https://github.com/fivetran/dbt_zendesk
Fivetran's Zendesk Support dbt package
https://github.com/fivetran/dbt_zendesk
dbt dbt-packages fivetran zendesk
Last synced: 4 months ago
JSON representation
Fivetran's Zendesk Support dbt package
- Host: GitHub
- URL: https://github.com/fivetran/dbt_zendesk
- Owner: fivetran
- License: apache-2.0
- Created: 2020-04-21T03:37:12.000Z (about 6 years ago)
- Default Branch: main
- Last Pushed: 2026-03-31T21:26:00.000Z (4 months ago)
- Last Synced: 2026-03-31T21:33:59.239Z (4 months ago)
- Topics: dbt, dbt-packages, fivetran, zendesk
- Language: Shell
- Homepage: https://fivetran.github.io/dbt_zendesk/#!/overview
- Size: 6.57 MB
- Stars: 30
- Watchers: 42
- Forks: 30
- Open Issues: 20
-
Metadata Files:
- Readme: README.md
- Changelog: CHANGELOG.md
- License: LICENSE
Awesome Lists containing this project
README
# Zendesk dbt Package
This dbt package transforms data from Fivetran's Zendesk connector into analytics-ready tables.
## Resources
- Number of materialized models¹: 82
- Connector documentation
- [Zendesk connector documentation](https://fivetran.com/docs/connectors/applications/zendesk)
- [Zendesk ERD](https://fivetran.com/docs/connectors/applications/zendesk#schemainformation)
- dbt package documentation
- [GitHub repository](https://github.com/fivetran/dbt_zendesk)
- [dbt Docs](https://fivetran.github.io/dbt_zendesk/#!/overview)
- [DAG](https://fivetran.github.io/dbt_zendesk/#!/overview?g_v=1)
- [Changelog](https://github.com/fivetran/dbt_zendesk/blob/main/CHANGELOG.md)
- dbt Core™ supported versions
- `>=1.3.0, <3.0.0`
## What does this dbt package do?
This package enables you to better understand the performance of your Support team and analyze ticket velocity over time. It creates enriched models with metrics focused on response times, resolution times, and work times.
### Output schema
Final output tables are generated in the following target schema:
```
._zendesk
```
### Final output tables
By default, this package materializes the following final tables:
| Table | Description |
| :---- | :---- |
| [zendesk__ticket_metrics](https://fivetran.github.io/dbt_zendesk/#!/model/model.zendesk.zendesk__ticket_metrics) | Analyzes support team performance with metrics on reply times, resolution times, and total work times. Supports both calendar and business hours for flexible reporting.
**Example Analytics Questions:**
- What is the average first reply time for tickets by priority level or support team?
- How do resolution times compare across different ticket channels or customer segments?
- Which agents or groups have the longest work times relative to their ticket volume?
| [zendesk__ticket_enriched](https://fivetran.github.io/dbt_zendesk/#!/model/model.zendesk.zendesk__ticket_enriched) | Provides complete context for every ticket including assignees, requesters, organizations, groups, and tags to understand relationships and patterns across the support operation.
**Example Analytics Questions:**
- Which tags or ticket categories generate the most support volume?
- How are tickets distributed across assignees, groups, and organizations?
- What types of requesters or organizations submit the highest-priority tickets?
| [zendesk__ticket_summary](https://fivetran.github.io/dbt_zendesk/#!/model/model.zendesk.zendesk__ticket_summary) | A high-level overview providing aggregate statistics about the entire support operation, including total tickets, active users, and key volume metrics.
**Example Analytics Questions:**
- What is the total volume of tickets and active users across the support system?
- How many tickets are currently open versus resolved?
- What percentage of tickets are being handled by active agents?
| [zendesk__ticket_backlog](https://fivetran.github.io/dbt_zendesk/#!/model/model.zendesk.zendesk__ticket_backlog) | A daily snapshot of all open tickets (excluding closed, deleted, or solved), showing how ticket properties change over time for backlog analysis and trend monitoring.
**Example Analytics Questions:**
- How has the backlog size changed over time by status, priority, or assignee?
- Which groups or agents consistently carry the largest backlog?
