https://github.com/fierycod/node.jsstreams-vs-clojurechannels
Quick comparison between the Clojure/Golang channels and Node.js streams.
https://github.com/fierycod/node.jsstreams-vs-clojurechannels
clojure clojurescript nodejs
Last synced: about 1 year ago
JSON representation
Quick comparison between the Clojure/Golang channels and Node.js streams.
- Host: GitHub
- URL: https://github.com/fierycod/node.jsstreams-vs-clojurechannels
- Owner: FieryCod
- License: epl-1.0
- Created: 2018-08-07T10:21:40.000Z (almost 8 years ago)
- Default Branch: master
- Last Pushed: 2018-09-25T22:52:07.000Z (almost 8 years ago)
- Last Synced: 2025-06-21T17:03:05.203Z (about 1 year ago)
- Topics: clojure, clojurescript, nodejs
- Language: JavaScript
- Homepage:
- Size: 2.41 MB
- Stars: 1
- Watchers: 2
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# Node.js Streams vs Golang/Clojure Channels
- [Intro](#org372ec54)
- [Development & PR's](#orgbe08ee5)
- [Task](#org0a43089)
- [Benchmark](#org22f1157)
- [Memory usage](#org37133312)
- [Event loop](#org37133313)
- [Summary](#org31233122)
## Intro
Here you can find the comparision between channels and streams.
I will focus on provide pros & cons of both and rationale why do I think certain option wins.
_Images were generated using `.report` files and the [plot.ly](http://plot.ly/)._
_Now the compiled version of a program is available in `/bin` directory. Run `node bin/exec.js` to check it out :) :rocket: :tada: :rocket:_
## Development & PR's
1. Install the [Leiningen](https://leiningen.org/) via brew:
```
brew install leiningen
```
2. Install [Yarn](https://yarnpkg.com/en/docs/install#mac-stable) via brew or npm:
```
brew install yarn
```
3. Install all dependencies:
```
yarn && lein deps
```
4. Compile Cljs files (You can modify the `settings.cljs` to increase the number of iterations):
```
lein cljsbuild once prod
```
It might take a while :rocket:
5. Run `yarn prod` to get possible options :tada: :tada: :tada:
## Task
The task is to take all numbers from the `seeds.file` and process it as follows.
1. *Split (according to [fizz-buzz](http://wiki.c2.com/?FizzBuzzTest) test) the dataset to four datasets and store the count of each:* (Task #1)
- fizz-numbers – A
- buzz-numbers – B
- fizzbuzz-numbers – C
- other numbers – D
2. *Then these four datasets should be processed with the lowest possible memory allocation:* (Task #2)
| Dataset | Processing formula |
|---------|--------------------------------------------------|
| A | Group per 3 numbers e.g '(3 6 9) -> A1 |
| B | Group per 5 numbers e.g '(5 10 15 20 25) -> B1 |
| C | Group per 15 numbers e.g '(15 30 45 60 75) -> C1 |
| D | Do not group |
3. *For each A1, B1, C1 process group one by one and for each create a string* `Group x: ${GroupContent}`.
*The new datasets should consist of those strings:* (Task #3)
| Dataset | Processing formula |
|---------|----------------------------------------------------|
| A1 | "Group 1: '(3 6 9)\n", "Group 2: '(9 12 18)" -> A2 |
| B1 | Same as above -> B2 |
| C1 | Same as above -> C2 |
| D1 | As you can see that dataset is not processed -> D1 |
4. *Create 4 files for dataset and do the following:* (Task #4)
- Inject all strings for each datasets from (Task #3)
- For ending string inject `There was ${CountCounter} numbers processed for stream ${stream_name}`
- Print to the console how long the program took
## Benchmark
I've run each option 10 times for 1 000 000 numbers and here are the results:
| Streams (ms) | Streams with transform | Channels (ms) |
|--------------|------------------------|---------------|
| 26605.116539 | 29765.362489 | 28164.848514 |
| 25203.411413 | 29565.812846 | 27396.837127 |
| 24620.778972 | 29096.130312 | 27092.127704 |
| 24807.708090 | 28733.805155 | 27081.614445 |
| 24309.594895 | 29778.777752 | 26725.460214 |
| 24692.114949 | 29347.474361 | 26583.327855 |
| 24727.354629 | 26343.177867 | 26437.005529 |
| 25258.414988 | 24942.121680 | 26623.881638 |
| 24900.780390 | 29382.791624 | 26476.086182 |
| 25318.520212 | 35954.707085 | 26557.018727 |
Whole program took:
| Streams (ms) | Streams with transform | Channels (ms) |
|---------------|------------------------|---------------|
| 250451.349866 | 292918.246961 | 269150.369399 |
Channels are about 20 sec slower in the benchmark than Streams (about 2-3 seconds slower in each execution compared to streams).
