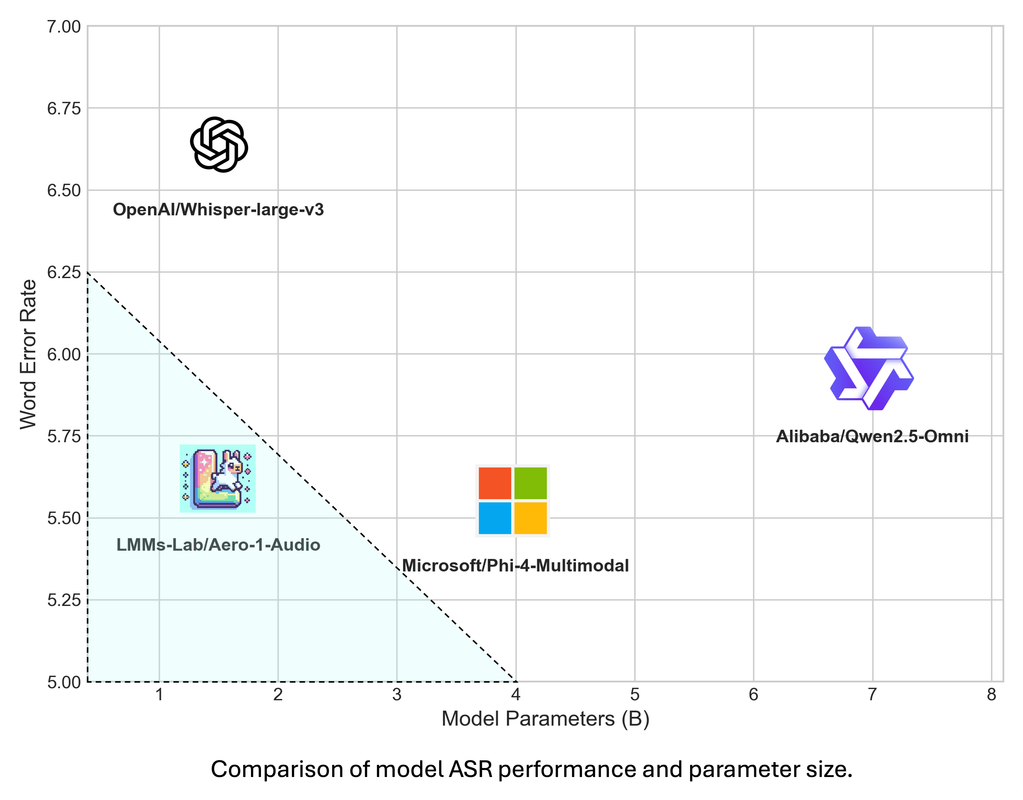
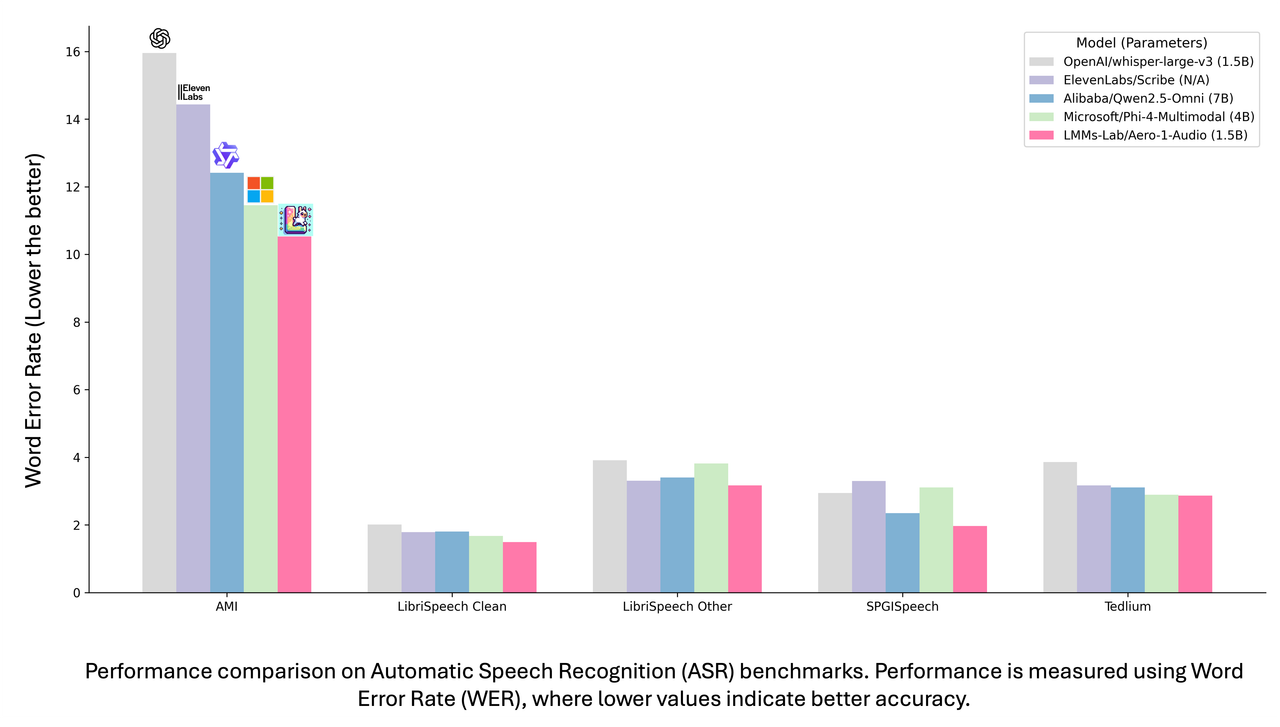
We evaluate our model performance on multiple dimensions and different benchmarks. Let's first take a look at its overall performance compared with other models
[](https://postimg.cc/ZC077jhK)
[](https://postimg.cc/TKgcF4NG)
Our model achieves a balance between performance and parameter efficiency. We evaluate it across multiple ASR and audio understanding benchmarks. On ASR tasks, our model attains the lowest WER scores on datasets such as AMI, LibriSpeech, and