https://github.com/fusyong/ai-proofread-vscode-extension
A VS Code extension for document and book proofreading based on LLM services
https://github.com/fusyong/ai-proofread-vscode-extension
proofreading vscode-extension
Last synced: 3 months ago
JSON representation
A VS Code extension for document and book proofreading based on LLM services
- Host: GitHub
- URL: https://github.com/fusyong/ai-proofread-vscode-extension
- Owner: Fusyong
- License: other
- Created: 2025-03-25T01:49:59.000Z (over 1 year ago)
- Default Branch: main
- Last Pushed: 2026-03-08T12:34:00.000Z (4 months ago)
- Last Synced: 2026-03-08T16:23:14.427Z (4 months ago)
- Topics: proofreading, vscode-extension
- Language: TypeScript
- Homepage:
- Size: 4.85 MB
- Stars: 14
- Watchers: 1
- Forks: 5
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE.md
Awesome Lists containing this project
README
*QQ群“ai-proofreader 校对插件”:1055031650*
一个用于文档和图书校对、基于大语言模型服务的VS Code扩展,支持选中文本直接校对和长文档切分后批量校对两种工作流,并集成了一些跟校对相关的辅助功能。[这里是代码库](https://github.com/Fusyong/ai-proofread-vscode-extension)。本扩展的原型基于一个Python校对工具库[Fusyong/ai-proofread](https://github.com/Fusyong/ai-proofread)。
另外,你也可以设置自己的提示词,用于其他文本处理场景,比如翻译、注释、编写练习题等。
A VS Code extension for document and book proofreading based on LLM services, supporting two workflows: proofreading selected text directly and proofreading long documents after segmentation. [Here is the code repository](https://github.com/Fusyong/ai-proofread-vscode-extension). The prototype of this extension is based on a Python proofreading tool library [Fusyong/ai-proofread](https://github.com/Fusyong/ai-proofread).
Additionally, you can also set your own prompts for other text processing scenarios, such as translation, annotation, creating exercises, and more.
## 1. 安装和必要配置
**本文档仅以Windows系统为例**
1. [安装VS Code](https://blog.xiiigame.com/2022-01-10-给文字工作者的VSCode入门教程/#_1),用VSCode打开一个空文件夹,通过VS Code界面左侧的扩展按钮打开扩展管理窗口(Ctrl+Shift+X)
2. 搜索AI Proofreader,点击安装按钮`install`安装
3. 到大语言模型服务平台(默认为[Deepseek开放平台](https://platform.deepseek.com/)),通过注册、实名认证、充值、生成API秘钥等操作,获得有效的秘钥,复制秘钥
