https://github.com/fang-yan-peng/cronner
Cronner 是一个分布式定时任务框架,支持作业依赖、分片、失效转移、集中配置和监控。
https://github.com/fang-yan-peng/cronner
cronn cronner curator distributed elasticjob quartz sheduler zookeeper
Last synced: about 1 month ago
JSON representation
Cronner 是一个分布式定时任务框架,支持作业依赖、分片、失效转移、集中配置和监控。
- Host: GitHub
- URL: https://github.com/fang-yan-peng/cronner
- Owner: fang-yan-peng
- Created: 2017-09-22T09:59:48.000Z (over 7 years ago)
- Default Branch: master
- Last Pushed: 2018-08-17T03:19:08.000Z (almost 7 years ago)
- Last Synced: 2025-03-24T23:35:19.899Z (about 2 months ago)
- Topics: cronn, cronner, curator, distributed, elasticjob, quartz, sheduler, zookeeper
- Language: Java
- Homepage:
- Size: 1.41 MB
- Stars: 55
- Watchers: 10
- Forks: 20
- Open Issues: 1
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# Cronner
# 概要
Cronner 是一个分布式定时任务框架,支持作业依赖、作业分片、失效转移、集中配置和监控。
# 特点
- 支持作业集中配置、监控。
- 支持作业分片。
- 支付作业失效转移。
- 支持作业之间依赖
# 架构图
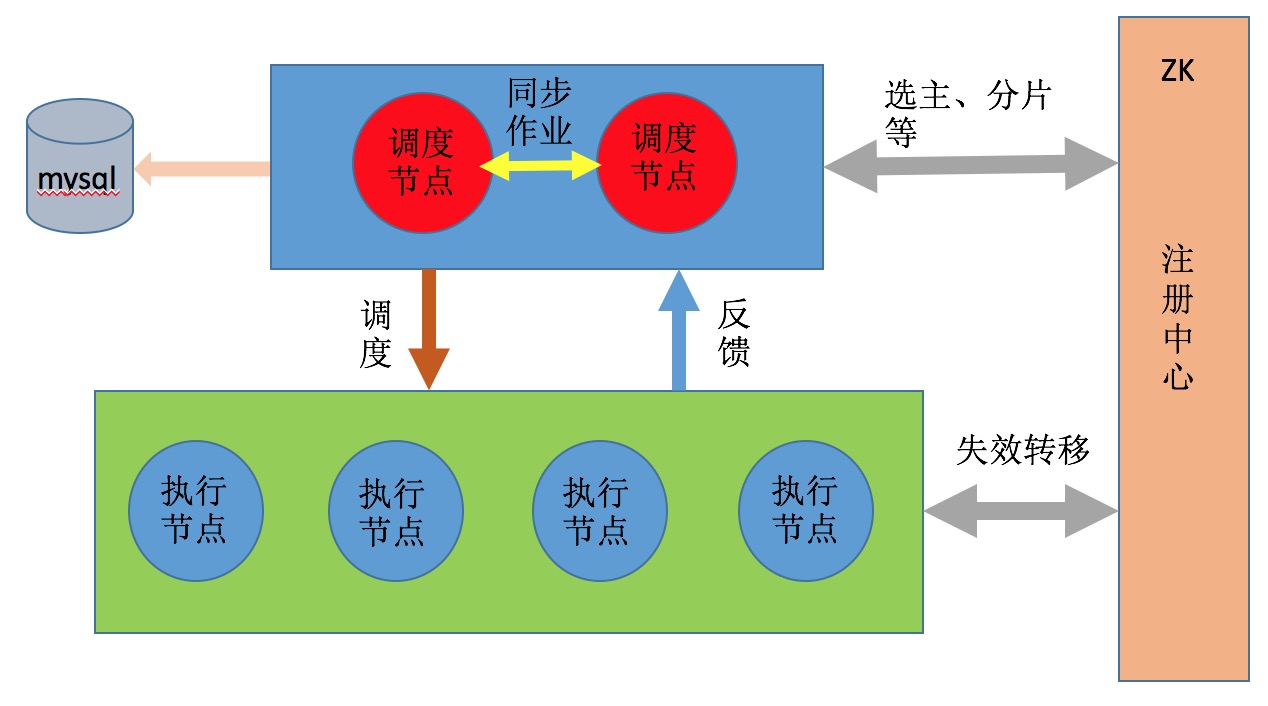
# 例子
> * JDK 1.7 or above
> * 编译工具 [Maven][maven]
## SpringBoot 例子
以java -jar的方式启动需要配置插件
```xml
org.springframework.boot
spring-boot-maven-plugin
org.jfaster.cronner
cronner-executor
```
1. 添加依赖.
