https://github.com/flairox/kinetix
Reinforcement learning on general 2D physics environments in JAX. ICLR 2025 Oral.
https://github.com/flairox/kinetix
machine-learning physics-engine reinforcement-learning
Last synced: 11 months ago
JSON representation
Reinforcement learning on general 2D physics environments in JAX. ICLR 2025 Oral.
- Host: GitHub
- URL: https://github.com/flairox/kinetix
- Owner: FLAIROx
- License: mit
- Created: 2024-11-06T15:51:31.000Z (over 1 year ago)
- Default Branch: main
- Last Pushed: 2025-07-24T02:14:15.000Z (about 1 year ago)
- Last Synced: 2025-08-31T12:29:04.472Z (11 months ago)
- Topics: machine-learning, physics-engine, reinforcement-learning
- Language: Python
- Homepage: https://kinetix-env.github.io/
- Size: 18.3 MB
- Stars: 206
- Watchers: 7
- Forks: 9
- Open Issues: 2
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README







### Update: Kinetix was accepted at ICLR 2025 as an oral!
# Kinetix
Kinetix is a framework for reinforcement learning in a 2D rigid-body physics world, written entirely in [JAX](https://github.com/jax-ml/jax).
Kinetix can represent a huge array of physics-based tasks within a unified framework.
We use Kinetix to investigate the training of large, general reinforcement learning agents by procedurally generating millions of tasks for training.
