https://github.com/foxitsoftware/pdf_ua-2
ISO 14289-2 (PDF/UA-2) significantly improves accessibility of PDF. Foxit's PoC implementation of various PDF creation and consumption tools
https://github.com/foxitsoftware/pdf_ua-2
Last synced: 3 months ago
JSON representation
ISO 14289-2 (PDF/UA-2) significantly improves accessibility of PDF. Foxit's PoC implementation of various PDF creation and consumption tools
- Host: GitHub
- URL: https://github.com/foxitsoftware/pdf_ua-2
- Owner: foxitsoftware
- Created: 2024-01-04T15:03:53.000Z (over 2 years ago)
- Default Branch: main
- Last Pushed: 2025-10-17T07:18:27.000Z (8 months ago)
- Last Synced: 2025-10-18T10:21:29.501Z (8 months ago)
- Language: HTML
- Size: 1.66 MB
- Stars: 1
- Watchers: 5
- Forks: 0
- Open Issues: 6
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
### TL;DR
This repository outlines Foxit's Proof of Concept (PoC) implementation for creating and consuming PDF/UA-2 files, aiming to achieve interoperability and ensure end users have the same experience when consuming these files through Assistive Technology (AT) tools. In this case we focus on MathML.
### Background
PDF/UA-2 files are normal PDF files provided by extra information that assistive software (like JAWS or NVDA) can use. This "extra information" are TAGs which tell things like: this is heading, this is a table with 3 columns or this is an image. In this Proof of Concept we cover math formulas that are much more complex and requires special handling. By covering math formulas we mean that formulas are accessible to assistive technology by:
- using \ elements or
- using associated file that delivers
### What is MathML
- MathML is the digital language that allows computers and assistive technologies to understand the meaning of an equation, not just show a picture of it.
- MathML is an important part of the PDF/UA-2 standard because it ensures that all mathematical content within a document is accessible and fully understood by assistive technologies
### PDF/UA-2 — PDF for Universal Accessibility, ver. 2, ISO 14289-2
PDF/UA-2 is the set of precise technical rules that ensure that tagging is done correctly and consistently.
Key points of PDF/UA-2:
- Enhanced Accessibility
-- It offers a more robust technical framework than its predecessor to ensure people using assistive technology can reliably access and interact with document content.
- Semantic Information
-- The standard introduces comprehensive requirements for structure element attributes, enabling a richer, machine-readable understanding of the document's logical meaning, not just its visual layout.
- Compatibility with WCAG
-- PDF/UA-2 is designed to work as a companion to the Web Content Accessibility Guidelines (WCAG), helping organizations meet broader, content-specific legal accessibility mandates.
- New Tags and Features
-- It incorporates new PDF 2.0-specific elements, like improved handling of mathematical notation (MathML) and better support for annotations, leading to more inclusive digital documents.
### Foxit's PoC implementation of various PDF creation and consumption tools
We provide [Installer](installer/README.md) for our PoC implementations.
The [PDF Sample files](samples/README.md) we produced to achieve interoperability.
We are testing several AI approaches to help with automatic math recognition as a part of remediation processes. The results of our discoveries can be found here:
[Recognition](recognition/README.md)
If you are interested in interoperable testing, have comments, or want to report a bug or suggestion, please use the Issues feature on GitHub.
### PDF 2.0 and PDF/UA-2 features
The ISO 32000-2:2020 (PDF 2.0) specification only provides file format requirements. It should give clear guidance for PDF creation tools. What should and should not be present in the compliant file, but it is not clear how the processor should use all that information. We use this GitHub repository to explain our reasoning with implementations and sample files so we can reach a consensus with other developers. It is essential to give end users the same experience when consuming PDF UA-2 files through AT tools.
The following sections explain our implementation decisions. Feel free to comment.
### MathML
PDF 2.0 in conjunction with PDF/UA-2 recognizes two methods of semantically denote math. Both methods require the use of *Formula* structure element and then:
- Use \ elements in the MathML namespace as direct children or
- the associated MathML data (XML file) in the *AF* property of the structure element
In our PoC we use the second option.
