https://github.com/fasterthanlime/pegviz
PEG trace visualizer
https://github.com/fasterthanlime/pegviz
debugging grammar parser peg rust
Last synced: 9 months ago
JSON representation
PEG trace visualizer
- Host: GitHub
- URL: https://github.com/fasterthanlime/pegviz
- Owner: fasterthanlime
- License: mit
- Created: 2020-04-28T23:55:44.000Z (about 6 years ago)
- Default Branch: main
- Last Pushed: 2025-10-05T10:18:08.000Z (9 months ago)
- Last Synced: 2025-10-05T12:14:17.709Z (9 months ago)
- Topics: debugging, grammar, parser, peg, rust
- Language: Rust
- Homepage:
- Size: 76.2 KB
- Stars: 89
- Watchers: 0
- Forks: 10
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- Funding: .github/FUNDING.yml
- License: LICENSE
Awesome Lists containing this project
README
# pegviz


[](LICENSE-MIT)
Visualizer for https://crates.io/crates/peg parsers.
## Screenshot
`pegviz` reads peg's tracing markers and generates a collapsible HTML tree.
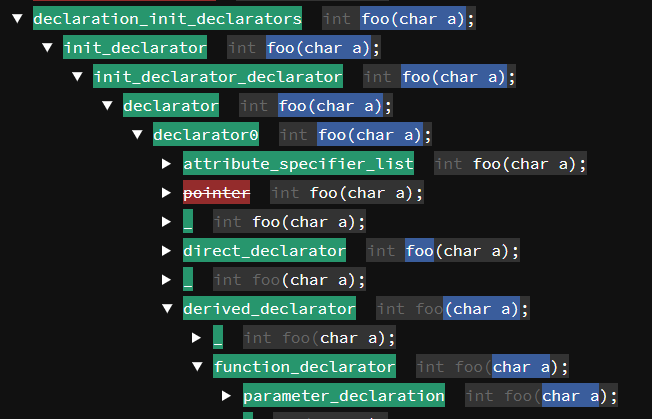
Left side:
* Green: matched rule
* Yellow: partial match (see below)
* Red: failed rule
Right side:
* Gray: previous input, for context
* Blue background: input matched by this rule
* White text: rest of input after matching
## Partial Matches
A partial match is a (special kind of) match failure.
It happens, if a rule consists of multiple sub-rules and some of them do match, but they do not all match.
Consider for example the grammar
```rust
pub rule traits() -> (Vec, Vec)
= awesome_traits:(awesome() ++ ". ") "."? " "?
boring_traits:(boring() ** ". ") "."?
{
(awesome_traits, boring_traits)
}
rule awesome() -> String
= name() " is awesome due to " reason:$(['a'..='z' | ' ']+) { reason.to_string() }
rule boring() -> String
= name() " is boring because of " reason:$(['a'..='z' | ' ']+) { reason.to_string() }
rule name() -> String = s:$(['A'..='Z']['a'..='z']+) { s.to_string() }
```
Here both `awesome` and `boring` start with `name()`.
When parsing a string like
"Paul is awesome due to his kindness. Ludwig is boring because of his cat."
the first sentence will match to the `awesome` rule, the second does not, but it _partially_ matches, because `Ludwig` also matches to `name()`.
It will, though, match to the `boring` rule.

## Format
`pegviz` expects input in the following format:
```
[PEG_INPUT_START]
int a = 12 + 45;
[PEG_TRACE_START]
[PEG_TRACE] Attempting to match rule `translation_unit0` at 1:1
[PEG_TRACE] Attempting to match rule `list0` at 1:1
[PEG_TRACE] Attempting to match rule `node` at 1:1
[PEG_TRACE] Attempting to match rule `external_declaration` at 1:1
[PEG_TRACE] Attempting to match rule `declaration` at 1:1
[PEG_TRACE] Attempting to match rule `node` at 1:1
[PEG_TRACE] Attempting to match rule `declaration0` at 1:1
[PEG_TRACE] Attempting to match rule `gnu` at 1:1
[PEG_TRACE] Attempting to match rule `gnu_guard` at 1:1
[PEG_TRACE] Failed to match rule `gnu_guard` at 1:1
[PEG_TRACE] Failed to match rule `gnu` at 1:1
[PEG_TRACE] Attempting to match rule `_` at 1:1
[PEG_TRACE] Matched rule `_` at 1:1 to 1:1
... ...
[PEG_TRACE_STOP]
```
The `_START` and `_STOP` marker are pegviz-specific, you'll need to add
them to your program. See the **Integration** section for more information.
Multiple traces may be processed, they'll all show up in the output file.
Output that occurs *between* traces is ignored.
## Compatibility
pegviz has been used with:
* peg 0.5.7
* peg 0.6.2
* peg 0.8.4
There are no tests. It's quickly thrown together.
## Integration
In your crate, re-export the `trace` feature:
```
# in Cargo.toml
[features]
trace = ["peg/trace"]
```
Then, in your parser, add a `tracing` rule that captures all the input
and outputs the markers `pegviz` is looking for:
```rust
peg::parser! { pub grammar example() for str {
rule traced(e: rule) -> T =
&(input:$([_]*) {
#[cfg(feature = "trace")]
println!("[PEG_INPUT_START]\n{}\n[PEG_TRACE_START]", input);
})
e:e()? {?
#[cfg(feature = "trace")]
println!("[PEG_TRACE_STOP]");
e.ok_or("")
}
pub rule toplevel() -> Toplevel = traced()
}}
```
If your parser uses slices (such as `&[u8]`, `&[T]`), then each character or token must be on a new line.
```rust
peg::parser! { pub grammar example() for str {
rule traced(e: rule) -> T =
&(input:$([_]*) {
#[cfg(feature = "trace")]
println!(
"[PEG_INPUT_START]\n{}\n[PEG_TRACE_START]",
input.iter().fold(
String::new(),
|s1, s2| s1 + "\n" + s2.to_string().as_str()
).trim_start().to_string()
);
})
e:e()? {?
#[cfg(feature = "trace")]
println!("[PEG_TRACE_STOP]");
e.ok_or("")
}
pub rule toplevel() -> Toplevel = traced()
}}
```
The above is the recommended way *if you're maintaining the grammar* and want
to be able to turn on pegviz support anytime.
If you're debugging someone else's parser, you may want to print the start/stop
markers and the source yourself, around the parser invocation, like so:
```rust
let source = std::fs::read_to_string(&source).unwrap();
println!("[PEG_INPUT_START]\n{}\n[PEG_TRACE_START]", source);
let res = lang_c::driver::parse_preprocessed(&config, source);
println!("[PEG_TRACE_STOP]");
```
Make sure you've installed `pegviz` into your `$PATH`:
```shell
cd pegviz/
cargo install --force --path .
```
> While installing it, you may notice `pegviz` depends on `peg`.
> That's right! It's using a PEG to analyze PEG traces.
Then, simply run your program with the `trace` Cargo feature enabled, and
pipe its standard output to `pegviz`.
```shell
cd example/
cargo run --features trace | pegviz --output ./pegviz.html
```
Note that the `--output` argument is mandatory.
The last step is to open the resulting HTML file in a browser and click around!
## License
pegviz is released under the MIT License. See the LICENSE file for details.