You can play with Kinetix in our [online editor](https://kinetix-env.github.io/gallery.html?editor=true), or have a look at the JAX [physics engine](https://github.com/MichaelTMatthews/Jax2D) and [graphics library](https://github.com/FLAIROx/JaxGL) we made for Kinetix. Finally, see our [docs](./docs/README.md) for more information and more in-depth examples.
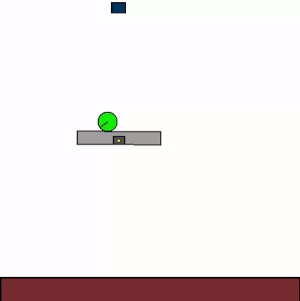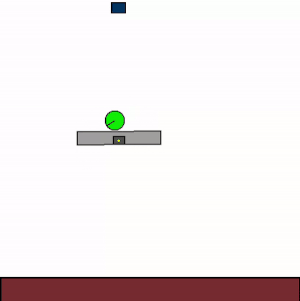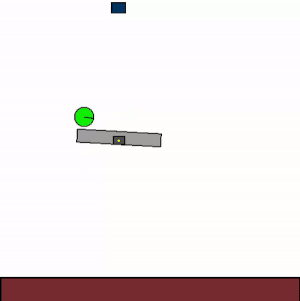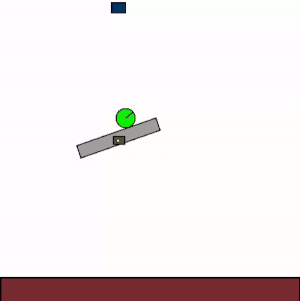
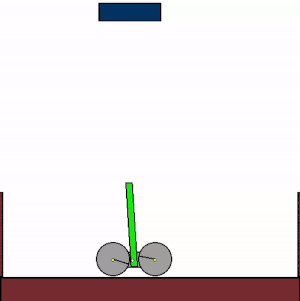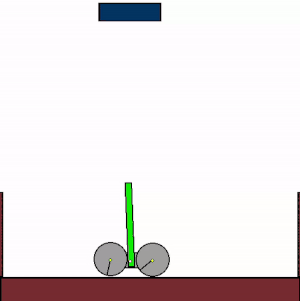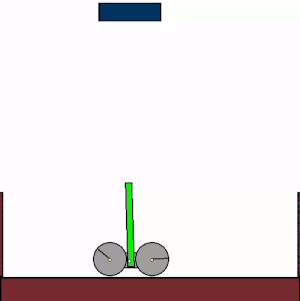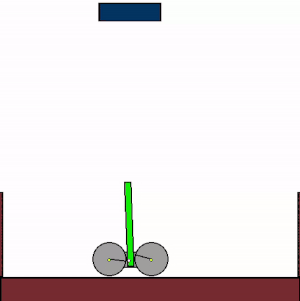
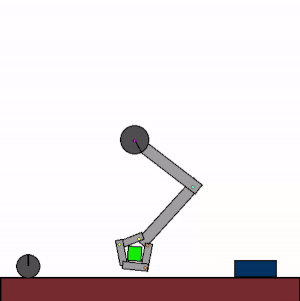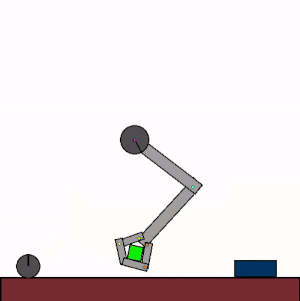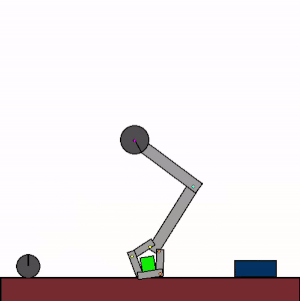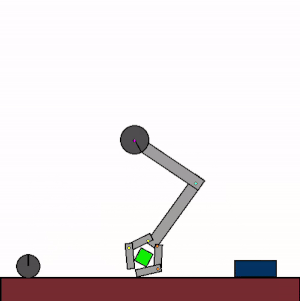



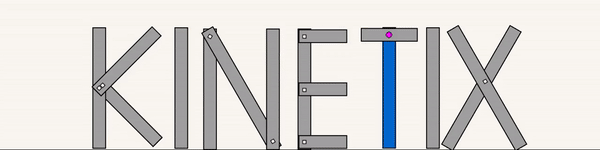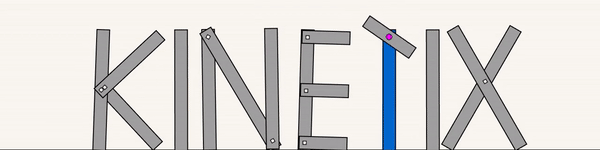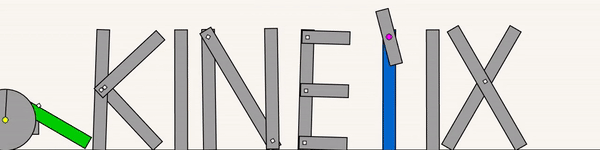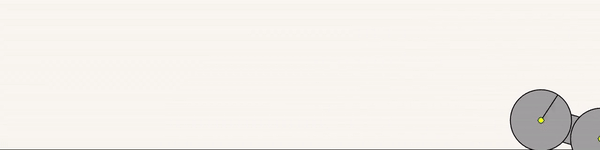
The above shows specialist agents trained on their respective levels.
# 📊 Paper TL; DR
We train a general agent on millions of procedurally generated physics tasks.
Every task has the same goal: make the green and blue touch, without green touching red.
The agent can act through applying torque via motors and force via thrusters.






The above shows a general agent zero-shotting unseen randomly generated levels.
We then investigate the transfer capabilities of this agent to unseen handmade levels.
We find that the agent can zero-shot simple physics problems, but still struggles with harder tasks.