```xml
org.jfaster.cronner
spring-boot-starter-cronner
1.0.1
org.jfaster.cronner
spring-boot-starter-zookeeper
1.0.1
```
2. 创建一个作业。
`src/main/java/cronner/jfaster/org/example/job/listener/JobListenerExample.java`
```java
package cronner.jfaster.org.example.job.listener;
import cronner.jfaster.org.executor.ShardingContexts;
import cronner.jfaster.org.job.api.listener.CronnerJobListener;
/**
* @author fangyanpeng
*/
public class JobListenerExample implements CronnerJobListener{
@Override
public void beforeJobExecuted(ShardingContexts shardingContexts) {
System.out.println(String.format("----SpringBoot Job: %s begin----",shardingContexts.getJobName()));
}
@Override
public void afterJobExecuted(ShardingContexts shardingContexts) {
System.out.println(String.format("----SpringBoot Job: %s end----",shardingContexts.getJobName()));
}
}
```
`src/main/java/cronner/jfaster/org/example/job/SimpeCronnerJobSpringboot.java`
```java
package cronner.jfaster.org.example.job;
import cronner.jfaster.org.job.annotation.Job;
import cronner.jfaster.org.example.job.listener.JobListenerExample;
import cronner.jfaster.org.job.api.ShardingContext;
import cronner.jfaster.org.job.api.simple.SimpleJob;
import java.util.concurrent.TimeUnit;
/**
* @author fangyanpeng
*/
@Job(name = "cronner-simple-job",listener = JobListenerExample.class)
public class SimpeCronnerJobSpringboot implements SimpleJob {
@Override
public void execute(ShardingContext shardingContext) {
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(String.format("jobName=%s,jobParameter=%s,shardingItem=%s,shardingParameter=%s",shardingContext.getJobName(),shardingContext.getJobParameter(),shardingContext.getShardingItem(),shardingContext.getShardingParameter()));
}
}
```
`src/main/java/cronner/jfaster/org/example/job/DataflowCronnerJobSpring.java`
```java
package cronner.jfaster.org.example.job;
import cronner.jfaster.org.job.annotation.Job;
import cronner.jfaster.org.example.job.listener.JobListenerExample;
import cronner.jfaster.org.job.api.ShardingContext;
import cronner.jfaster.org.job.api.dataflow.DataflowJob;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.TimeUnit;
/**
* @author fangyanpeng
*/
@Job(name = "cronner-dataflow-job",listener = JobListenerExample.class)
public class DataflowCronnerJobSpring implements DataflowJob {
@Override
public List fetchData(ShardingContext shardingContext) {
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
return Arrays.asList("hello","cronner");
}
@Override
public void processData(ShardingContext shardingContext, List data) {
System.out.println(String.format("jobName=%s,jobParameter=%s,shardingItem=%s,shardingParameter=%s",shardingContext.getJobName(),shardingContext.getJobParameter(),shardingContext.getShardingItem(),shardingContext.getShardingParameter()));
for (String str : data){
System.out.println(str);
}
}
}
```
3. 配置yml文件,并启动作业。
```xml
########### Zookeeper Configuration Start ###########
zookeeper:
serverLists: 127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183
namespace: cronner
baseSleepTimeMilliseconds: 1000
maxSleepTimeMilliseconds: 3000
maxRetries: 3
############ Zookeeper Configuration End ###########
########### cronner packege Configuration Start ###########
cronner:
package: cronner.jfaster.org.example.job
############ cronner packege Configuration End ###########
```
`src/main/java/cronner/jfaster/org/example/CronnerSpringBootMain.java`
```java
package cronner.jfaster.org.example;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.ConfigurableApplicationContext;
/**
* @author fangyanpeng
*/
@SpringBootApplication
public class CronnerSpringBootMain {
public static void main(String[] args) {
ConfigurableApplicationContext context = SpringApplication.run(CronnerSpringBootMain.class,args);
}
}
```
执行main方法,就会启动作业,就是一个执行节点。每个执行节点都会启动一个端口接收调度节点的命令,默认端口9233。如果同一台机器启动多个执行节点,通过java -Dcronner.executor.port=8888指定端口,避免端口冲突。
## Spring例子
1. 添加依赖.