### A sample of a formula and associated file
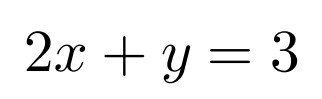
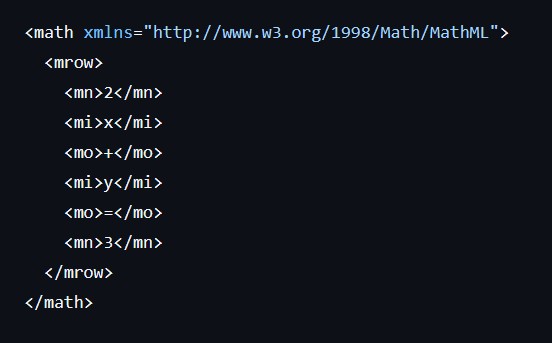
### This is how you can meet MathML in special Foxit Editor build

### Logic in providing Associated file
PDF 2.0 doesn't provide any guidance regarding processors, so it's not specified how a processor should deal with specific scenarios.
Our algorithm when processing PDF files with *AF* is as follows:
For *Formula* structure element:
1. **Search Criteria:**
- Focus only on AFs where `AFRelationship == Supplement` (as per PDF/UA-2).
- Ensure that the `Mediatype` (Subtype key) is `application/mathml+xml`.
- *Note:* The Mediatype comparison is currently a string match, with ongoing discussions in the community about potential variations in the key.
2. **AF Structure Handling:**
- Accept both arrays and directories for AF. While PDF 2.0 officially allows only arrays, some files use AF as a dictionary.
- Only the first element that meets the criteria is used
3. **Fallback Mechanism:**
- If no suitable AF entry is found proceed to process the children (kids) of the structure element.
- If Formula doesn’t have NS == 2.0 then the old processing is used.
4. **Unimplemented Features:**
- `AFRelationship == Alternative` is not yet implemented. The usage of this key is currently under discussion.
5. **Priority Rules:**
- `InlineMath` has priority over `AF`
- `AF` has priority over `Alt`.
- `Alt` has priority over `ActualText`
[//]: # (`ActualText` takes precedence over the processing of the structure element itself.)
6. **Substructure Handling:**
- If the Formula structure element contains a element as a direct child (doesn't have to be the first one), then this substructure is used, and Alternate text (Alt) is ignored.
- If a suitable `AF` is found, process the substructure of the element and provide the content of the stream data as the textual value, i.e. only that content is replaced, not the substructure.
- ~~If `ActualText` is present we ignore AFs and substructure. `ActualText` serves as a full replacement of structure element (this is true for all structure elements. `Formula` is no different)~~
7. **Processing Formula Pseudocode**
```pseudo
IF AF is present AND Namespace == 2.0 AND AFRelationship == Supplement AND Mediatype == application/mathml+xml THEN
// Only the first element that meets the criteria is used
// Process the substructure and provide the stream data content as textual value
Provide stream data content, replacing content but not substructure
ELSE IF Alt is present THEN
// Provide Alt
Provide Alt
ELSE IF ActualText is present THEN
// Ignore AFs and substructures, and provide ActualText
Provide ActualText
ELSE
// Process the substructure of the element
Provide content and process substructure
```
### Rolemap and RolemapNS Processing
Rolemap and RolemapNS Processing are technical rules used by software to correctly interpret the meaning of structural elements within a PDF document, ensuring that content is understandable and accessible, particularly when consumed by Assistive Technology (AT) tools.
These processes act as translation guides, telling the PDF processor how to treat different kinds of tags or elements found in the document, especially those that might be custom or come from sources other than standard PDF specifications.
1. **General Rolemap Handling:**
- Process the `Rolemap` or `RolemapNS` on a Structure Element (SE) in a PDF, regardless of the PDF version.
2. **Namespace (NS) Check:**
- If the SE does **not** have a Namespace (NS), check the `Rolemap`.
- If the SE **does** have an NS and it is other than `PDF 1.7`, `PDF 2.0`, or `MathML`, check `RolemapNS`.
3. **Custom Element Mapping:**
- Allow mapping of a single custom element into two different standard elements based on `RolemapNS`.
4. **Backward Compatibility:**
- If the *Formula* element does not have `NS == 2.0`, then revert to the old processing method. This is our backward-compatible hack since older processors won’t check the NS.
5. **Namespace Flexibility:**
- Elements could be in any namespace (e.g., LaTeX). The discussion of `NS == 2.0` occurs after rolemapping (i.e., `RolemapNS`).