SPGISpeech. It also demonstrates strong audio understanding capabilities on various comprehension benchmarks. As illustrated in the plotted graph, our model falls within the highlighted triangular region that represents an optimal trade-off between parameter efficiency and performance.
## Data Distribution
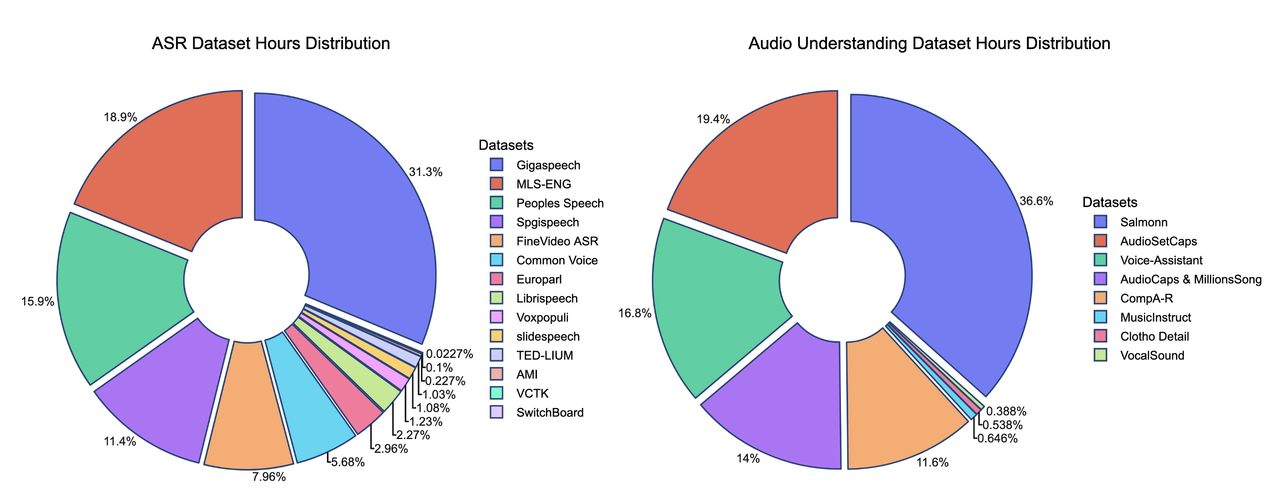
We present the contributions of our data mixture here. Our SFT data mixture includes over 20 publicly available datasets, and comparisons with other models highlight the data's lightweight nature.