4. 回到AI Proofreader扩展界面,后点击设置按钮⚙️,选中弹出菜单中的设置项Settings,把秘钥粘贴到对应平台的API秘钥框中
## 2. 快速上手
### 2.1. 校对文档中的选段
1. Ctrl+N新建文档,后缀设为`.md`(markdown文档),把你需要校对的文字粘贴到这里,选中其中的一段文字
2. 在所选文字上打开右键菜单,使用其中的`AI proofreader: proofread selection`项校对选中文本
3. 弹出选项对话框时全部回车,即使用默认值
4. 最后会自动展示校对前后的差异,效果如下,深红表示原文变动,深绿表示结果变动:

### 2.2. 切分文档后批量校对
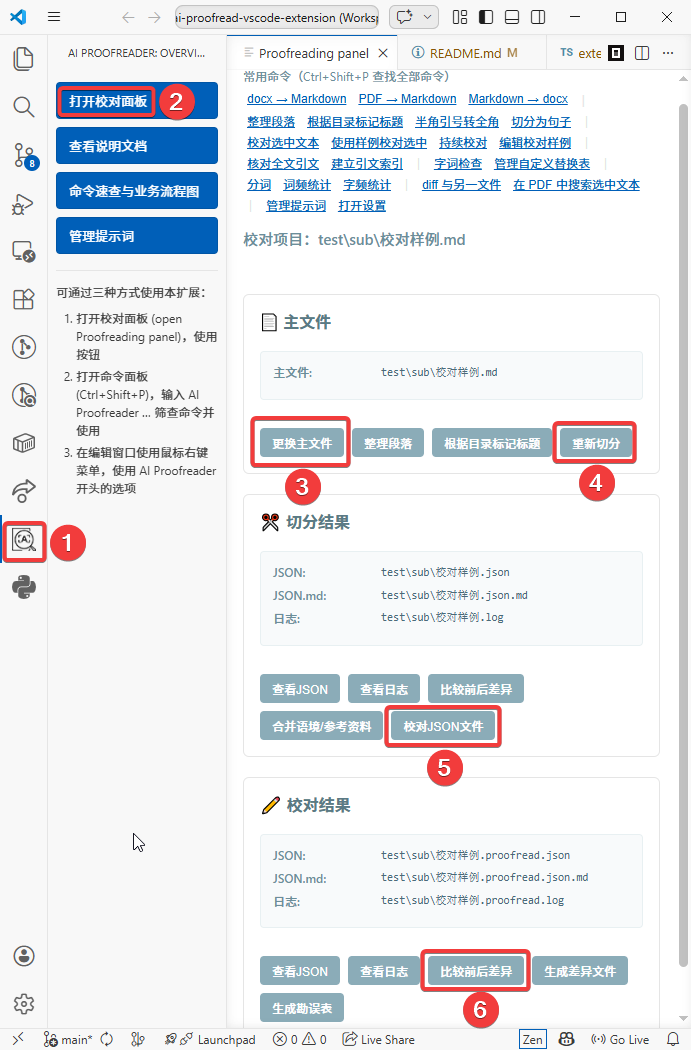
1. 通过左侧活动栏图标的指引,或命令面板中的`open proofreading panel`命令打开校对面板,选择你要校对的主文件——通常是纯文本或markdown格式,并在每一个段落后添加一个空行(一个或多个空行是md的段落标记)作为允许切分的标记
2. 使用切分文件按钮切分文档,选择切分模式(默认按长度),把当前文档切分为JSON文档,结果会呈现在校对面板中
3. 通过校对面板中的“校对JSON文件”按钮,批量校对切分好的片段
4. 通过校对面板中的“比较前后差异”按钮,可以看到和上文相同的校对结果
### 2.3. 尝试所有命令
本扩展可以通过命令面板中的命令、校对面板按钮和文件窗口右键菜单三种形式进行操作。
其中,命令的功能最全。本扩展的所有功能都可以通过命令面板(Ctrl+Shift+P)查找、访问:
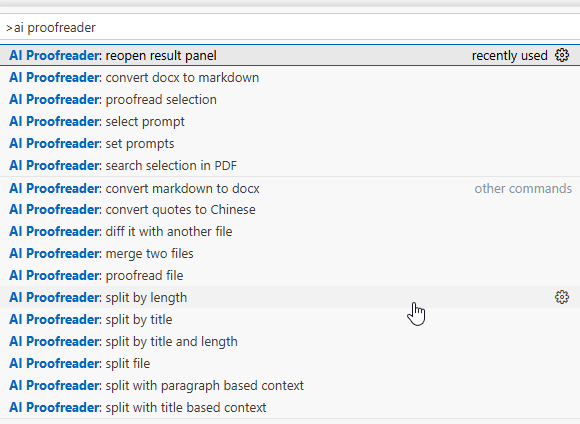
用`open proofreading panel`打开校对面板,也可看到以按钮形式呈现的大多数命令。
打开markdown文件(或选中其中一段文字),或上述切分得到JSON文件,这时可以使用右键菜单访问与文本类型相关的命令,如切分或校对。
更详细的命令速查与业务流程图见[docs/commands-cheatsheet.md](https://github.com/Fusyong/ai-proofread-vscode-extension/blob/main/docs/commands-cheatsheet.md)。
## 3. 使用说明
### 3.1. 文档准备
#### 3.1.1. 转换为Markdown文档
目前作者端稿件多为docx类。排版端可能导出活文字PDF、死文字PDF(文字转曲转光栅,方正书版常见)、方正书版大样文件(常用于过黑马、方正审校)、纯文本(text,多数排版软件能导出)等。
本扩展[默认支持Markdown文档](https://blog.xiiigame.com/2022-01-10-给文字工作者的VSCode入门教程/#vscode_markdown),另支持text、ConTeXt、TeX、LaTeX(**对后三者的支持没有经过充分测试**),其他文档需要先转换为Markdown。此类转换工具很多,本扩展集成了两种。
* **文本文件**只需要把后缀(比如纯文本的`.txt`)改成`.md`即可
* **docx文档**(Word、WPS的通常格式),可以通过命令面板(Ctrl+Shift+P),使用convert docx to Markdown命令转换后进行校。本功能依赖[多功能文档格式转换工具Pandoc](https://pandoc.org/installing.html),需要预先正确安装。安装后可能需要重启才能生效。
* **活文字PDF文档**,可以通过命令面板,使用convert PDF to Markdown命令转换后进行校对。本功能依赖[Xpdf command line tools](https://www.xpdfreader.com/download.html)中的`pdftotext.exe`程序,需手动安装(在“系统变量”的Path中添加其所在路径),交流群备用bat辅助安装程序。安装后可能需要重启才能生效。pdftotext可忽略四周无用文字,如页码、页眉,尺寸单位是磅(pt),五号字是 10.5 pt,x mm = x/25.4*72 pt 。
* **死文字PDF**,需要通过OCR处理成活文字PDF、docx、text、Markdown等后进一步处理。QQ交流群中上传了一个OCR命令行工具rapiddoc.exe。加密码限制提取文字的活文字PDF,也如此处理,或尝试用[SumatraPDF](https://www.sumatrapdfreader.org/free-pdf-reader)打开后复制文字。
* **方正书版大样文档**,如果有方正智能审校工具,用它处理后即为活文字PDF(没有图),再进一步处理。另外,方正书版本身有一些间接导出活文字PDF的办法,但有各种问题,常常比不上用OCR工具处理。