```xml
org.jfaster.cronner
cronner-spring-support
1.0.1
```
2. 创建一个作业。
`src/main/java/cronner/jfaster/org/example/job/listener/JobListenerExample.java`
```java
package cronner.jfaster.org.example.job.listener;
import cronner.jfaster.org.executor.ShardingContexts;
import cronner.jfaster.org.job.api.listener.CronnerJobListener;
/**
* @author fangyanpeng
*/
public class JobListenerExample implements CronnerJobListener{
@Override
public void beforeJobExecuted(ShardingContexts shardingContexts) {
System.out.println(String.format("----Spring Job: %s begin----",shardingContexts.getJobName()));
}
@Override
public void afterJobExecuted(ShardingContexts shardingContexts) {
System.out.println(String.format("----Spring Job: %s end----",shardingContexts.getJobName()));
}
}
```
`src/main/java/cronner/jfaster/org/example/job/SimpeCronnerJobSpring.java`
```java
package cronner.jfaster.org.example.job;
import cronner.jfaster.org.job.annotation.Job;
import cronner.jfaster.org.example.job.listener.JobListenerExample;
import cronner.jfaster.org.job.api.ShardingContext;
import cronner.jfaster.org.job.api.simple.SimpleJob;
import java.util.concurrent.TimeUnit;
/**
* @author fangyanpeng
*/
@Job(name = "cronner-simple-job",listener = JobListenerExample.class)
public class SimpeCronnerJobSpring implements SimpleJob {
@Override
public void execute(ShardingContext shardingContext) {
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(String.format("jobName=%s,jobParameter=%s,shardingItem=%s,shardingParameter=%s",shardingContext.getJobName(),shardingContext.getJobParameter(),shardingContext.getShardingItem(),shardingContext.getShardingParameter()));