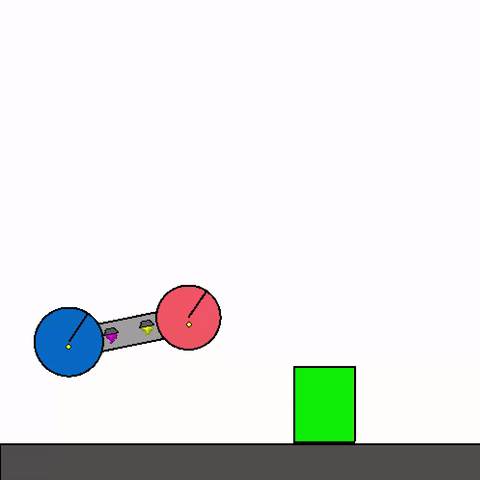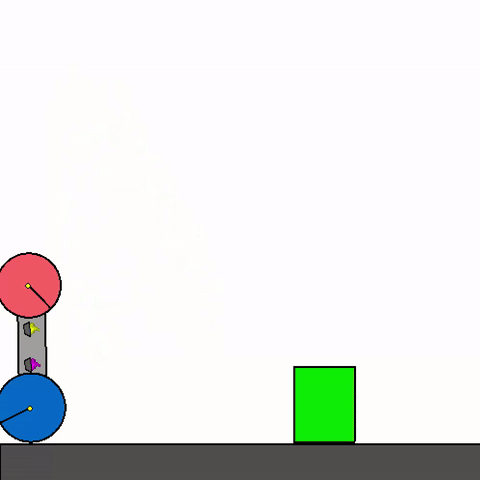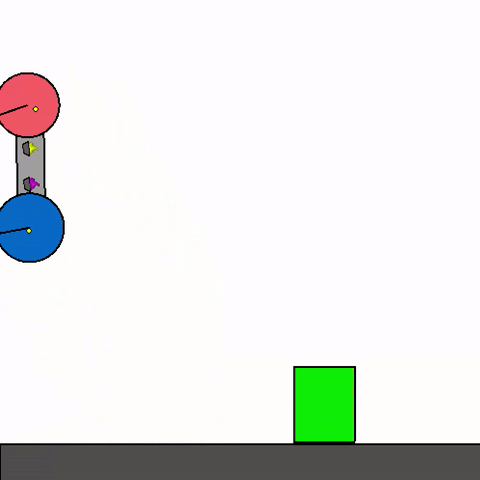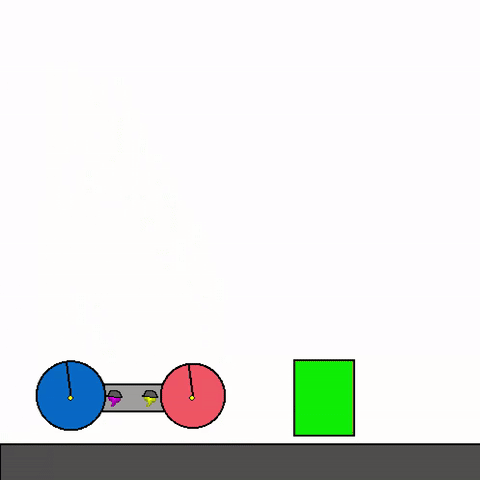

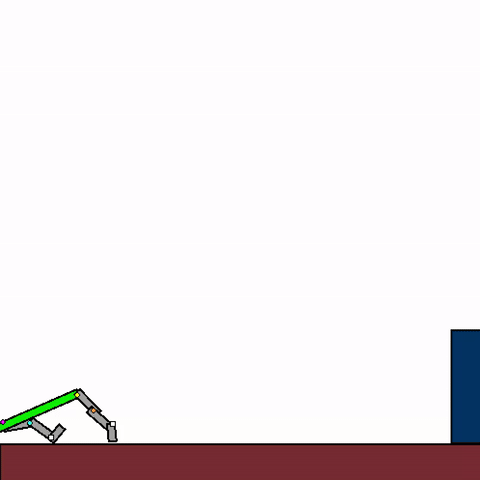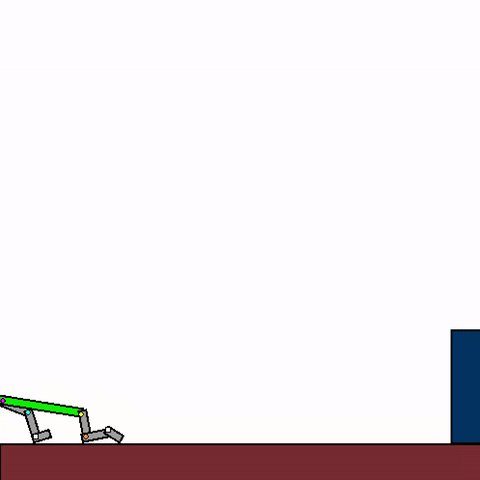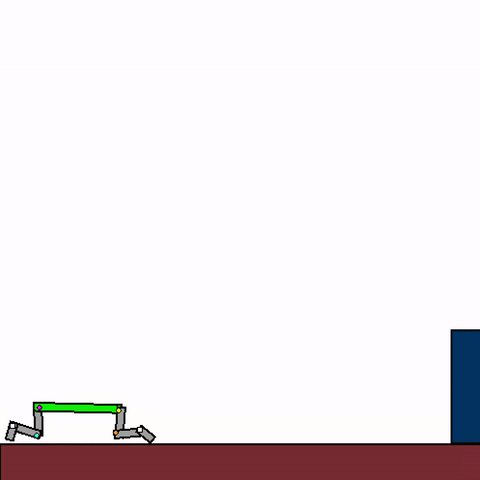