Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/facebookresearch/holo_diffusion
Code repository for the CVPR2023 publication "HoloDiffusion: Training a 3D diffusion model using 2D Images"
https://github.com/facebookresearch/holo_diffusion
Last synced: 8 days ago
JSON representation
Code repository for the CVPR2023 publication "HoloDiffusion: Training a 3D diffusion model using 2D Images"
- Host: GitHub
- URL: https://github.com/facebookresearch/holo_diffusion
- Owner: facebookresearch
- License: other
- Created: 2023-07-26T13:51:26.000Z (over 1 year ago)
- Default Branch: main
- Last Pushed: 2024-05-22T18:32:44.000Z (6 months ago)
- Last Synced: 2024-05-22T19:45:37.543Z (6 months ago)
- Language: Python
- Homepage:
- Size: 40.2 MB
- Stars: 135
- Watchers: 6
- Forks: 1
- Open Issues: 6
-
Metadata Files:
- Readme: README.md
- Contributing: CONTRIBUTING.md
- License: LICENSE
- Code of conduct: CODE_OF_CONDUCT.md
Awesome Lists containing this project
README
# HoloDiffusion: Training a 3D Diffusion Model using 2D Images


[![CC BY-NC-SA 4.0][cc-by-nc-sa-shield]][cc-by-nc-sa]
This work is licensed under a
[Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License][cc-by-nc-sa].
[![CC BY-NC-SA 4.0][cc-by-nc-sa-image]][cc-by-nc-sa]
[cc-by-nc-sa]: http://creativecommons.org/licenses/by-nc-sa/4.0/
[cc-by-nc-sa-image]: https://licensebuttons.net/l/by-nc-sa/4.0/88x31.png
[cc-by-nc-sa-shield]: https://img.shields.io/badge/License-CC%20BY--NC--SA%204.0-lightgrey.svg
----------------------------------------------------------------------------------------------------
## Index
- [Overview](#overview)
* [Abstract](#abstract)
* [Method](#method)
- [Code](#code)
* [Dependencies](#dependencies)
* [Training](#training)
* [Data](#data)
* [Training models](#training-models)
* [Visualization](#visualization)
* [Sampling](#sampling)
* [Generating samples](#generating-samples)
- [Acknowledgement](#acknowledgement)
- [Citation](#citation)
----------------------------------------------------------------------------------------------------
## Overview

### Abstract
Diffusion models have emerged as the best approach for generative modeling of 2D images. Part of their success is due to the possibility of training them on millions if not billions of images with a stable learning objective. However, extending these models to 3D remains difficult for two reasons. First, finding a large quantity of 3D training data is much harder than for 2D images. Second, while it is conceptually trivial to extend the models to operate on 3D rather than 2D grids, the associated cubic growth in memory and compute complexity makes this unfeasible. We address the first challenge by introducing a new diffusion setup that can be trained, end-to-end, with only posed 2D images for supervision, and the second challenge by proposing an image formation model that decouples model memory from spatial memory. We evaluate our method on real-world data, using the
[CO3Dv2](https://github.com/facebookresearch/co3d)
dataset which has not been used to train 3D generative models before. We show that our diffusion models are scalable, train robustly, and are competitive in terms of sample quality and fidelity to existing approaches for 3D generative modeling.
### Method
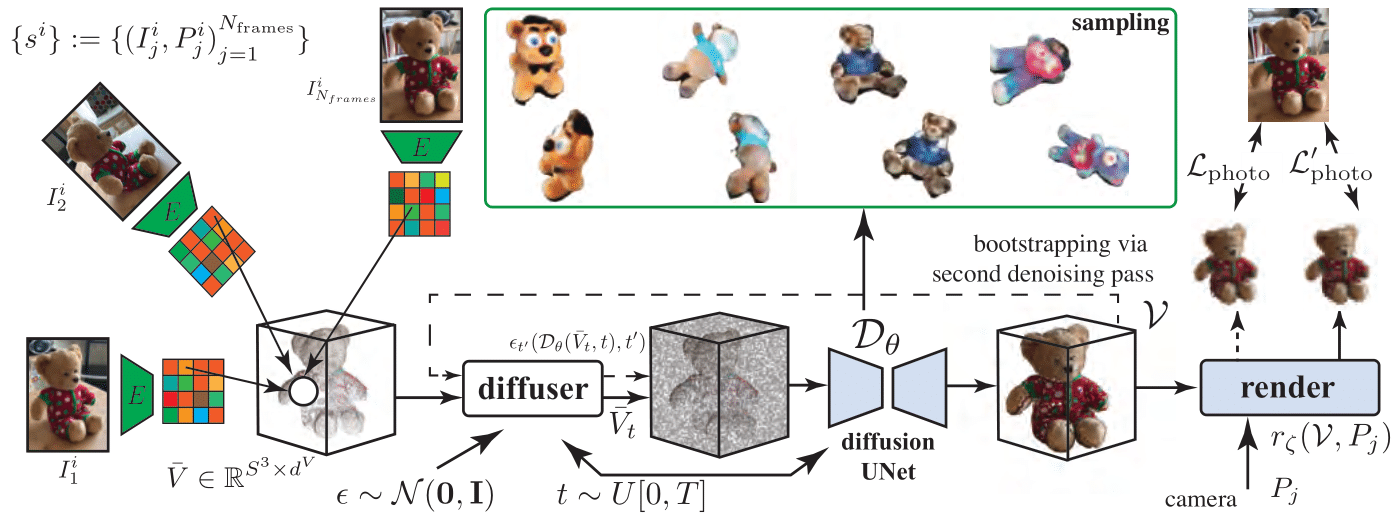
Method Overview. Our HoloDiffusion takes as input video frames for category-specific videos
and produces a diffusion-based generative model. The model is trained with only posed image supervision, without access to 3D ground-truth. Once trained, the model can generate view-consistent results from novel camera locations. Please refer to Sec. 3 of the