}
}
```
`src/main/java/cronner/jfaster/org/example/job/DataflowCronnerJobSpringboot.java`
```java
package cronner.jfaster.org.example.job;
import cronner.jfaster.org.job.annotation.Job;
import cronner.jfaster.org.example.job.listener.JobListenerExample;
import cronner.jfaster.org.job.api.ShardingContext;
import cronner.jfaster.org.job.api.dataflow.DataflowJob;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.TimeUnit;
/**
*
*/
@Job(name = "cronner-dataflow-job",listener = JobListenerExample.class)
public class DataflowCronnerJobSpringboot implements DataflowJob {
@Override
public List fetchData(ShardingContext shardingContext) {
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
return Arrays.asList("hello","cronner");
}
@Override
public void processData(ShardingContext shardingContext, List data) {
System.out.println(String.format("jobName=%s,jobParameter=%s,shardingItem=%s,shardingParameter=%s",shardingContext.getJobName(),shardingContext.getJobParameter(),shardingContext.getShardingItem(),shardingContext.getShardingParameter()));
for (String str : data){
System.out.println(str);
}
}
}
```
3. 配置xml文件,并启动作业。
```xml
```
`src/main/java/cronner/jfaster/org/example/CronnerSpringMain.java`
```java
package cronner.jfaster.org.example;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import java.util.concurrent.CountDownLatch;
/**
* @author fangyanpeng
*/
public class CronnerSpringMain {
public static void main(String[] args) throws InterruptedException {