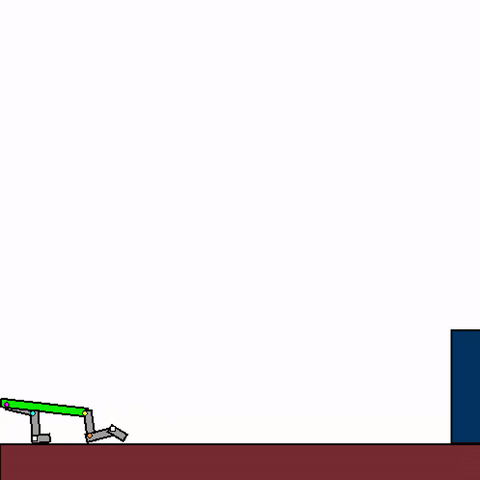

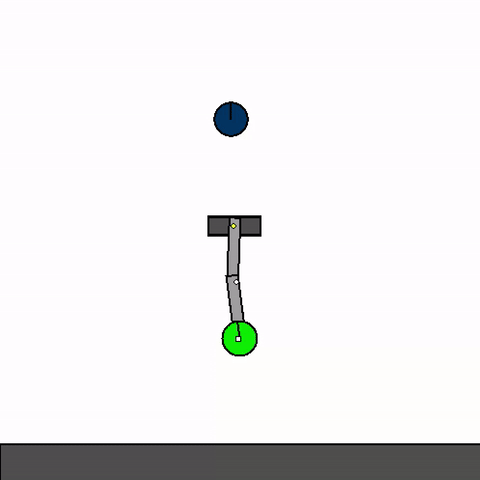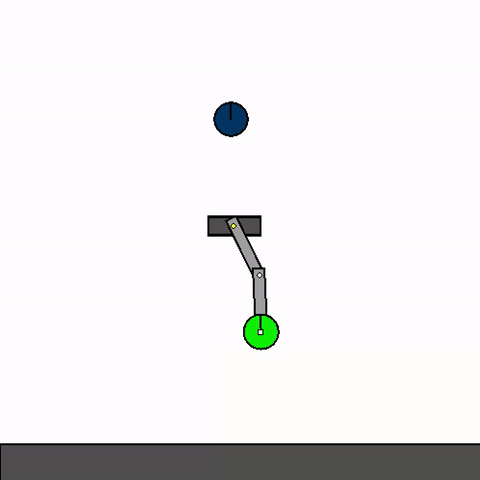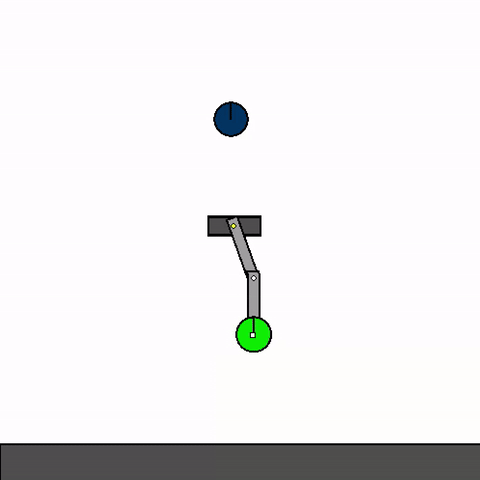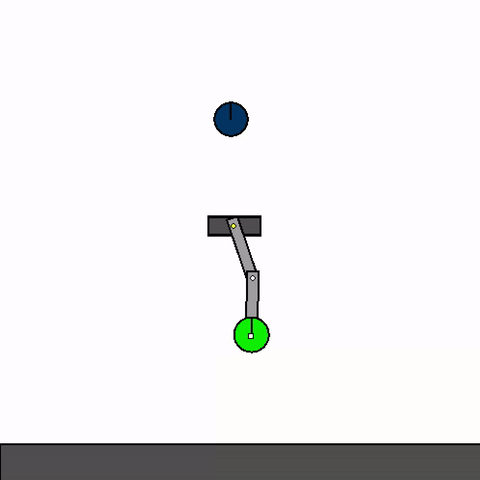
The above shows a general agent zero-shotting unseen handmade levels.