#### 3.1.2. 整理文档
文档转换后还有[一些整理技巧](https://blog.xiiigame.com/2022-01-10-给文字工作者的VSCode入门教程/#vscode),不过对于使用本扩展进行校对而言,进一步的整理工作通常不是必须的。常见的例外情形是,你希望按篇、章、节、标题等结构来切分、校对,以便保持语境连贯,那么你需要学习更多整理技巧,或者使用其他工具,以便得到有标题的Markdown文档。
1. 本扩展命令`mark titles from table of contents`,可以根据一个目录表文件(Markdown分级列表的形式),逐行比较当前文档,把标题行标记出来,会自动忽略数字(如页码)、英文句点和省略号(页码前导符号)、空格、带圈数字①-㉟、Markdown形式的注码如 `[^1] [^abc]`、上标注码如 `^1^ ^abc^`。
2. PDF导出的文本,如果没有使用空行分段,无法切分,可以使用整理段落命令`format paragraphs`中的“段末加空行”选项加以处理。
3. Markdown中的段内断行是合法的,即使句子被断开,对大模型的影响也不大。当然,也可以用上述命令`format paragraphs`中的“删除段内分行”选项处理后再校对。
4. 过多的无效字符影响输出速度,如长串的表格分割线`-`、空格、链接等,可以通过查找替换、Ctrl+Shift+L选中所有相同项目等办法简化、删除。方正系排版软件可能使用半角标点,校对后通常会被改成全角,你也可以使用相同的方法加以替换,避免干扰。请参考上述讲整理技巧的文章。
5. 更强大、通用的文本整理技术是正则表达式查找替换,这需要专门学习,可参考[给编辑朋友的正则表达式课程](https://blog.xiiigame.com/2020-05-31-给编辑朋友的正则表达式课程/)。
!!! caution 批量替换有风险
批量替换的结果可能超出你的预期,即使你不准备原样使用处理后的文本,也有掩盖错误的风险。补强措施是:(一)备份文件。(二)先查找全部,复制到一个新文档中确认无误,然后再进行替换。(三)如果替换逻辑较为复杂,替换后还要比较文件(后文会提到),从头到尾确认所有更改。
#### 3.1.3. 文档切分
我的经验,在一般语言文字和知识校对场景中,大语言模型一次输出六百到八百字会有比较好的效果。因此,一本十来万字的书稿需要切分成三百多段,然后交给大模型校对。
而校对前后一致性,比如多个人名、正文与注释、前后表述的一致性,则需要完整的语境,这时最好按章节切分、校对。
打开markdown文件,在编辑器窗口中打开右键菜单,可以看到切分选项 `AI proofreader: split file`
或通过命令面板查找更具体的选项:
1. **按长度切分** (Split File by Length),可输入目标切分长度(字符数)。
2. **按标题切分** (Split File by Title),可输入标题级别(如:1,2),适合有标题且题下正文长度合适(建议不要超过1500)的文档。
3. **按标题和长度切分** (Split File by Title and Length),适合有标题,但题下正文过长的情况。可配置标题级别、阈值(过大则切分)、切分长度和最小长度(过小则合并)。
4. **按长度切分,以标题范围为上下文** (Split File with Title Based Context),会给每一个片段配上所在标题范围的正文作为上下文,适合对上下文语境要求高的情景。可输入切分长度、题级级别。
> !!! caution 费用警告
> 这样有可能极大地增加token数,增加输入服务费用——尽管在Deepseek等平台中,重复提交的上下文会记为“缓存命中”,并降低费率。注意查看切分后的JSON文档的字符数,以权衡利弊。
5. **按长度切分,扩展前后段落为上下文** (Split File with Paragraph Based Context),即在片段基础上添加前后段落,用作上下文。适合关注局部语境一致性的情形。可输入切分长度、前文段落数和后文段落数。
> !!! caution 费用警告
> 这样可能较大地增加token数,增加输入服务费用。这样生成的上下文是变动的,因此无法享受“缓存命中”的低费率。注意查看切分后的JSON文档的字符数,以权衡利弊。
切分后都会生成同名的 `.json`(用于校对) 和 `.json.md`(可查看切分情况)两个结果文件。
还会生成日志文件(`.log`),记录切分统计信息,并摘要呈现在校对面板中;**如有过长(如超过1500字符)片段时,可以手动加空行分段,然后再次切分。**
校对面板有按钮提示用户选择查看结果的方式:比较前后差异(用分割线表示切分位置)、查看JSON结果或查看日志文件;还有一个校对JSON文件的按钮(面板失效后还可以打开JSON后用右键菜单开始校对)。