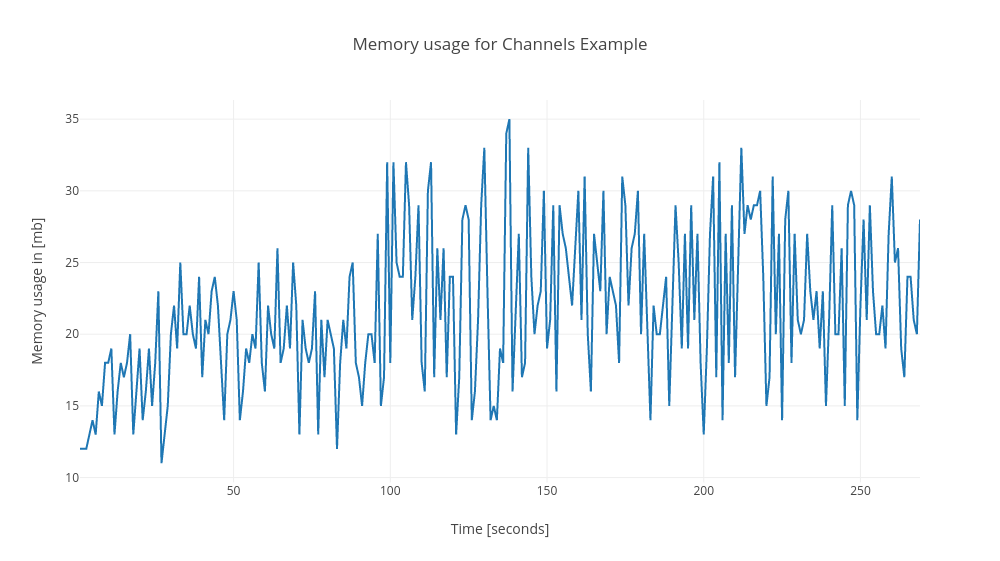
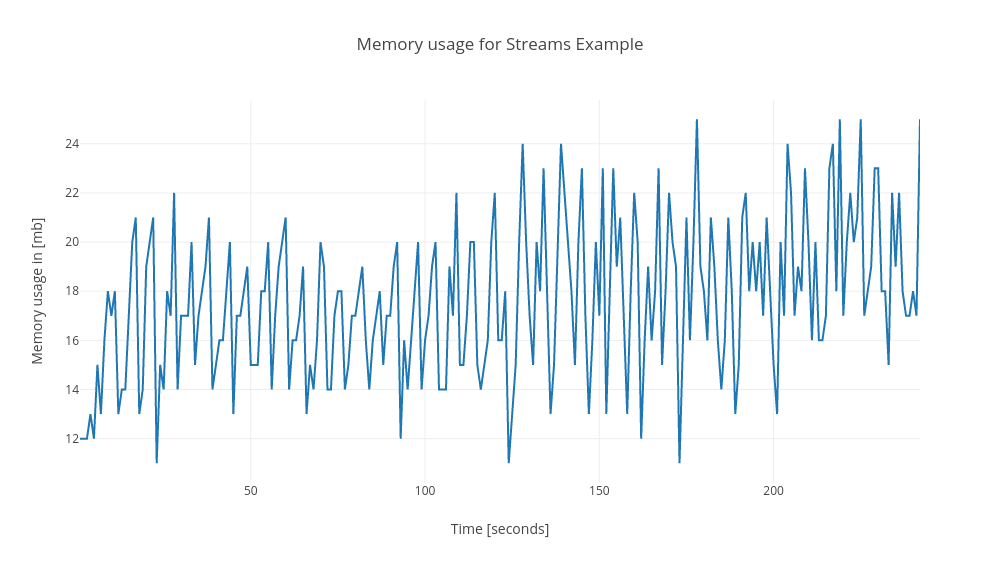
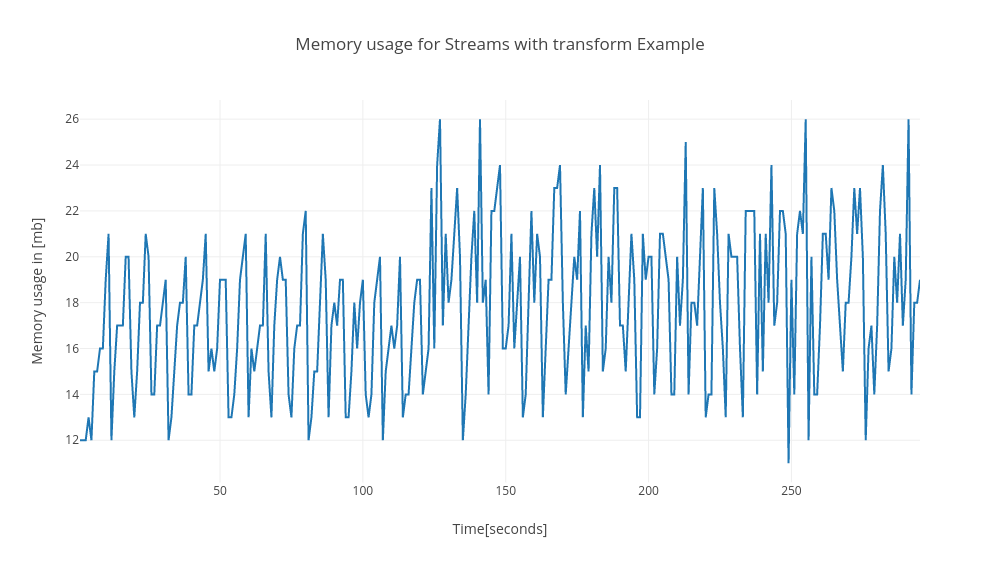
## Memory Usage
Memory usage changes in each execution. Sometimes the Channels allocate 10mb more than Streams sometimes only 4mb more. But in general channels allocate more memory. I think that the main cause of this is that I got the buffered channel for others.
Channels
Streams
Streams with transform
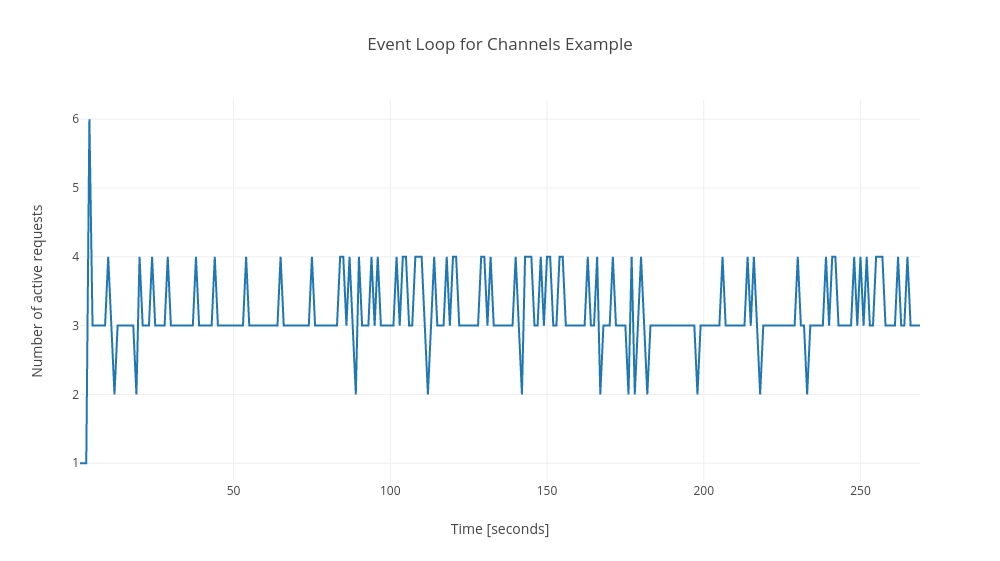
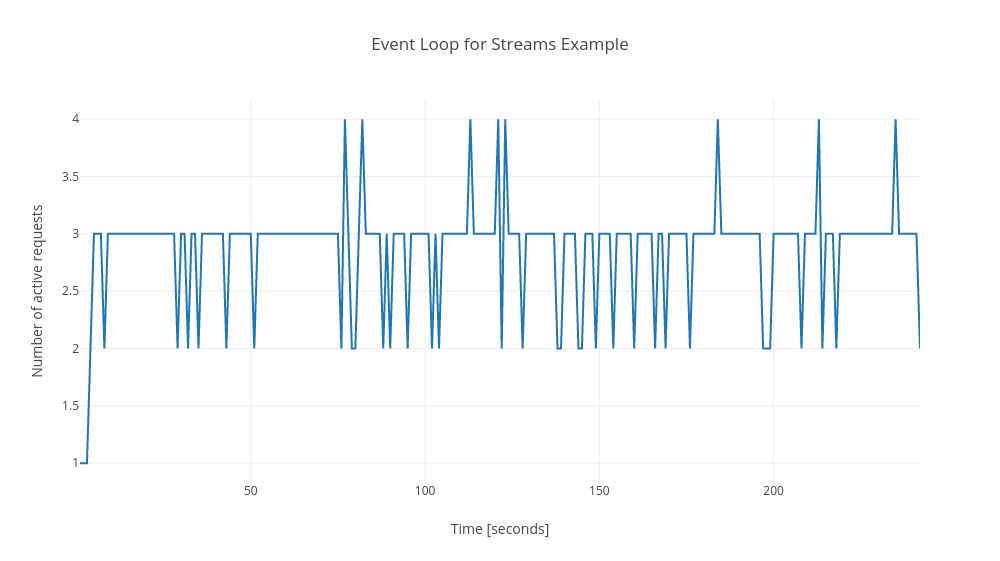
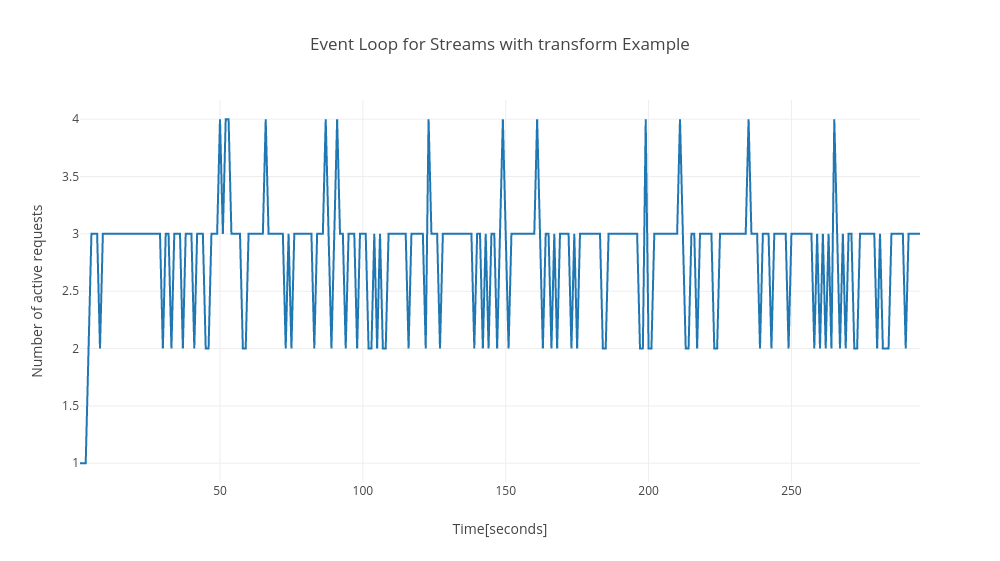
## Event loop
Channels always got 2 more requests to event loop then streams. In my opinion the values for both examples are low and satisfactory. These 2 more requests are not relevant in my opinion.
Channels
Streams
Streams with transform
## Summary
### Streams & Streams with transform
| Pros | Cons |
|-----------------------------------------|-------------------------------------------------------------------|
| Fewer memory usage than in Channels | Couples logic with the source |
| Fewer Event Loop requests than Channels | Very imperative approach (even stream Transformer won't help) |
| Lower execution time than Channels | Mutations, mutations everywhere. Updates on state are not atomic. |
| | Hard to test transformation in separation |
### Channels
| Pros | Cons |
|-------------------------------------------------------------|--------------------------------------------------------|
| Does not couple the logic at all | About 3-10mb more memory usage than streams |
| Fewer Event Loop requests than Channels | About 2-3 more Event Loop requests |
| Mutation is atomic | Higher execution time about 2-3s per program execution |
| Concise and easy to understand code | |
| Easier to cordinate async stuff | |
| Use of composable transducers | |
| Quite clean, FP code therefore easier to mantain and extend | |
| Easy to test every single transformation | |