# 📜 Basic Usage
Kinetix follows the interface established in [gymnax](https://github.com/RobertTLange/gymnax):
```python
# Use default parameters
env_params = EnvParams()
static_env_params = StaticEnvParams()
# Create the environment
env = make_kinetix_env(
observation_type=ObservationType.PIXELS,
action_type=ActionType.CONTINUOUS,
reset_fn=make_reset_fn_sample_kinetix_level(env_params, static_env_params),
env_params=env_params,
static_env_params=static_env_params,
)
# Reset the environment state (this resets to a random level)
_rngs = jax.random.split(jax.random.PRNGKey(0), 3)
obs, env_state = env.reset(_rngs[0], env_params)
# Take a step in the environment
action = env.action_space(env_params).sample(_rngs[1])
obs, env_state, reward, done, info = env.step(_rngs[2], env_state, action, env_params)
# Render environment
renderer = make_render_pixels(env_params, env.static_env_params)
pixels = renderer(env_state)
plt.imshow(pixels.astype(jnp.uint8).transpose(1, 0, 2)[::-1])
plt.show()
```
# ⬇️ Installation
To install Kinetix (tested with python3.10):
```commandline
git clone https://github.com/FlairOx/Kinetix.git
cd Kinetix
pip install -e ".[dev]"
pre-commit install
```
Please see [here](https://docs.jax.dev/en/latest/installation.html) to install jax for your accelerator.
> [!TIP]
> Setting `export JAX_COMPILATION_CACHE_DIR="$HOME/.jax_cache"` in your `~/.bashrc` helps improve usability by caching the jax compiles.
Kinetix is also available on [PyPi](https://pypi.org/project/kinetix-env/), and can be installed using `pip install kinetix-env`
# 🎯 Editor
We recommend using the [KinetixJS editor](https://kinetix-env.github.io/gallery.html?editor=true), but also provide a native (less polished) Kinetix editor.
To open this editor run the following command.
```commandline
python3 kinetix/editor.py
```
The controls in the editor are:
- Move between `edit` and `play` modes using `spacebar`
- In `edit` mode, the type of edit is shown by the icon at the top and is changed by scrolling the mouse wheel. For instance, by navigating to the rectangle editing function you can click to place a rectangle.
- You can also press the number keys to cycle between modes.
- To open handmade levels press ctrl-O and navigate to the ones in the L folder.
- **When playing a level use the arrow keys to control motors and the numeric keys (1, 2) to control thrusters.**
# 📈 Experiments
We have three primary experiment files,
1. [**SFL**](https://github.com/amacrutherford/sampling-for-learnability?tab=readme-ov-file): Training on levels with high learnability, this is how we trained our best general agents.
2. **PLR** PLR/DR/ACCEL in the [JAXUED](https://github.com/DramaCow/jaxued) style.
3. **PPO** Normal PPO in the [PureJaxRL](https://github.com/luchris429/purejaxrl/) style.