- Are there seasonal trends or spikes in open ticket volume?
| [zendesk__ticket_field_history](https://fivetran.github.io/dbt_zendesk/#!/model/model.zendesk.zendesk__ticket_field_history) | A daily historical record tracking how ticket properties evolve throughout their lifecycle, including status changes, reassignments, and priority updates, along with who made each change.
**Example Analytics Questions:**
- How long do tickets spend in each status before moving to the next stage?
- How frequently are tickets reassigned between agents or groups?
- What is the typical lifecycle progression of tickets by priority or type?
| [zendesk__sla_policies](https://fivetran.github.io/dbt_zendesk/#!/model/model.zendesk.zendesk__sla_policies) | Tracks SLA compliance and breach metrics for every policy event to help monitor whether tickets meet service level targets in both calendar and business hours.
**Example Analytics Questions:**
- What percentage of tickets are breaching their SLA targets by policy type?
- Which teams or agents have the highest SLA compliance rates?
- How do SLA breach rates differ between business hours and calendar hours?
| [zendesk__document](https://fivetran.github.io/dbt_zendesk/#!/model/model.zendesk.zendesk__document) | Prepares ticket text content for AI and machine learning applications by segmenting it into optimized chunks for vectorization, sentiment analysis, topic modeling, or automated categorization. Disabled by default.
**Example Analytics Questions:**
- What are the most common topics or themes in customer support tickets?
- How can we categorize ticket content for automated routing or tagging?
- Which text patterns correlate with high-priority or escalated tickets?
¹ Each Quickstart transformation job run materializes these models if all components of this data model are enabled. This count includes all staging, intermediate, and final models materialized as `view`, `table`, or `incremental`.
---
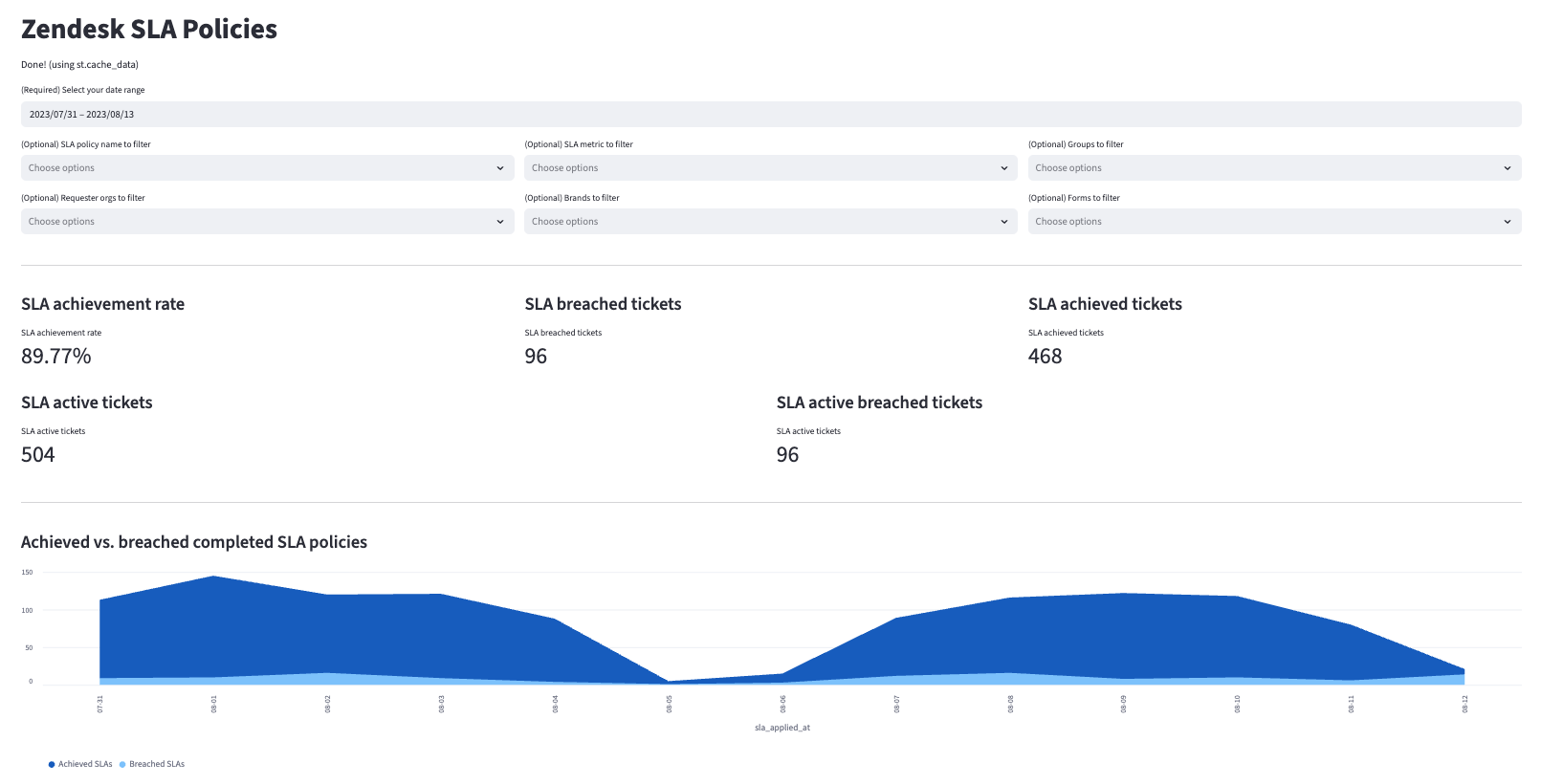
## Visualizations
Many of the above reports are now configurable for [visualization via Streamlit](https://github.com/fivetran/streamlit_zendesk). Check out some [sample reports here](https://fivetran-zendesk.streamlit.app/).
## Prerequisites
To use this dbt package, you must have the following:
- At least one Fivetran Zendesk connection syncing data into your destination.
- A **BigQuery**, **Snowflake**, **Redshift**, **PostgreSQL**, or **Databricks** destination.