[paper](https://geometry.cs.ucl.ac.uk/group_website/projects/2023/holodiffusion/webpage/static/docs/holo_diffusion_fullres.pdf)
for details.
----------------------------------------------------------------------------------------------------
## Code
This section presents information about using the code. We use the [Implicitron](https://ai.facebook.com/blog/implicitron-a-new-modular-extensible-framework-for-neural-implicit-representations-in-pytorch3d/) framework for implementing our proposed method. Implicitron is available as a module under [PyTorch3D](https://pytorch3d.org/). It is recomended to go through the [example projects](https://github.com/facebookresearch/pytorch3d/tree/main/projects/implicitron_trainer) of implicitron to understand more about the implicitron-mechanisms before diving into our code. Following is a succinct summary of the strucutre of our code: The main code lies in `holo_diffusion` package in the `holo_diffusion_model.py` and `holo_voxel_grid_implicit_function.py` modules. The latter defines the 3D implicit function which representes the scenes as radiance fields, while the former implements the proposed holo_diffusion pipeline from figure 1. `trainer` package contains the ML components for training, model-building and optimization. We replicated these implicitron parts here in order to make some custom tweaks without affecting the released implicitron package. We also use some of the code from the [guided_diffusion](https://github.com/openai/guided-diffusion) repository and acknowledge here with their original license.
### Dependencies
The fastest way to get up and running is to create a new conda environment using the `environment.yaml` file provided here.
```
@:/holo_diffusion$ conda env create -f environment.yml
@:/holo_diffusion$ conda activate holo_diffusion_release
(holo_diffusion_release) @:/holo_diffusion$
```
Once the release environment is activated, you can start running the training/sampling scripts.
**But, for some reason, if this doesn't work for you; create a new environment manually and install the following packages.**
```
# New conda environment
conda create -n holo_diffusion_release python==3.9.15
conda activate holo_diffusion_release
# Pytorch3D:
conda install -c pytorch -c nvidia pytorch=1.13.1 torchvision pytorch-cuda=11.6
conda install -c fvcore -c conda-forge fvcore iopath
conda install -c bottler nvidiacub
conda install -c pytorch3d pytorch3d
# Configuration management:
conda install -c conda-forge hydra-core
# Miscellaneous:
conda install -c conda-forge imageio
conda install -c conda-forge accelerate
conda install -c conda-forge matplotlib plotly visdom
```
### Training
Running the training scripts involves a few of steps. They are described as follows.
#### Data
We use the [Co3Dv2](https://github.com/facebookresearch/co3d) for training the models. Please follow the steps on the Co3Dv2 repository to download the dataset. The full dataset is large and occupies **5.5TB** of space, so feel free to download only the classes that you are interested in.
Once, downloaded the dataset should have the following directory structure
```
CO3DV2_DATASET_ROOT
├──
│ ├──
│ │ ├── depth_masks
│ │ ├── depths
│ │ ├── images
│ │ ├── masks
│ │ └── pointcloud.ply
│ ├──
│ │ ├── depth_masks
│ │ ├── depths
│ │ ├── images
│ │ ├── masks
│ │ └── pointcloud.ply
│ ├── ...
│ ├──
│ ├── set_lists
│ ├── set_lists_.json
│ ├── set_lists_.json
│ ├── ...
│ ├── set_lists_.json
│ ├── eval_batches
│ │ ├── eval_batches_.json
│ │ ├── eval_batches_.json
│ │ ├── ...
