https://github.com/fla-org/flash-bidirectional-linear-attention
Triton implement of bi-directional (non-causal) linear attention
https://github.com/fla-org/flash-bidirectional-linear-attention
computer-vision machine-learning-systems triton-lang
Last synced: 5 months ago
JSON representation
Triton implement of bi-directional (non-causal) linear attention
- Host: GitHub
- URL: https://github.com/fla-org/flash-bidirectional-linear-attention
- Owner: fla-org
- License: mit
- Created: 2024-11-20T15:14:53.000Z (over 1 year ago)
- Default Branch: main
- Last Pushed: 2025-02-04T07:05:46.000Z (over 1 year ago)
- Last Synced: 2025-02-04T08:19:11.602Z (over 1 year ago)
- Topics: computer-vision, machine-learning-systems, triton-lang
- Language: Python
- Homepage:
- Size: 78.1 KB
- Stars: 40
- Watchers: 2
- Forks: 1
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# Flash Bi-directional Linear Attention
The aim of this repository is to implement **bi-directional linear attention** for **non-causal** modeling using Triton.
This project is currently maintained by an individual and remains a work in progress. As the maintainer is still in the early stages of learning Triton, many implementations may not be optimal. **Contributions and suggestions are welcome!**
# Update
* [2025-02-04] Updated PolaFormer
* [2024-12-30] Optimized the backpropagation speed of the `linear attn`.
* [2024-12-28] Updated `simple_la`, which is a simple form of `linear_attn` without the norm term.
# Models
Roughly sorted according to the timeline supported in FBi-LA
| Year | Model | Title | Paper | Code | `fla` impl |
| :------ | :-------- | :--------------------------------------------------------------------- | :---------------------------------------: | :-----------------------------------------------------------: | :------------------------------------------------------------------------------------------------------------------: |
| 2024 | Linfusion | LinFusion: 1 GPU, 1 Minute, 16K Image | [arxiv](https://arxiv.org/abs/2409.02097) | [official](https://github.com/Huage001/LinFusion) | [code](https://github.com/hp-l33/flash-bidirectional-linear-attention/blob/main/fbi_la/layers/linfusion.py) |
| 2024 | MLLA | Demystify Mamba in Vision: A Linear Attention Perspective | [arxiv](https://arxiv.org/abs/2405.16605) | [official](https://github.com/LeapLabTHU/MLLA) | [code](https://github.com/hp-l33/flash-bidirectional-linear-attention/blob/main/fbi_la/layers/mlla.py) |
| 2023 | Focused-LA| FLatten Transformer: Vision Transformer using Focused Linear Attention | [arxiv](https://arxiv.org/abs/2308.00442) | [official](https://github.com/LeapLabTHU/FLatten-Transformer) | [code](https://github.com/hp-l33/flash-bidirectional-linear-attention/blob/main/fbi_la/layers/focused_la.py) |
| 2025 | PolaFormer| PolaFormer: Polarity-aware Linear Attention for Vision Transformers | [arxiv](https://arxiv.org/abs/2501.15061) | [official](https://github.com/ZacharyMeng/PolaFormer) | [code](https://github.com/hp-l33/flash-bidirectional-linear-attention/blob/main/fbi_la/layers/polaformer.py) |
More models will be implemented gradually.
# Usage
## Installation
``` shell
git clone https://github.com/fla-org/flash-bidirectional-linear-attention.git
pip install -e flash-bidirectional-linear-attention/.