!!! note 切分文档依赖两种标记
本扩展默认用户需要校对的文档为[markdown格式](https://www.markdownguide.org/basic-syntax/),文档切分依赖markdown文档中的两种标记:(1)空行。在markdown中,一个或多个空行表示分段,没有空行的断行在渲染时被忽略,即合并为一段。**至少要有合适的空行,否则无法切分。**(2)各级标题。如`## `开头的是二级标题。
还有一个**把文本切分为句子的命令**,split into sentences,可用于整理校对样例等场合。
#### 3.1.4. 合并JSON,组织语境
跟人工校对一样,要想提交校对质量,大语言模型也需要了解上下文语境,还需要工具书、参考资料等。
本扩展每次调用大语言模型时能提交三种文本:**要处理的目标文本(target,必须)、参考资料(reference,可选)、上下文(context,可选)**。比如以一篇文章中的一部分作为target,那么整篇就可以作为context,而在处理中有参考价值的资料,如相关词条,就可以作为reference。
假设你校对一本书,切分后得到包含300个target的JSON文件。那么可以准备相同数量、一一对应的上下文和参考文献,切分成包含相同数量target的JSON文件。然后使用合并命令,将上下文文本中的target作为context合并,将参考文本中的target作为reference合并。
也可以合并一个Markdown文件,比如后面会说到的 `.proofread/examples.md`,即每一个JSON项都合并一次这个文本。
**合并 JSON 文件 (Merge Two Files):**
1. 打开已切分的要校对的 JSON 文件
2. 打开右键菜单,选择`AI proofreader: Merge Two Files`(或通过命令面板)命令
3. 选择要合并的文件
4. 确定要处理的字段和资料来源字段,以及拼接模式或更新(覆盖)模式。比如你想把试题及其答案合并后校对,那么可用拼接模式,拼接到同一个target中。
5. 确定是否更新对应的Markdown文件(默认是),更新时会备份原文件。
组织校对语境是一个看起来有些麻烦,但非常有效的工作。比如校对练习册,有必要把练习和答案拼成语境(拼在一个target中更能节省费用)。而对一首古诗的解释如果不可靠,可以用一篇可靠的作为reference。包含人物的内容,则可以用词典中的任务条目作为reference。
本扩展会逐步增加语境组织功能。
### 3.2. 校对文本选段和JSON文档
#### 3.2.1. 校对Markdown文档中选中的片段
1. 打开Markdown文档(其他纯文本文档可改为.md后缀,即为Markdown文档)
2. 选中要校对的段落,不宜过长
3. 从右键菜单、命令面板(Ctrl+Shift+P)中选择 Proofread Selection
4. 可选择上下文范围、参考文件和温度。加入上下文是为大语言模型提供语境,以便参考,并保持一致性。参考文件可以是相关的词条、更权威的文献等。模型温度较低时,随机性、创造性、稳定性较低;反之则随机性、创造性、不稳定性变高。可以参考模型文档进行测试。**使用不同温度多遍校对,或许可以覆盖不同的问题,值得尝试。**
5. 最后会自动展示校对前后的差异;并生成日志,以便再次查看结果
Proofread Selection命令还有姊妹命令proofread selection with examples,适用于这样的场景:在批量校对前,你可以先尝试校对,并用edit Proofreading examples命令(基于当前的选中文本或diff窗口)打开一个diff窗口,左边是原文,右边是修改后的文本,样例条目之间使用相同的分隔符(如一个空行,即2个分行符),当你保存时会自动把校对结果整理成样例文件`.proofread/examples.md`(你可以手动编辑这个文件)。这时,你就可以通过proofread selection with examples命令自动把样例用作reference供大模型参考。样例文件还可以作为reference合并到要校对的JSON中。
#### 3.2.2. 校对切分好的JSON文档
1. 打开已切分的 JSON 文件
2. 通过右键菜单或命令面板选择Proofread File
3. 显示当前配置请你确认。配置说明见上文。
4. 在校对面板中有进度、结果等信息。可中途取消校对。下次接着校对,会根据校对结果`文档.proofread.json`文件中的记录,跳过已经完成的部分;如果切分结果`文档.json`与校对结果`文档.proofread.json`条目数不一致,则会提示你手动对齐,或删除结果文档,从头重新校对。
5. 最后会提示你查看结果:JSON结果、前后差异、日志文件,以及生成差异文件(类似带修改标记的Word文档)。