│ │ ├── eval_batches_.json
│ ├── frame_annotations.jgz
│ ├── sequence_annotations.jgz
├──
├── ...
├──
```
Please ensure that all the `set_lists` and `eval_batches` are present correctly for the `categories` that you are working with. This is important for the Data-Loading mechanism of the training pipeline to work correctly.
(Optional)
At this point, feel free to run the `examples/show_co3d_dataset.py` script from the [Co3Dv2](https://github.com/facebookresearch/co3d) repository to explore the data and to understand the data better.
#### Training models
Once, the data is downloaded and properly setup, the training scripts can now be run as follows. set an environment variable named `CO3DV2_DATASET_ROOT` which points to the root directory of the Co3Dv2 dataset.
```
(holo_diffusion_release) @:/holo_diffusion$ export CO3DV2_DATASET_ROOT=
```
With the environment variable set, use the `experiment.py` script to start the training.
```
(holo_diffusion_release) @:/holo_diffusion$ python experiment.py --config-name base.yaml
```
Some notes about the training pipeline:
1. The base path where the configs are stored is `configs/`, but can be overridden while running the `experiment.py` script.
2. The `base.yaml` config specifies config used for training holo_diffusion models. Feel free to create copies from it to:
- Change the category for training.
- Change the model size.
- Experiment with the hyperparamters of diffusion
- Experiment with hyperparameters of the holo-diffusion training
3. ***Always remeber** to set the `exp_dir` in the config to point to your intended output directory for the experiment.
4. (Optional) The config `configs/unet_with_no_diffusion.yaml` can be used to run the baseline which trains a 3D Unet to do few-view reconstruction **without diffusion**.
5. (Optional) You can also modify the `configs/unet_with_no_diffusion.yaml` configuration, by disabling the `3D_unet`, to train a few-view reconstruction model which only uses the RenderMLP to go from pooled voxel features to rendered views.
6. **The baselines of 4. and 5. are a useful indicator to guide the expected performance from the holo-diffusion models in case you are training on a dataset other than Co3D. The visual quality of the models should be such that 5. > 4. and the quality of samples for the diffusion models is somewhere between the two. Note that the noising and denoising process for the generative modelling losses some visual quality compared to non-stochastic few-view reconstruction process.
#### Visualization
We use [`visdom`](https://github.com/fossasia/visdom) for visualizing the stats and visual logs during training. To access the visdom dashboard, start a visdom server on the `visdom_server` and `visdom_port` specified in the training config. **Please note that the visdom server should be running before starting the training, so that the training process can connect to the visdom server**.
```
(holo_diffusion_release) @:/holo_diffusion$ python -m visdom.server --hostname --port
```
### Sampling
Once the models are trained using the training (experiment) script, run the sample-generating script as follows to generate samples (or visualize reconstructions).
#### Generating samples
Once the experiments are complete and the `exp_dirs` setup, you can generate samples using the `generate_samples.py` script. An example invocation is as follows.
```
(holo_diffusion_release) @:/holo_diffusion$ python generate_samples.py \
exp_dir= \
render_size=[512,512] \
video_size=[512,512] \
num_samples=15 \
save_voxel_features=True
```
To generate the sampling animation (similar to the ones shown at the top), use the `progressive_sampling_steps_per_render` option of the `generate_samples.py` script. It controls, how many sampling steps to take before rendering a view on the circular camera trajectory.
```
(holo_diffusion_release) @:/holo_diffusion$ python generate_samples.py \
exp_dir= \
render_size=[512,512] \
video_size=[512,512] \
num_samples=15 \
save_voxel_features=False \
progressive_sampling_steps_per_render=4
```
*(Optional)*
Please note that you can similarly use the `visualize_reconstruction.py` script for visualizing the few-view reconstructions from the baseline unet model which is trained without diffusion.
----------------------------------------------------------------------------------------------------
## Acknowledgement

Animesh and Niloy were partially funded by the European Union’s Horizon 2020 research and innovation programme under the Marie Skłodowska-Curie grant agreement No. 956585. This research has also been supported by MetaAI and the UCL AI Centre. Finally, Animesh thanks Alexia Jolicoeur-Martineau for the the helpful and insightful guidance on diffusion models.
----------------------------------------------------------------------------------------------------
## Citation
```
@inproceedings{karnewar2023holodiffusion,
title={HoloDiffusion: Training a {3D} Diffusion Model using {2D} Images},
author={Karnewar, Animesh and Vedaldi, Andrea and Novotny, David and Mitra, Niloy},
booktitle={Proceedings of the IEEE/CVF conference on computer vision and pattern recognition},
year={2023}
}
```
----------------------------------------------------------------------------------------------------