[](https://postimg.cc/c6CB0HkF)
[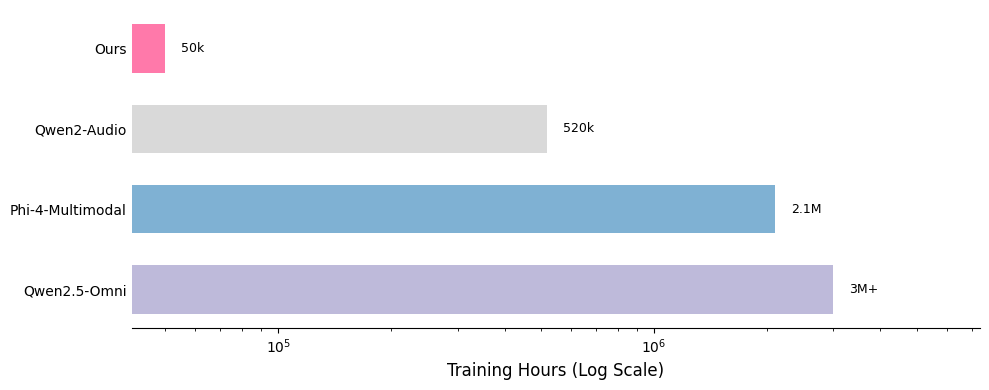](https://postimg.cc/XBrf8HBR)
*The hours of some training datasets are estimated and may not be fully accurate*
One of the key strengths of our training recipe lies in the quality and quantity of our data. Our training dataset consists of approximately 5 billion tokens, corresponding to around 50,000 hours of audio. Compared to models such as Qwen-Omni and Phi-4, our dataset is over 100 times smaller, yet our model achieves competitive performance. All data is sourced from publicly available open-source datasets, highlighting the sample efficiency of our training approach. A detailed breakdown of our data distribution is provided below, along with comparisons to other models.
## What's Insightful
In this release, our primary focus is on developing an audio model capable of handling multiple audio tasks. The following examples showcase its core abilities across tasks such as audio understanding and speech recognition. Most notably, we highlight the model's capability to perform long-form ASR, as demonstrated in the example below.
### Long ASR
[Example Youtube](https://www.youtube.com/embed/uYyoEB6Xu58)
A common approach for current long-form ASR tasks is to split the audio into smaller, processable chunks and perform ASR on each segment individually. However, with the advancement of large language models (LLMs), long-context understanding has become increasingly important. We argue that a model's ability to process long audio sequences continuously is essential for effective audio understanding and should be considered a critical capability. To demonstrate this, we set up a simple use case using examples from an NVIDIA conference and calculate the WER with respect to the auto-generated YouTube subtitles.
[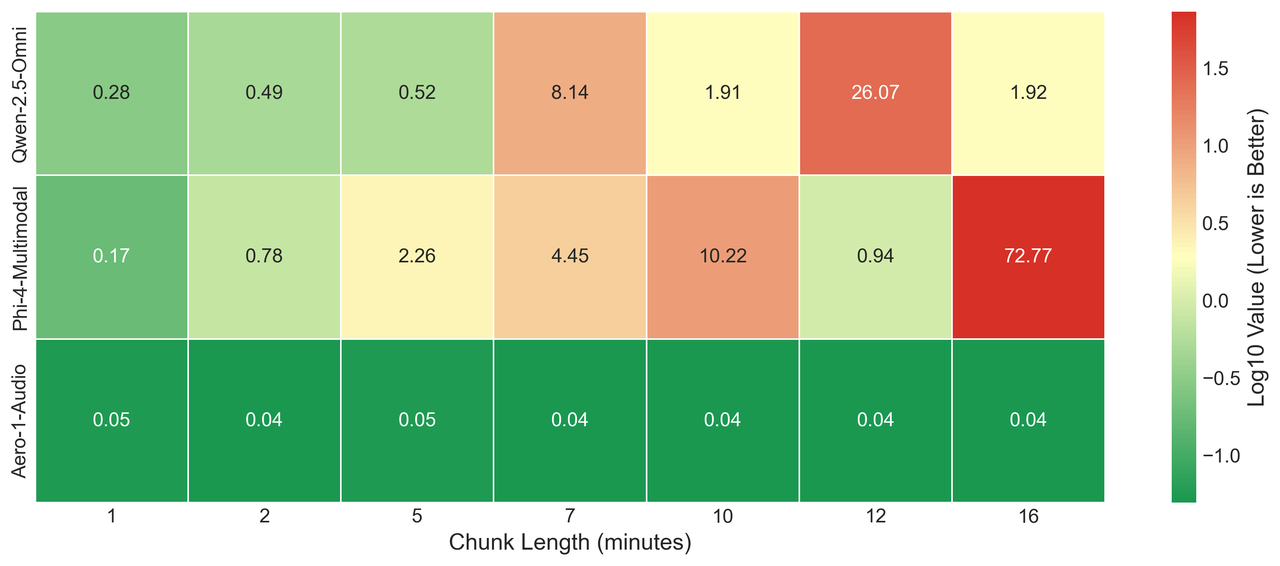](https://postimg.cc/301sXwpS)
The image above presents a heatmap comparison of different models performing ASR tasks on a video with varying audio input lengths. As shown in the heatmap, Qwen-Omni and Phi-4 exhibit instability across different lengths and do not consistently produce the desired output.