6. 如有未完成的条目,可重新校对,重新校对时只处理未完成的条目
#### 3.2.3 持续发现与监督校对(实验功能)
一个半自动的持续工作流。从当前位置开始,自动切分一段并带样例提交LLM校对,**人工复核校对结果**,保存后自动整理校对样例,**人工挑选校对样例**,确认后自动继续下一轮。
1. 打开要校对的文档,将光标置于起始位置
2. 使用命令 `continuous proofread` 或快捷键 `Ctrl+Alt+P` 启动
3. 首次使用需选择切分方式(按长度 / 按标题)、上下文构建方式、温度、提示词重复模式;本流程内自动沿用,终止后配置清除
4. 每段校对完成后会打开 diff 视图,可编辑右侧结果
5.关闭 diff 窗口时会提示「接受并继续」「放弃」和「终止校对」
6. 接受后若有可收集的样例,会弹出勾选界面,每条用 jsdiff 展示变化
7. 确认后自动处理下一段;也可选择「停止持续校对」
### 3.3. 比较(diff)校对前后的文件差异
在当前markdown或json界面,使用右键菜单`diff it with another file`,如果当前是markdown则有三种模式:
1. 调用vscode内置的diff editor比较校对前后md文件。校对面板“前后差异”按钮的功能与此相同。对于长文本,diff editor有段落无法对齐的问题。此时,可以通过加空行或删除空行来帮助对齐。
2. 用jsdiff比较两个文件,生成HTML形式的结果,类似带修改标记的Word文档。本模式还支持JSON文件,自动拼接JSON一级元素或`target`字段内容进行比较,支持每次比较的片段数量(默认0表示所有片段),生成多个有序的差异文件,避免过长文本无法渲染的问题;校对面板“生成差异文件”按钮的功能与此相同(**注意:这个按钮使用的也是JSON中的文本,而不是md中的文本**)。
3. 逐句对齐两个md文件,生成一个有筛选和比较功能的HTML文件,从而可用于制作审校记录、勘误表。校对面板“生成勘误表”按钮的功能与此相同。生成勘误表时可选择**同时收集常用词语错误**,输出为 CSV 格式(错误词语,正确词语,错误词语所在小句,错词长度,正词长度),保存为 `{主文件名}.word-errors.csv`,便于筛选和积累个人常用错词表、自定义替换表。
### 3.4. 管理提示词
#### 3.4.1 提示词管理
**本扩展目前默认提示词的功能是校对一般的语言文字错误和知识性错误**,具体内容见代码库中的proofreader.ts文件。你可以设置自己的提示词,不限于校对工作。
通过命令面板(Ctrl+Shift+P)使用manage prompts命令可以打开提示列表视图,管理提示词。可增、删、改,选择当前使用的提示词。没有编辑界面,请写好后贴入。
也可以在配置文件中处理提示词,但不适合没有编程知识的用户使用。
#### 3.4.2 提示词原理与撰写示范
为了写好提示词,你需要了解本扩展的工作原理:
1. 把你的提示词作为系统命令/系统提示词交给大模型
2. 在第一轮对话中提交`${reference}`和`${context}`;
3. 在第二轮对话中提交`${target}`
4. 接收、处理第二轮对话的输出作为结果
整个过程没有魔法,处理的目的和方法完全由提示词和三种文本及其标签(reference、context、target)来定义。这就是说,**你可以通过自己的提示词,让AI根据三种文本做你期望的任何处理工作,** 比如撰写大意、插图脚本、练习题、注释,绘制图表,注音,翻译,进行专项核查(专名统一性、内容安全、引文、年代、注释等),收集信息(如名词术语)……
需要注意的是,在自定义提示词中,必须对要处理的目标文本(target)、参考资料(reference)、上下文(context)进行说明,如果用不到后两者也可以不说明。并且这种**说明应尽可能与三种标签的字面意义相协调,**比如target可以用作“要处理的目标文本”,也可以用作“要得到的具体目标”(作为系统提示词的补充),但不宜作为参考文本、样例等类。
提示词示例:
> 你是一位专业的儿童文学翻译家……
> 用户会提供一段需要翻译的目标文本(target),你的任务是把这段文本翻译成适合孩子阅读的汉语作品……
>
> 用户如果供参考文本(reference),翻译时请模仿参考文本的语言风格,遵照参考文本中的人名、地名、术语等实体的指定译法……
>
> 用户如果提供上下文(context),翻译时要根据上下文确定目标文本(target)的具体含义,确保翻译的准确性和连贯性……
>
> 输出要求:
> 1. 翻译目标文本(target)后输出;
> 2. 不要给出任何解释、说明;
> 3. ……
本扩展计划预置更多提示词,也欢迎用户通过用户群等渠道交流、分享提示词。