## How do I use the dbt package?
You can either add this dbt package in the Fivetran dashboard or import it into your dbt project:
- To add the package in the Fivetran dashboard, follow our [Quickstart guide](https://fivetran.com/docs/transformations/data-models/quickstart-management).
- To add the package to your dbt project, follow the setup instructions in the dbt package's [README file](https://github.com/fivetran/dbt_zendesk/blob/main/README.md#how-do-i-use-the-dbt-package) to use this package.
### Install the package
Include the following zendesk package version in your `packages.yml` file:
> TIP: Check [dbt Hub](https://hub.getdbt.com/) for the latest installation instructions or [read the dbt docs](https://docs.getdbt.com/docs/package-management) for more information on installing packages.
```yml
packages:
- package: fivetran/zendesk
version: [">=1.5.0", "<1.6.0"]
```
> All required sources and staging models are now bundled into this transformation package. Do not include `fivetran/zendesk_source` in your `packages.yml` since this package has been deprecated.
#### Databricks Dispatch Configuration
If you are using a Databricks destination with this package you will need to add the below (or a variation of the below) dispatch configuration within your `dbt_project.yml`. This is required in order for the package to accurately search for macros within the `dbt-labs/spark_utils` then the `dbt-labs/dbt_utils` packages respectively.
```yml
dispatch:
- macro_namespace: dbt_utils
search_order: ['spark_utils', 'dbt_utils']
```
### Define database and schema variables
#### Option A: Single connection
By default, this package runs using your destination and the `zendesk` schema. If this is not where your zendesk data is (for example, if your zendesk schema is named `zendesk_fivetran`), update the following variables in your root `dbt_project.yml` file accordingly:
```yml
vars:
zendesk_database: your_destination_name
zendesk_schema: your_schema_name
```
> **Note**: When running the package with a single source connection, the `source_relation` column in each model will be populated with an empty string.
#### Option B: Union multiple connections
If you have multiple Zendesk connections in Fivetran and would like to use this package on all of them simultaneously, we have provided functionality to do so. For each source table, the package will union all of the data together and pass the unioned table into the transformations. The `source_relation` column in each model indicates the origin of each record.