To run experiments with default parameters run any of the following:
```commandline
python3 experiments/sfl.py
python3 experiments/plr.py
python3 experiments/ppo.py
```
We use [hydra](https://hydra.cc/) for managing our configs. See the `configs/` folder for all the hydra configs that will be used by default, or the [docs](./docs/configs.md).
If you want to run experiments with different configurations, you can either edit these configs or pass command line arguments as follows:
```commandline
python3 experiments/sfl.py model.transformer_depth=8
```
These experiments use [wandb](https://wandb.ai/home) for logging by default.
## 🏋️ Training RL Agents
We provide several different ways to train RL agents, with the three most common options being, (a) [Training an agent on random levels](#training-on-random-levels), (b) [Training an agent on a single, hand-designed level](#training-on-a-single-hand-designed-level) or (c) [Training an agent on a set of hand-designed levels](#training-on-a-set-of-hand-designed-levels).
> [!WARNING]
> Kinetix has three different environment sizes, `s`, `m` and `l`. When running any of the scripts, you have to set the `env_size` option accordingly, for instance, `python3 experiments/ppo.py train_levels=random env_size=m` would train on random `m` levels.
> It will give an error if you try and load large levels into a small env size, for instance `python3 experiments/ppo.py train_levels=m env_size=s` would error.
### Training on random levels
This is the default option, but we give the explicit command for completeness
```commandline
python3 experiments/ppo.py train_levels=random
```
### Training on a single hand-designed level
> [!NOTE]
> Check the `kinetix/levels/` folder for handmade levels for each size category. By default, the loading functions require a relative path to the `kinetix/levels/` directory
```commandline
python3 experiments/ppo.py train_levels=s train_levels.train_levels_list='["s/h4_thrust_aim.json"]'
```
### Training on a set of hand-designed levels
```commandline
python3 experiments/ppo.py train_levels=s env_size=s eval=eval_auto
# python3 experiments/ppo.py train_levels=m env_size=m eval=eval_auto
# python3 experiments/ppo.py train_levels=l env_size=l eval=eval_auto
```
Or, on a custom set:
```commandline
python3 experiments/ppo.py eval=eval_auto train_levels=l env_size=l train_levels.train_levels_list='["s/h2_one_wheel_car","l/h11_obstacle_avoidance"]'
```
# ❌ Errata
- The left wall was erroneously misplaced 5cm to the left in all levels and all experiments in the paper (each level is a square with side lengths of 5 metres). This error has been fixed in the latest version of Jax2D, but we have pinned Kinetix to the old version for consistency and reproducability with the original paper.
Further improvements have been made, so if you wish to reproduce the paper's results, please use kinetix version 0.1.0, which is tagged on github.
# 🔎 See Also
- 🌐 [Kinetix.js](https://github.com/Michael-Beukman/Kinetix.js) Kinetix reimplemented in Javascript, with a live demo [here](https://kinetix-env.github.io/gallery.html?editor=true).
- 🍎 [Jax2D](https://github.com/MichaelTMatthews/Jax2D) The physics engine we made for Kinetix.
- 👨💻 [JaxGL](https://github.com/FLAIROx/JaxGL) The graphics library we made for Kinetix.
- 📋 [Our Paper](https://arxiv.org/abs/2410.23208) for more details and empirical results.
# 🙏 Acknowledgements
The permutation invariant MLP model that is now default was added by [Anya Sims](https://github.com/anyasims).
Thanks to [Thomas Foster](https://github.com/thomfoster) for fixing some macOS specific issues.
We'd also like to thank to Thomas Foster, Alex Goldie, Matthew Jackson, Sebastian Towers and Andrei Lupu for useful feedback.
# 📚 Citation
If you use Kinetix in your work, please cite it as follows:
```
@article{matthews2024kinetix,
title={Kinetix: Investigating the Training of General Agents through Open-Ended Physics-Based Control Tasks},
author={Michael Matthews and Michael Beukman and Chris Lu and Jakob Foerster},
booktitle={The Thirteenth International Conference on Learning Representations},
year={2025},
url={https://arxiv.org/abs/2410.23208}
}
```