*Note: The ground truth is derived from the auto-generated subtitles downloaded from YouTube. Therefore, the WER does not necessarily imply that our model achieves perfect results, but rather demonstrates that our model is comparable to the YouTube ASR pipeline.*
#### Model's Output
**Qwen Omni (12 minutes chunk)**
When processing the audio in 12-minute chunks, Qwen-Omni failed to recognize the full speech content and was only able to capture portions of the audio.
```
that's like what's going on why does itfocused on um ai and parallel parallelizable workloads but it's still general to an extent it's not as use case specific as something like grock with a queue that's really designed to you know spit out tokens as fast as possible and that like is a goldilocks zone where it's flexible enough to handle different workloads but not um but still much faster than um a traditional cpu and that google is one of the only companies that has a scaled internal custom silicon effort
```
**Phi-4-Multimodal (full chunk)**
When processing the full audio without splitting, the Phi-4-Multimodal model began to ignore the instructions and instead generated an overall summary of the audio.
```
The conversation covered Nvidia's focus on inference over training, the partnership with GM, the release of GUT-N1 for humanoid robotics, and the impact of China's AI initiatives on global chip demand.
```
**Aero (full chunk)**
Aero Audio is able to generate the complete ASR output and accurately identify the full transcript.
```
Welcome to the brainstorm episode eighty two frank downing joining us recap of nvidia's gtc conference that is the gpu technology conference frank what happened what were the big takeaways i on my side i saw a gm and in video partnering but we can circle back to that what was
...
right nice timing good timing all right we'll see everyone next week see everyone thank you
```
#### Results on LibriSpeech Unchunked
In the previous release, LibriSpeech split their audio files into smaller chunks and calculated the overall Word Error Rate (WER) based on these segmented samples. However, as we observed, it is straightforward to concatenate the chunks back into their original form, thereby creating a simple long-form Audio Speech Recognition benchmark. We evaluated various models on these benchmarks and found that their performance generally declined compared to their results on shorter samples. Among the models tested, our model achieved the best performance, showing the smallest drop in accuracy relative to the chunked version.
LS.Clean
LS.Other
LS.Clean(Long)
LS.Other(Long)
Avg Diff
Phi-4
1.68
3.83
11.51
24.72
30.72
Qwen2-Audio-Instruct
3.59
7.46
93.01
93.63
175.59
Qwen2.5-Omni
1.80
3.40
13.03
13.29
21.12
Aero-1-Audio
1.49
3.17
5.31
11.71
12.36
We present the evaluation of various models on the unchunked LibriSpeech dataset. The average result is calculated by averaging the WER score differences across the same splits. All models show some degradation when handling longer audio, whereas our model exhibits the least amount of performance drop.
## Evaluation Results
We then present the full evaluation result here with the evaluation scores
### ASR Benchmarks
Model
Parameters
Automatic Speech Recognition
Average
AMI
Earnings22
LibriSpeech
Clean
LibriSpeech
Other
SPGispeech
TED-LIUM
ElevenLabs/Scribe
N/A
14.43
12.14
1.79
3.31
3.30
3.17
6.36
REV.AI/Fusion
N/A
10.93
12.09
2.88
6.23
4.05
2.80
6.50
OpenAI/Whisper-large-v3
1.5B
15.95
11.29
2.01
3.91
2.94
3.86
6.66
Assembly.AI/AssemblyBest
N/A
15.64
13.54
1.74
3.11
1.81
3.43
6.55
Alibaba/Qwen2.5-Omni
7B
12.41
12.74
1.80
3.40
2.35
3.11
5.97
Microsoft/Phi-4-Multimodal
4B+1.6B
11.45
10.50
1.67
3.82
3.11
2.89
5.57
LMMs-Lab/Aero-1-Audio
1.5B
10.53
13.79
1.49
3.17
1.97
2.87
5.64
We evaluate our model on AMI, Earnings22, LibriSpeech, SPGISpeech, and TedLium. Our model achieves the second-best WER score compared to other models, while maintaining a small and efficient size.