To use this functionality, you will need to set the `zendesk_sources` variable in your root `dbt_project.yml` file:
```yml
# dbt_project.yml
vars:
zendesk_sources:
- database: connection_1_destination_name # Required
schema: connection_1_schema_name # Required
name: connection_1_source_name # Required only if following the step in the following subsection
- database: connection_2_destination_name
schema: connection_2_schema_name
name: connection_2_source_name
```
##### Recommended: Incorporate unioned sources into DAG
> *If you are running the package through [Fivetran Transformations for dbt Core™](https://fivetran.com/docs/transformations/dbt#transformationsfordbtcore), the below step is necessary in order to synchronize model runs with your Zendesk connections. Alternatively, you may choose to run the package through Fivetran [Quickstart](https://fivetran.com/docs/transformations/quickstart), which would create separate sets of models for each Zendesk source rather than one set of unioned models.*
By default, this package defines one single-connection source, called `zendesk`, which will be disabled if you are unioning multiple connections. This means that your DAG will not include your Zendesk sources, though the package will run successfully.
To properly incorporate all of your Zendesk connections into your project's DAG:
1. Define each of your sources in a `.yml` file in your project. Utilize the following template for the `source`-level configurations, and, **most importantly**, copy and paste the table and column-level definitions from the package's `src_zendesk.yml` [file](https://github.com/fivetran/dbt_zendesk/blob/main/models/staging/src_zendesk.yml#L15-L351).
```yml
# a .yml file in your root project
sources:
- name: # ex: Should match name in zendesk_sources
schema:
database:
loader: fivetran
loaded_at_field: _fivetran_synced
freshness: # feel free to adjust to your liking
warn_after: {count: 72, period: hour}
error_after: {count: 168, period: hour}
tables: # copy and paste from zendesk/models/staging/src_zendesk.yml - see https://support.atlassian.com/bitbucket-cloud/docs/yaml-anchors/ for how to use anchors to only do so once
```
> **Note**: If there are source tables you do not have (see [Enable/Disable models](https://github.com/fivetran/dbt_zendesk?tab=readme-ov-file#enabledisable-models)), you may still include them, as long as you have set the right variables to `False`. Otherwise, you may remove them from your source definition.
2. In the above `.yml` file, remove the `and var('zendesk_sources', []) == []` condition from the enabled config for the following source tables (if you have the tables in your schemas):
- [`audit_log`](https://github.com/fivetran/dbt_zendesk/blob/main/models/staging/src_zendesk.yml#L20)
- [`brand`](https://github.com/fivetran/dbt_zendesk/blob/main/models/staging/src_zendesk.yml#L115)
- [`domain_name`](https://github.com/fivetran/dbt_zendesk/blob/main/models/staging/src_zendesk.yml#L135)
- [`organization_tag`](https://github.com/fivetran/dbt_zendesk/blob/main/models/staging/src_zendesk.yml#L164)
- [`organization`](https://github.com/fivetran/dbt_zendesk/blob/main/models/staging/src_zendesk.yml#L174)
- [`user_tag`](https://github.com/fivetran/dbt_zendesk/blob/main/models/staging/src_zendesk.yml#L242)
- [`schedule`](https://github.com/fivetran/dbt_zendesk/blob/main/models/staging/src_zendesk.yml#L295)
- [`ticket_form_history`](https://github.com/fivetran/dbt_zendesk/blob/main/models/staging/src_zendesk.yml#L327)
- [`schedule_holiday`](https://github.com/fivetran/dbt_zendesk/blob/main/models/staging/src_zendesk.yml#L406)\
- [`ticket_chat`](https://github.com/fivetran/dbt_zendesk/blob/main/models/staging/src_zendesk.yml#424)
- [`ticket_chat_event`](https://github.com/fivetran/dbt_zendesk/blob/main/models/staging/src_zendesk.yml#L458)
3. Set the `has_defined_sources` variable (scoped to the `zendesk` package) to `True`, like such:
```yml
# dbt_project.yml
vars:
zendesk:
has_defined_sources: true
```
### Enable/Disable models
> _This step is optional if you are unioning multiple connections together in the previous step. The `union_data` macro will create empty staging models for sources that are not found in any of your Zendesk schemas/databases. However, you can still leverage the below variables if you would like to avoid this behavior._
This package takes into consideration that not every Zendesk Support account utilizes the `schedule`, `schedule_holiday`, `ticket_schedule`, `daylight_time`, `time_zone`, `audit_log`, `domain_name`, `user_tag`, `brand`,`organization`, `organization_tag`, `ticket_form_history`, `ticket_chat`, `ticket_chat_event`, `sla_policy_metric_history`, or `ticket_sla_policy` features, and allows you to disable the corresponding functionality.