```
## Integrated Models
This library has integrated some models, which can be called directly. Taking [LinFusion](https://github.com/Huage001/LinFusion) as an example:
``` python
import torch
from diffusers import AutoPipelineForText2Image
from fbi_la.models import LinFusion
sd_repo = "Lykon/dreamshaper-8"
pipeline = AutoPipelineForText2Image.from_pretrained(
sd_repo, torch_dtype=torch.float16, variant="fp16"
).to(torch.device("cuda"))
linfusion = LinFusion.construct_for(pipeline)
image = pipeline(
"An astronaut floating in space. Beautiful view of the stars and the universe in the background.",
generator=torch.manual_seed(123)
).images[0]
```
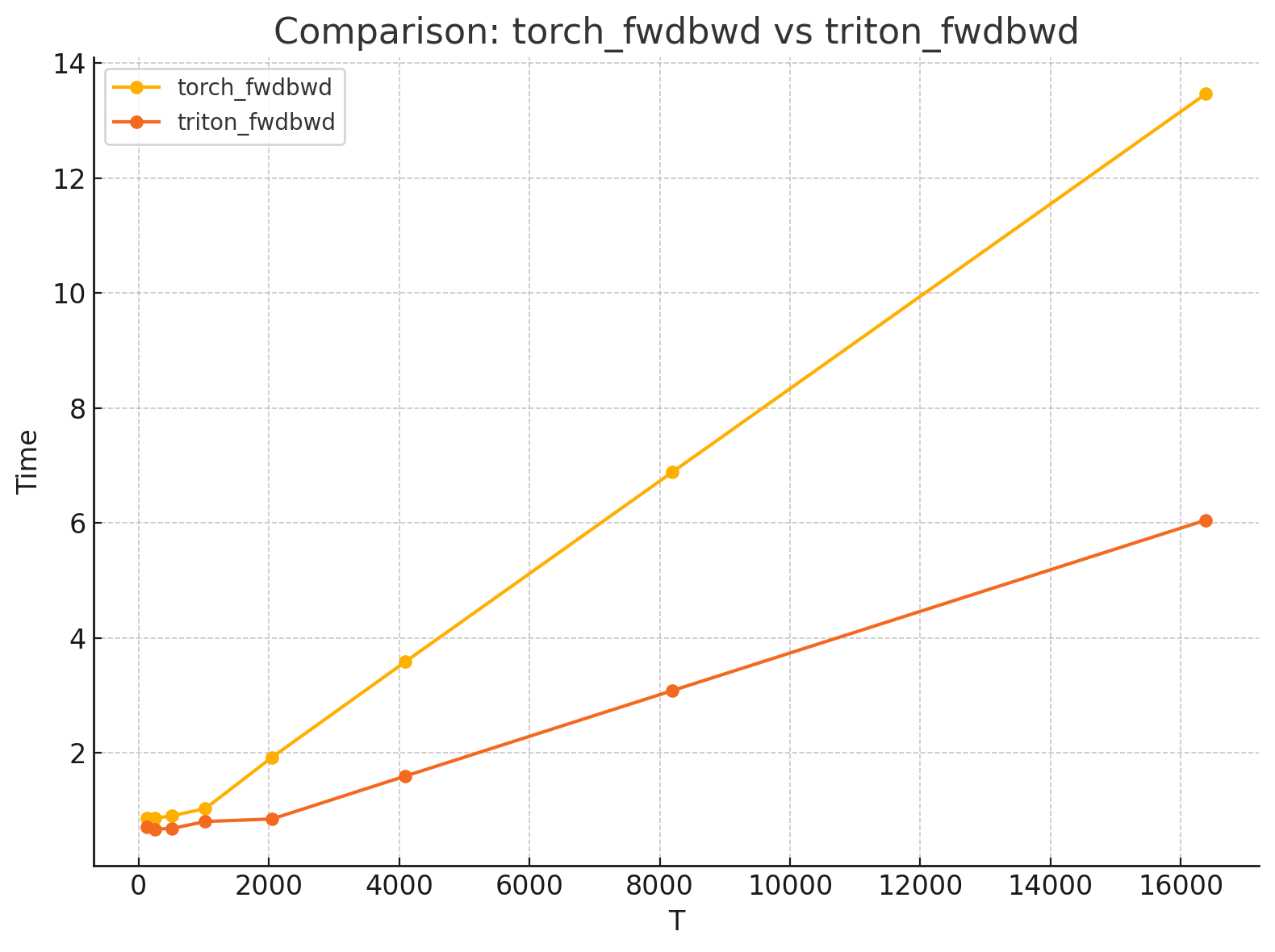
# Benchmarks
Tested on an A800 80G GPU.
``` shell
B8-H16-D64:
T torch_fwd triton_fwd torch_bwd triton_bwd
0 128.0 0.063488 0.049152 0.798720 0.651264
1 256.0 0.080896 0.056320 0.796672 0.625664
2 512.0 0.111616 0.058368 0.798720 0.630784
3 1024.0 0.169984 0.090112 0.864256 0.719872
4 2048.0 0.300032 0.151552 1.624064 0.702464
5 4096.0 0.532480 0.276480 3.058176 1.324032
6 8192.0 1.005568 0.521216 5.880320 2.556928
7 16384.0 1.924608 0.980992 11.540992 5.022208
```
# TODO
- improve memory efficiency during backpropagation
- implement more models
- VSSD
- RALA
# Acknowledgments
Thanks to the following repositories for their inspiration:
- [flash-attention](https://github.com/Dao-AILab/flash-attention)
- [flash-linear-attention](https://github.com/sustcsonglin/flash-linear-attention)