### Audio Understanding Result
We then test our model's understanding results across 3 dimensions, Audio Analysis and Understanding, Speech Instruction, and Audio Scene Understanding
Model
Parameters
Audio Analysis and Understanding
Speech Instruction
Audio Scene Understanding
Average
AIR-Chat
MMAU
OpenHermes
Alpaca Audio
AIR-Foundation
Speech
Sound
Music
Mix
Avg
testmini
test
test
Speech
Sound
Music
Alibaba/Qwen2-Audio-Instruct
7B
7.2
7.0
6.8
6.8
6.9
49.2
46.8
49.2
62.9
55.4
56.8
56.7
Alibaba/Qwen2.5-Omni
7B
6.8
5.7
4.8
5.4
5.7
65.6
57.2
57.4
67.2
76.3
63.0
64.4
Microsoft/Phi-4-Multimodal
4B+1.6B
7.5
7.0
6.7
6.8
7.0
65.0
57.8
62.6
48.3
40.6
35.5
52.8
Tencent/Ola
7B
7.3
6.4
5.9
6.0
6.4
70.3
62.6
62.8
58.8
70.4
53.1
63.2
Tencent/Vita 1.5
7B
4.8
5.5
4.9
2.9
4.5
35.5
9.6
7.0
31.5
24.1
25.5
28.6
InspirAI/Mini-Omni2
0.5B
3.6
3.5
2.6
3.1
3.2
-
-
-
-
-
-
-
LMMs-Lab/Aero-1-Audio
1.5B
5.7
5.3
4.7
5.8
5.4
59.4
40.0
45.4
48.0
57.6
44.2
50.5
We conducted evaluations on AIR-Bench-Chat and MMAU for audio analysis and understanding. Our model achieved an average score of 5.35, outperforming Mini-Omni2 and Vita. For Audio Instruction Following, we evaluated on OpenHermes and Alpaca-Audio, following the same pipeline as AudioBench. Our model demonstrates a strong ability to understand instructions in speech and provide correct responses. Additionally, when evaluated on AIR-Bench-Foundation for Audio Scene Understanding, our model outperformed Phi-4-Multimodal in the sound and music dimensions. Overall, the average score of our model indicates strong performance relative to other models with larger parameter sizes.
## Training Techniques
### Dynamic Batch Size
We implemented a dynamic batching strategy based on the estimated token length to control the batch size per device. In many cases, using a fixed batch size requires setting it conservatively small to avoid out-of-memory (OOM) errors on longer samples, which leads to underutilization of computing resources. To address this, we group samples into batches such that the total token length stays within a predefined threshold, thereby minimizing computational waste and improving efficiency.
### Sequence Packing
To further optimize dynamic batching, we implemented sequence packing for both the audio encoder and the language model, enabling larger batch sizes and faster training. This operation was then fused with the Liger kernel to achieve even higher throughput and lower memory usage. With a fixed packing length of 4096 to regulate the dynamic batch size, the average Model FLOP Utilization (MFU) was limited to 0.03. However, with sequence packing enabled, the average MFU increased to approximately 0.34, demonstrating a significant improvement in training efficiency.
Packing Length
Sequence Packing
Num GPUs
Avg MFU
Zero
OOM
4096
FALSE
64
0.03
2
No
32768
FALSE
64
NA
2
Yes
32768
TRUE
32
0.34
2
No
We tested our implementations on different settings to demonstrate the efficiency of our implementation
## Contributor List
> alphabetical order
**main contributors*
Bo Li*
Chen Change Loy
Fanyi Pu
Jingkang Yang
Kaichen Zhang*
Kairui Hu
Luu Minh Thang*
Nguyen Quang Trung*
Pham Ba Cong*
Shuai Liu
Yezhen Wang*
Ziwei Liu