By default, all variables' values are assumed to be `true`, except for `using_audit_log` and `using_ticket_chat`. Add variables for only the tables you want to enable/disable:
```yml
vars:
using_ticket_chat: True #Enable if you are using ticket_chat or ticket_chat_event
using_audit_log: True #Enable if you are using audit_log for schedule and/or user_role histories
using_schedule_histories: False #Used in conjunction with using_audit_log. Set to false to disable schedule histories with audit_log.
using_user_role_histories: False #Used in conjunction with using_audit_log. Set to false to disable user_role histories with audit_log.
using_sla_policy_metric_history: False #Disable if you are using sla_policy_metric_history
using_ticket_sla_policy: False #Disable if you are using ticket_sla_policy
using_schedules: False #Disable if you are not using schedules, which requires source tables ticket_schedule, daylight_time, and time_zone
using_holidays: False #Disable if you are not using schedule_holidays for holidays
using_domain_names: False #Disable if you are not using domain names
using_user_tags: False #Disable if you are not using user tags
using_ticket_form_history: False #Disable if you are not using ticket form history
using_brands: False #Disable if you are not using brands
using_organizations: False #Disable if you are not using organizations. Setting this to False will also disable organization tags.
using_organization_tags: False #Disable if you are not using organization tags
```
### (Optional) Additional configurations
Expand/Collapse details
#### Enabling the unstructured document model for NLP
This package includes the `zendesk__document` model, which processes and segments Zendesk text data for vectorization, making it suitable for NLP workflows. The model outputs structured chunks of text with associated document IDs, segment indices, and token counts. For definitions and more information, refer to [zendesk__document](https://fivetran.github.io/dbt_zendesk/#!/model/model.zendesk.zendesk__document) in our dbt docs.
By default, this model is disabled. To enable it, update the `zendesk__unstructured_enabled` variable to true in your dbt_project.yml:
```yml
vars:
zendesk__unstructured_enabled: true # false by default.
```
##### Customizing Chunk Size for Vectorization
The `zendesk__document` model was developed to limit approximate chunk sizes to 5,000 tokens, optimized for OpenAI models. However, you can adjust this limit by setting the `max_tokens` variable in your `dbt_project.yml`:
```yml
vars:
zendesk_max_tokens: 5000 # Default value
```
### Add passthrough columns
This package includes all source columns defined in the macros folder. You can add more columns from the `TICKET`, `USER`, and `ORGANIZATION` tables using our pass-through column variables.
These variables allow for the pass-through fields to be aliased (`alias`) and casted (`transform_sql`) if desired, but not required. Datatype casting is configured via a sql snippet within the `transform_sql` key. You may add the desired sql while omitting the `as field_name` at the end and your custom pass-through fields will be casted accordingly. Use the below format for declaring the respective pass-through variables:
```yml
vars:
zendesk__ticket_passthrough_columns:
- name: "account_custom_field_1" # required
alias: "account_1" # optional
transform_sql: "cast(account_1 as string)" # optional, must reference the alias if an alias is provided (otherwise the original name)
- name: "account_custom_field_2"
transform_sql: "cast(account_custom_field_2 as string)"
- name: "account_custom_field_3"
zendesk__user_passthrough_columns:
- name: "internal_app_id_c"
alias: "app_id"
zendesk__organization_passthrough_columns:
- name: "custom_org_field_1"
```
> Note: Earlier versions of this package employed a more rudimentary format for passthrough columns, in which the user provided a list of field names to pass in, rather than a mapping. In the above `ticket` example, this would be `[account_custom_field_1, account_custom_field_2, account_custom_field_3]`.
>
> This old format will still work, as our passthrough-column macros are all backwards compatible.