本人有一个[开源提示词库](https://github.com/Fusyong/LLM-prompts-from-a-book-editor),但不是针对本扩展的,改造(对三种标签进行说明)后才能用于本扩展。
#### 3.4.3 提示词输出类型
本扩展支持三种提示词输出类型:full(全文输出);item(条目式输出);other(其他)。
**要求全文输出等于强制大模型显式内省,从而防止偷懒与不过脑子,`系统默认提示词(full)`生成的改动要明显比`系统默认提示词(item)`多**。
而条目式输出,每个问题输出original(原文)、corrected(修改后)、explanation(解释)三项内容,其中只有original是必需的,输出后要用于定位和(如果有corrected)替换,可以节省输出token,适用于预期修改比较少的情形,形成进行专项审校。
other类型输出的后续处理暂时跟全文输出相同,可用于收集自定义的结构化数据。
前面所说的提示词例子的输出类型是full(全文输出)。下面是`系统默认提示词(item)`中对输出格式的指令,供参考:
```markdown
**输出格式**:
1. 从目标文本(target)中挑出需要修改的句子,加以修改,以 JSON 格式输出,且只输出该 JSON,不要其他说明。
2. JSON 格式为:{"items":[{"original":"需要修改的句子","corrected":"修改后的句子","explanation":"解释,绝大多数情形下可省略,仅在不解释难以理解时填写"}]}
3. 若无任何修改,输出:{"items":[]}
```
请注意,输出形式选item(条目式输出)时,JSON、items、original、corrected、explanation这些词语,对于大模型的理解和输出后的处理都有用,因此不要改变它们的形式。如果你对JSON格式了解不多,我建议直接在这个模版上改写。corrected和explanation两项可以省略。
#### 3.4.4 提示词重复功能
本扩展支持基于谷歌研究的提示词重复功能,以提高准确度。其原理是:重复用户输入(reference、context、target),让模型在真正处理时已经获得全局信息,从而获得更好的上下文理解。
**重复模式**:在设置中配置 `ai-proofread.proofread.promptRepetition` 选项:
- **不重复**(none,默认):不启用重复功能
- **仅重复目标文档**(target):只重复要修改的目标文档
- **重复完整对话流程**(all):重复参考文档、语境和目标文档,保持完整的对话流程,效果最好但成本最高
**注意事项**:
- 会增加输入token,重复部分翻倍,输出token不变。如果API支持缓存(如Deepseek),重复部分可能享受缓存命中的低价
- 重复发生在可并行化的prefill阶段,不增加延迟
- 建议先在少量文本上测试效果,再决定是否启用。经初步测试,对于较长的文本效果更好
### 3.5. 日志等过程文件
为了让用户能够核验、控制每一个步骤,扩展会以要校对的文档的文件名(以“测试.md”为例)为基础,生成一些中间文件,各自的作用如下:
1. 测试.md,要校对的文档
2. 测试.json,切分上述文档的结果,供检查后用于校对;可以进一步与别的切分结果进行合并,以便搭配target + context + reference一起提交处理
3. 测试.json.md,拼合上项JSON文件中的target的结果,用于查看或比较原始markdown文件,比JSON直观
4. 测试.log,切分日志,用来检查切分是否合理
5. 测试.proofread.json,校对上述JSON文件的直接结果,其中的`null`项表示还没有校对结果,重新校对时只处理`null`对应的条目,而不会重复处理已经完成的条目;校对前后的JSON长度不一致时(比如切分标准不一导致)会提示备份
6. 测试.proofread.json.md,拼合上项JSON文件中的结果,比较最初的markdown文件即可看出改动处;如果这个文件已经存在,则自动备份,并加时间戳
7. 测试.diff.html:通过jsdiff库比较校对前后markdown文件所得的结果,与Word近似的行内标记,可通过浏览器打印成PDF。需要联网调用jsdiff库,并等待运算完成
8. 测试.proofread.log,校对日志,**校对文本选段的结果也会存在这里**
9. 测试.alignment.html,逐句对齐勘误表(通过 diff 命令选择「对齐句子生成勘误表」或校对面板「生成勘误表」生成)
10. 测试.word-errors.csv,常用词语错误收集结果(生成勘误表时选择「同时收集」可得),CSV 格式(错误词语,正确词语,错误词语所在小句,错词长度,正词长度),便于筛选