ClassPathXmlApplicationContext ctx = new ClassPathXmlApplicationContext("classpath*:job.xml");
ctx.start();
CountDownLatch latch = new CountDownLatch(1);
latch.await();
}
}
```
执行main方法,就会启动作业,就又启动了一个执行节点。相同的作业名会构成一个执行集群,整个集群节点间进行分片和失效转移等。例如上面启动的两个进程,就构成了两个分别以cronner-simple-job和cronner-dataflow-job为标识的作业执行集群。
## 启动调度节点
> 以上部分启动的都是执行节点,接下来启动调度节点。调度节点用于作业配置、作业调度、作业分发、收集执行节点的作业执行情况。
> 为了保证高可用,调度节点至少启动两个,一个down了,其它调度节点可以自动接管任务调度。
> 调度节点提供管理界面,用于作业的集中配置和管理。
1. 启动调度步骤
* tar -zxvf cronner-manager-1.0.1.tar.gz
* cd cronner-manager-1.0.1
* vim conf/cronner.conf 修改登陆后台的用户名、密码、端口号、数据库地址、zk地址、jvm参数等。
* sh bin/cronner.sh start 启动节点
* 默认启动2145 端口
* 访问 http://127.0.0.1:2145端口
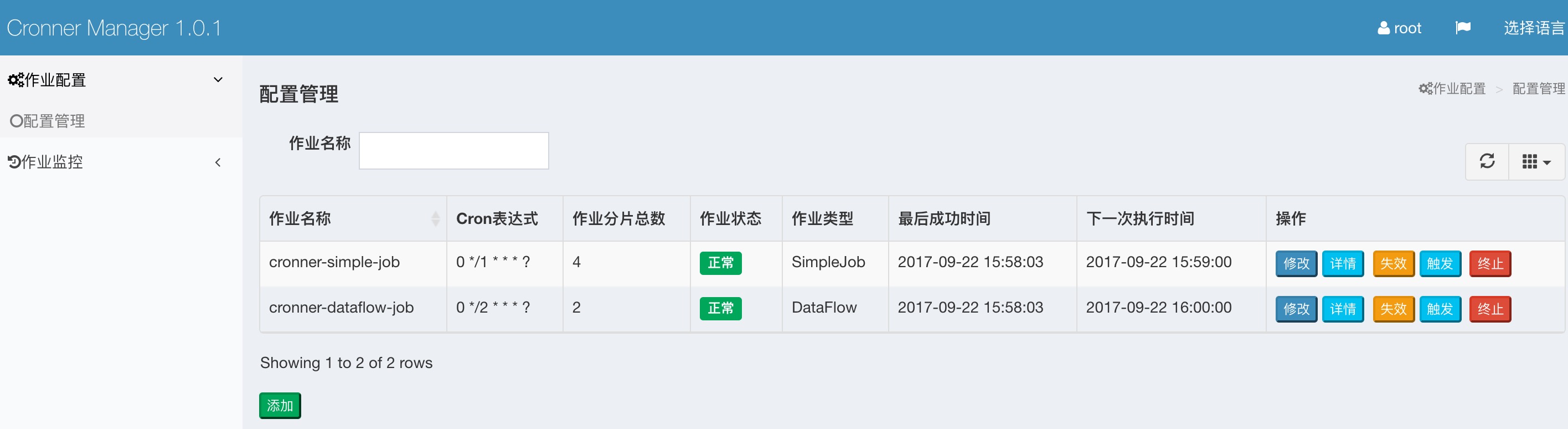
2. 添加作业调度。
* 点击 作业配置》配置管理》添加
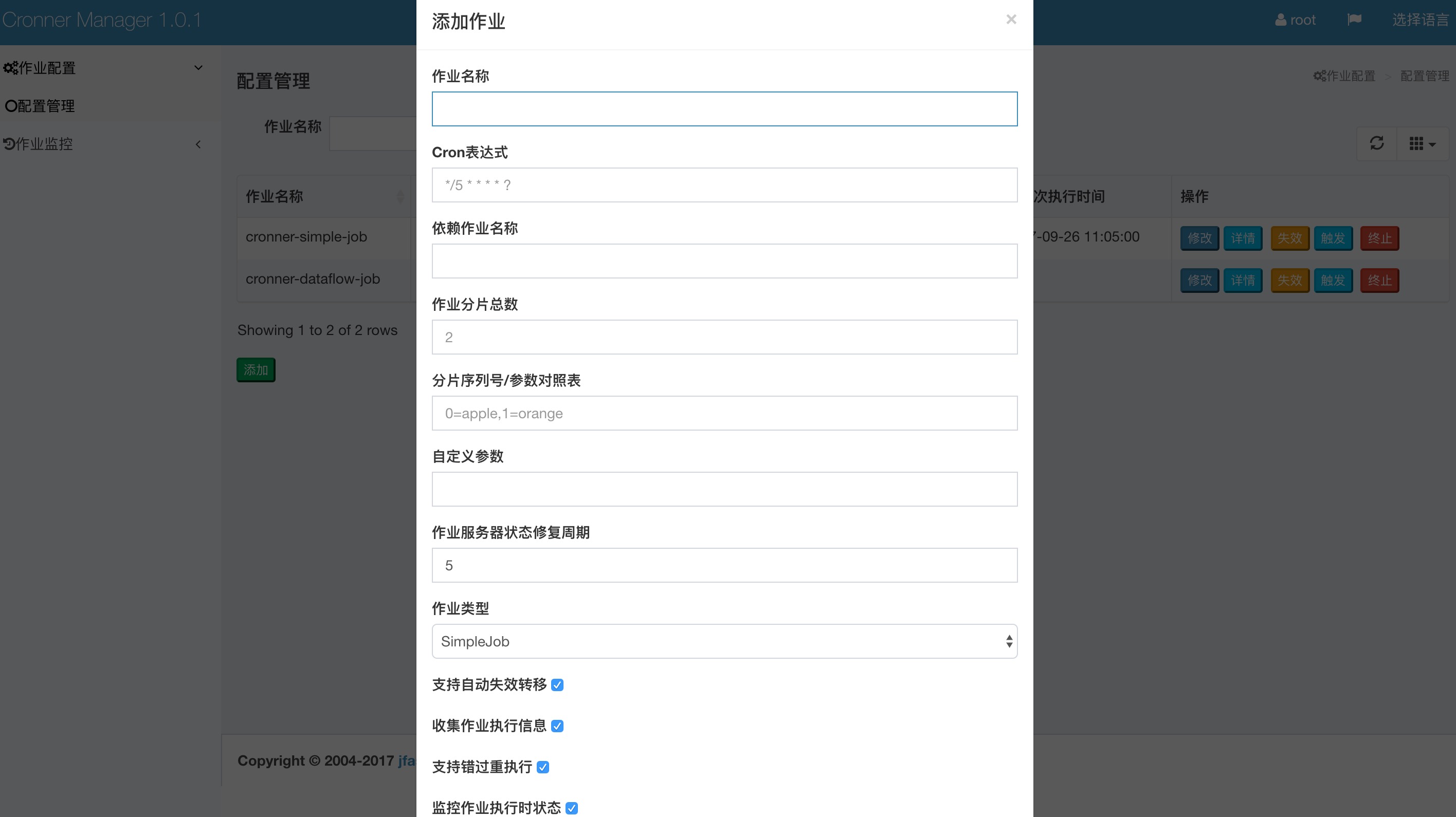
添加作业的名称要与执行节点的作业名称一致才能调度。
# 作业配置说明
* 作业名称: 要调度作业的名称。
* Cron表达式: quartz表达式。
* 依赖的作业名称: 例如作业B的执行必须等待作业A执行完成才能执行,那么在配置作业B的时候,在此配置上作业A的名称即可。那么作业A执行完成会自动调用作业B,此时cron表达式失去意义不用配置。
* 作业分片总数: 一个作业分几片执行。
* 分片序列号/参数对照表: 每个分片的序号和参数对照表。例如0=apple,1=banana。如果启动了两个执行节点,那么一个执行节点会拿到0=apple的分片,另一个执行节点会拿到1=banana的分片,拿到分片后可以根据分片的参数做相应的逻辑处理,例如拿到apple分片的执行节点只执行有关apple的业务逻辑,另一个执行节点也如此。
* 自定义参数: 每个作业可以定义一个自定义参数,作业内部获取到作业参数可以做自己的业务逻辑。
* 作业类型: 作业的类型SimpleJob、DataFlow、Script,程序里都提供了例子。
* 支持自动失效转移: 是否开启失效转移,如果开启,执行节点down机,这台机器上的分片会转移到其它执行节点继续执行。
* 收集作业执行信息: 是否收集作业的执行信息,如果开启,在后台就可以看到作业的执行情况。
* 支持错过重执行: 如果作业在调度时,发现上一次的作业还在运行,如果开启该配置,则会等上一次作业运行完,再运行本次任务。适合调度间隔比较大的任务。
* 监控作业执行时状态: 是否监控分片执行的状态。
# 贡献者
* fangyanpeng([@fangyanpeng](https://github.com/fang-yan-peng))
[maven]:https://maven.apache.org
[zookeeper]:http://zookeeper.apache.org