https://github.com/facefusion/facefusion
Industry leading face manipulation platform
https://github.com/facefusion/facefusion
ai deep-fake deepfake face-swap faceswap lip-sync lipsync
Last synced: 5 months ago
JSON representation
Industry leading face manipulation platform
- Host: GitHub
- URL: https://github.com/facefusion/facefusion
- Owner: facefusion
- License: other
- Created: 2023-08-17T19:59:55.000Z (almost 3 years ago)
- Default Branch: master
- Last Pushed: 2025-05-05T14:55:09.000Z (about 1 year ago)
- Last Synced: 2025-05-07T06:18:10.800Z (about 1 year ago)
- Topics: ai, deep-fake, deepfake, face-swap, faceswap, lip-sync, lipsync
- Language: Python
- Homepage: https://join.facefusion.io
- Size: 21.1 MB
- Stars: 22,756
- Watchers: 210
- Forks: 3,500
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- Funding: .github/FUNDING.yml
- License: LICENSE.md
Awesome Lists containing this project
- ai-game-devtools - FaceFusion
- awesome-ai - FaceFusion - Generate DeepFake videos and play the role of anyone you like: a movie hero, a singing star, etc. (排行榜 [2025-03-18])
- StarryDivineSky - facefusion/facefusion
- awesome-genai - Facefusion - Next generation face swapper and enhancer. [](https://github.com/facefusion/facefusion/network/members) [](https://github.com/facefusion/facefusion/stargazers) (Tools & Frameworks / Deep Fake)
- AiTreasureBox - facefusion/facefusion - 11-03_25682_0](https://img.shields.io/github/stars/facefusion/facefusion.svg)|Next generation face swapper and enhancer| (Repos)
- awesome-comfyui - FaceFusion
- awesome-data-analysis - facefusion - AI face swapping and enhancement tool. (🧠 AI Applications & Platforms / Tools)
- awesome-github-projects - facefusion - Industry leading face manipulation platform ⭐29,201 `Python` 🔥 (🤖 AI & Machine Learning)
- awesome-rainmana - facefusion/facefusion - Industry leading face manipulation platform (Python)
- awesome-hacking-lists - facefusion/facefusion - Industry leading face manipulation platform (Python)
- awesome-ai - Face Fusion
README
FaceFusion
==========
> Industry leading face manipulation platform.
[](https://github.com/facefusion/facefusion/actions?query=workflow:ci)
[](https://coveralls.io/r/facefusion/facefusion)

Preview
-------
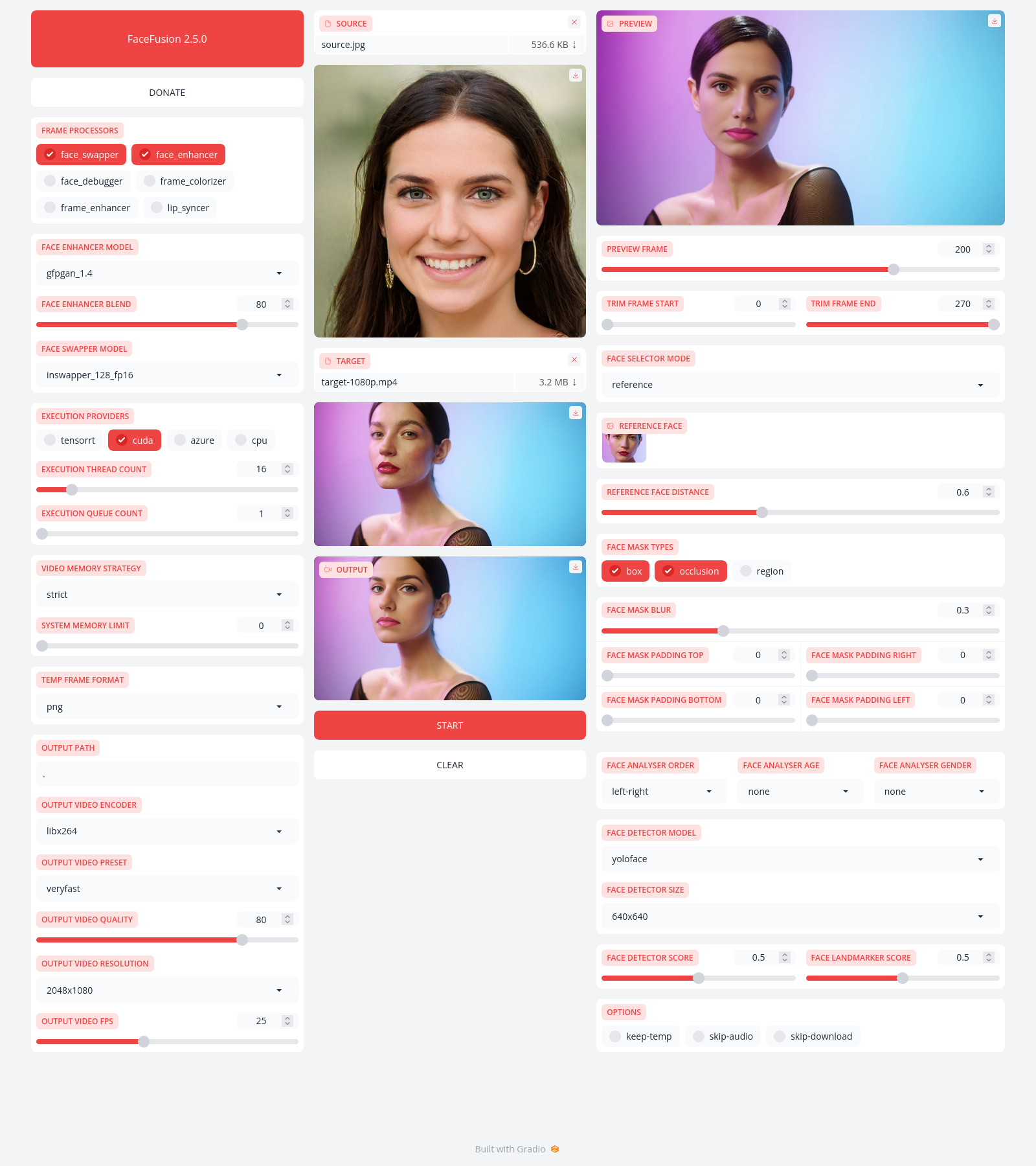
Installation
------------
Be aware, the [installation](https://docs.facefusion.io/installation) needs technical skills and is not recommended for beginners. In case you are not comfortable using a terminal, our [Windows Installer](http://windows-installer.facefusion.io) and [macOS Installer](http://macos-installer.facefusion.io) get you started.
Usage
-----
Run the command:
```
python facefusion.py [commands] [options]
options:
-h, --help show this help message and exit
-v, --version show program's version number and exit
commands:
run run the program
headless-run run the program in headless mode
batch-run run the program in batch mode
force-download force automate downloads and exit
benchmark benchmark the program
job-list list jobs by status
job-create create a drafted job
job-submit submit a drafted job to become a queued job
job-submit-all submit all drafted jobs to become a queued jobs
job-delete delete a drafted, queued, failed or completed job
job-delete-all delete all drafted, queued, failed and completed jobs
job-add-step add a step to a drafted job
job-remix-step remix a previous step from a drafted job
job-insert-step insert a step to a drafted job
job-remove-step remove a step from a drafted job
job-run run a queued job
job-run-all run all queued jobs
job-retry retry a failed job
job-retry-all retry all failed jobs
```
Documentation
-------------
Read the [documentation](https://docs.facefusion.io) for a deep dive.