**请特别注意:除自动累加的日志文件和提示备份的`测试.proofread.json`、自动备份的`测试.proofread.json.md`,其余中间文件,每次操作都将重新生成!如有需要,请自行备份。**
### 3.6. 其他功能与工具
已经作为辅助工具在前文提到的功能,这里也列入题目,以便速查。
1. **转换文档格式**:前面说到`convert docx to markdown`和`convert PDF to markdown`两个命令。还有`convert markdown to docx`,可转换Markdown为docx(Word、WPS的常用格式)。
2. **标记标题**:前面说到`mark titles from table of contents`命令可基于目录列表标记标题。如果文档标题以序号引导,还可以使用后面提到的`check numbering hierarchy`命令来标记。
3. **段落整理**:前面说到`format paragraphs`命令,可以在段末加空行,即整理成符合Markdown格式的段落;还可以删除符合Markdown格式但不符合一般习惯的段内分行。基于文档行长众数来计算,因而适合整体较长,并且以长段落为主的文档;短小、段落零碎时准确率会比较低。
4. **从md反查PDF**:从markdown文件选择文本,使用`Search Selection In PDF`命令,将调用PDF查看器SumatraPDF打开同名的PDF文件,并搜索选中文本。须先安装好[SumatraPDF](https://www.sumatrapdfreader.org/free-pdf-reader),在高级选项中设置`ReuseInstance = true`可以避免重复打开同一个文件。
5. **字词检查**:命令`check words`。分类两个分支:基于词典数据的检查;基于《通用规范汉字表》的检查;自定义替换表的提示与替换功能。第三支含预置了《通用规范汉字表》简繁异对照表、《第一批异形词整理表》的数据。用户还可以通过`manage custom tables`命令,加载自制的正则/字面替换表,可用于基于个人积累的专项检查,支持正则表达式,有较大潜力;其正则替换表与TextPro类似,计划逐步增强兼容能力。这是一个非常强大且灵活的功能,值得深入探索。
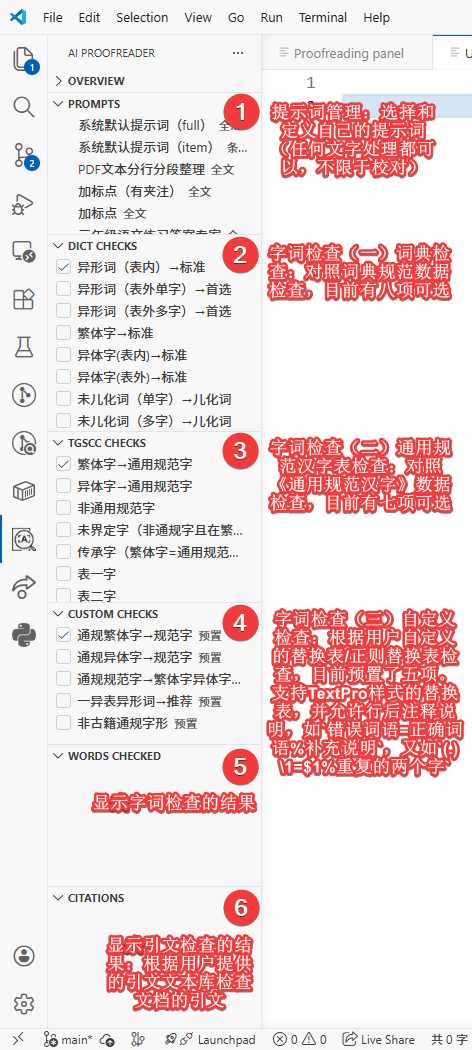
6. **标题树与段内序号检查**:命令`check numbering hierarchy`。检查标题序号和段内序号的层级与连续性;在侧栏「标题树」中可定位到文档、对标题序号执行同级别批量操作:标记为 Markdown 标题、升级、降级。
7. **引文核对**:指定本地文献库根目录(Markdown格式,可附带同名PDF以便反查),然后使用`build citation reference index`命令建立文献索引(每次更新须手动重建),然后就可以通过`verify selected citation`命令核对选中的引文,或通过`verify citations`批量核对全文中引文(标记是引号、`>`,以及这些句段后的上标、圈码、Markdown注码),结果列表可查看引文和文献的差异,并能在文献PDF中反查。有多种配置可选。
8. **转换半角引号为全角**:使用`convert quotes to Chinese`命令或菜单。也可在设置中设定为自动处理。某些LLM输出时一律使用英文引号,可以用这个命令来整理。
9. **分词、词频与字频统计**:使用`segment file`和`segment selection`命令,可选分词后替换原文、输出词频统计表(词语、词性、词频)或输出字频统计表(单字及频度)。分词模块使用的是[jieba-wasm](https://github.com/fengkx/jieba-wasm)。
10. **按句子切分**:使用`split into sentences`命令,可选分隔符号;默认使用两个分行符(即一个空行)分隔句子,适合用于编辑校对样例,与其保存时的默认分隔符一致。
11. **编辑校对样例**:使用`edit proofreading examples`命令,千文已经有介绍。
12. **vscode提供的文档比较(diff)功能**:通过文件浏览器右键菜单使用;本扩展在vscode中的比较即调用了本功能。vscode是这些年最流行的文本编辑器,[有许多便捷的文字编辑功能](https://blog.xiiigame.com/2022-01-10-给文字工作者的VSCode入门教程/#vscode_1),很适合编辑工用作主力编辑器。
### 3.7. 注意事项
1. 确保在使用前已正确配置必要的 API 密钥。**请妥善保存你的秘钥!**