#### Mark Custom User Roles as Agents
If a team member leaves your organization and their internal account is deactivated, their `USER.role` will switch from `agent` or `admin` to `end-user`. This can skew historical ticket SLA metrics, since reply times and other calculations are based on `agent` or `admin` activity only.
To preserve the integrity of historical SLAs:
- **If audit logs are NOT enabled** (var `using_audit_log` is false):
Use the `internal_user_criteria` variable to define a SQL clause that identifies internal users based on fields in the `USER` table. This logic is applied via a `CASE WHEN` in the `stg_zendesk__user` model.
- **If audit logs and user role history ARE enabled** (vars `using_audit_log` and `using_user_role_histories` are true):
Historical user roles will be imported. You can further control which roles are treated as internal by using the same `internal_user_criteria` variable. It will be evaluated as a boolean (`TRUE`/`FALSE`) in the `is_internal_role` field of the `int_zendesk__user_role_history` model. Note that `agent` and `admin` roles are always treated as internal by default, and your custom logic will be applied in addition to this.
This configuration can also be used more broadly to classify what counts as an agent for any reporting or analytical use case. For more details, see the corresponding [DECISIONLOG](https://github.com/fivetran/dbt_zendesk/blob/main/DECISIONLOG.md#user-role-history) entry.
Example usage:
```yml
# dbt_project.yml
vars:
zendesk:
internal_user_criteria: "lower(email) like '%@fivetran.com' or external_id = '12345' or name in ('Garrett', 'Alfredo')" # can reference any non-custom field in USER
```
#### Tracking Ticket Field History Columns
The `zendesk__ticket_field_history` model generates historical data for the columns specified by the `ticket_field_history_columns` variable. By default, the columns tracked are `status`, `priority`, and `assignee_id`. If you would like to change these columns, add the following configuration to your `dbt_project.yml` file. Additionally, the `zendesk__ticket_field_history` model allows for tracking the specified fields updater information through the use of the `zendesk_ticket_field_history_updater_columns` variable. The values passed through this variable are limited to the values shown within the config below. By default, the variable is empty and updater information is not tracked. If you would like to track field history updater information, add any of the below specified values to your `dbt_project.yml` file. After adding the columns to your root `dbt_project.yml` file, run the `dbt run --full-refresh` command to fully refresh any existing models.
```yml
vars:
ticket_field_history_columns: ['the','list','of','column','names']
ticket_field_history_updater_columns: [
'updater_user_id', 'updater_name', 'updater_role', 'updater_email', 'updater_external_id', 'updater_locale',
'updater_is_active', 'updater_user_tags', 'updater_last_login_at', 'updater_time_zone',
'updater_organization_id', 'updater_organization_domain_names' , 'updater_organization_organization_tags'
]
```
*Note: This package only integrates the above ticket_field_history_updater_columns values. If you'd like to include additional updater fields, please create an [issue](https://github.com/fivetran/dbt_zendesk/issues) specifying which ones.*
#### Extending and Limiting the Ticket Field History
This package will create a row in `zendesk__ticket_field_history` for each day that a ticket is open, starting at its creation date. A Zendesk Support ticket cannot be altered after being closed, so its field values will not change after this date. However, you may want to extend a ticket's history past its closure date for easier reporting and visualizing. To do so, add the following configuration to your root `dbt_project.yml` file:
```yml
# dbt_project.yml
vars:
zendesk:
ticket_field_history_extension_months: integer_number_of_months # default = 0
```
Conversely, you may want to only track the past X years of ticket field history. This could be for cost reasons, or because you have a BigQuery destination and have over 4,000 days (10-11 years) of data, leading to a `too many partitions` error in the package's incremental models. To limit the ticket field history to the most recent X years, add the following configuration to your root `dbt_project.yml` file:
```yml
# dbt_project.yml
vars:
zendesk:
ticket_field_history_timeframe_years: integer_number_of_years # default = 50 (everything)
```
#### Configuring Maximum Ticket Length
By default, this package assumes that tickets will not remain open for longer than 52 weeks (1 year). This assumption is used in business hour calculations and SLA policy computations to generate the appropriate number of week intervals for time-based calculations.
If your organization has tickets that may remain open longer than 52 weeks, you may adjust this limit by configuring the `max_ticket_length_weeks` variable in your root `dbt_project.yml` file:
```yml
# dbt_project.yml
vars:
zendesk:
max_ticket_length_weeks: 208 # Integer value: Ensure this is >= the longest period a ticket was open (in weeks). Default = 52 weeks (1 year)
```
#### Changing the Build Schema
By default this package will build the Zendesk Support staging models within a schema titled ( + `_zendesk_source`), the Zendesk Support intermediate models within a schema titled ( + `_zendesk_intermediate`), and the Zendesk Support final models within a schema titled ( + `_zendesk`) in your target database. If this is not where you would like your modeled Zendesk Support data to be written to, add the following configuration to your root `dbt_project.yml` file:
```yml
models:
zendesk:
+schema: my_new_schema_name # Leave +schema: blank to use the default target_schema.
intermediate:
+schema: my_new_schema_name # Leave +schema: blank to use the default target_schema.
staging:
+schema: my_new_schema_name # Leave +schema: blank to use the default target_schema.
```
#### Change the source table references
If an individual source table has a different name than the package expects, add the table name as it appears in your destination to the respective variable:
> IMPORTANT: See this project's [`dbt_project.yml`](https://github.com/fivetran/dbt_zendesk/blob/main/dbt_project.yml) variable declarations to see the expected names.
```yml
vars:
zendesk__identifier: your_table_name
```
### (Optional) Orchestrate your models with Fivetran Transformations for dbt Core™
Expand for details
Fivetran offers the ability for you to orchestrate your dbt project through [Fivetran Transformations for dbt Core™](https://fivetran.com/docs/transformations/dbt#transformationsfordbtcore). Learn how to set up your project for orchestration through Fivetran in our [Transformations for dbt Core setup guides](https://fivetran.com/docs/transformations/dbt/setup-guide#transformationsfordbtcoresetupguide).
## Does this package have dependencies?
This dbt package is dependent on the following dbt packages. These dependencies are installed by default within this package. For more information on the following packages, refer to the [dbt hub](https://hub.getdbt.com/) site.
> IMPORTANT: If you have any of these dependent packages in your own `packages.yml` file, we highly recommend that you remove them from your root `packages.yml` to avoid package version conflicts.
```yml
packages:
- package: fivetran/fivetran_utils
version: [">=0.4.0", "<0.5.0"]
- package: dbt-labs/dbt_utils
version: [">=1.0.0", "<2.0.0"]
- package: dbt-labs/spark_utils
version: [">=0.3.0", "<0.4.0"]
```
## How is this package maintained and can I contribute?
### Package Maintenance
The Fivetran team maintaining this package only maintains the [latest version](https://hub.getdbt.com/fivetran/zendesk/latest/) of the package. We highly recommend you stay consistent with the latest version of the package and refer to the [CHANGELOG](https://github.com/fivetran/dbt_zendesk/blob/main/CHANGELOG.md) and release notes for more information on changes across versions.
### Contributions
A small team of analytics engineers at Fivetran develops these dbt packages. However, the packages are made better by community contributions.
We highly encourage and welcome contributions to this package. Learn how to contribute to a package in dbt's [Contributing to an external dbt package article](https://discourse.getdbt.com/t/contributing-to-a-dbt-package/657).
### Opinionated Modelling Decisions
This dbt package takes an opinionated stance on how business time metrics are calculated. The dbt package takes **all** schedules into account when calculating the business time duration. Whereas, the Zendesk Support UI logic takes into account **only** the latest schedule assigned to the ticket. If you would like a deeper explanation of the logic used by default in the dbt package you may reference the [DECISIONLOG](https://github.com/fivetran/dbt_zendesk/blob/main/DECISIONLOG.md).
## Are there any resources available?
- If you have questions or want to reach out for help, see the [GitHub Issue](https://github.com/fivetran/dbt_zendesk/issues/new/choose) section to find the right avenue of support for you.
- If you would like to provide feedback to the dbt package team at Fivetran or would like to request a new dbt package, fill out our [Feedback Form](https://www.surveymonkey.com/r/DQ7K7WW).