2. **一般的语言文字校对依赖丰富的知识、语料,建议使用大规模、非推理模型。某些推理模型、混合模型可能因为运行时间过长而导致错误,而服务器端可能已经实际运行并计费!**
3. 长文本建议先切分后校对,文本长度过程会影响校对质量,并增加失败的几率
4. 注意所用模型 API 调用频率和并发数的限制,可通过配置调整
5. 启用提示词重复功能会增加输入token成本,请根据实际效果权衡使用
## 4. 配置
从VS Code界面左下角或扩展界面的⚙️,或从命令面板(Ctrl+Shift+P)查找命令Preferences: Open Settings (UI)都能进入扩展配置界面。
配置项的意义请参考本文档相关的部分,以及对应模型的文档。
参考:
* Deepseek[限速](https://api-docs.deepseek.com/zh-cn/quick_start/rate_limit):没有并发限制,但服务器在高流量时会延迟(需要注意观察)
* 阿里云百炼平台[限流规则](https://help.aliyun.com/zh/model-studio/rate-limit):qwen-max系列稳定版的rpm通常为600甚至更高,带日期的快照版通常为60,没有并发限制(建议为10)
* 谷歌[rate-limits](https://ai.google.dev/gemini-api/docs/rate-limits)
### 4.1. 大语言模型
目前支持这些大语言模型服务:
1. [Deepseek开放平台](https://platform.deepseek.com/)(默认)
1. [阿里云百炼](https://bailian.console.aliyun.com/),[模型列表](https://bailian.console.aliyun.com/?tab=model#/model-market)
1. [Google Gemini](https://aistudio.google.com/),[模型列表](https://ai.google.dev/gemini-api/docs/models)
1. [Ollama本地模型](https://ollama.ai/),对计算机性能、专业知识要求较高
### 4.2. 模型温度
每个模型用于校对的最佳温度需要耐心测试才能得到。
以往的经验是,温度为1时极少有错误和无效改动。
提高模型温度可以增加随机性,如此多次尝试有可能提高召回率,同时也增加不稳定和错误率。
以下是官方资料:
1. deepseek
`temperature` 参数默认为 1.0。
官方建议根据如下表格,按使用场景设置 `temperature`。
| 场景 | 温度 |
| ------------------- | ---- |
| 代码生成/数学解题 | 0.0 |
| 数据抽取/分析 | 1.0 |
| 通用对话 | 1.3 |
| 翻译 | 1.3 |
| 创意类写作/诗歌创作 | 1.5 |
2. 阿里云百炼平台
* deepseek v3/r1: temperature:0.7(取值范围是`[0:2)`)
* qwen系列: 取值范围是`[0:2)`
3. Google Gemini
默认为1
## 5. TODO
1. 生卒年检查
2. 校对样例文件改为JSON,配编辑、勾选应用界面(webview)
3. 在线引文核对
1. 读秀,
2. 中华经典古籍库,
3. 识典故古籍
5. 人看的相似度使用编辑距离:fastest-levenshtein,在对齐完成后,快速计算两个相似句子的“修改程度”百分比。它是 JS 环境下编辑距离运算的最快实现
6. 调研集成opencc-js,用于繁简转换和用词习惯检查
7. 勘误表改为JSON加web viewer
8. 预置更多提示词,包括常用的专项校对
1. 典型错误举例校对
1. 标点符号用法错误
2. 数字用法错误
3. 年代、时间错误
4. 语法错误
2. 少见、可疑字词句的正常化、优化
3. PDF/OCR纯文本整理
4. 练习题就地回答
5. 翻译
6. 按小学语文教材标准加拼音
9. 自主发现、提出、校对知识性问题
1. 检索、核对互联网资料
2. 检索、核对本地词典(以Python库mdict查询模块为基础)
10. 内部git版本管理
11. 推理模型无法使用的问题(可能单纯是因为运行时间过长)
12. 在按长度切分的基础上调用LLM辅助切分(似乎仅仅在没有空行分段文本上有必要)
## 6. 更新日志
### v1.8.3
- 特性:在activity bar上增加扩展图标,展示概览页,引导用户使用
- 优化:文档,速查手册
### v1.8.1
- 特性:词典检查中增加儿化词语检查;更新词典数据
### v1.8.0
- 特性:提示词增加输出类型标记:full(全文输出);item(条目式输出);other(其他,暂时按全文处理,可用于收集自定义的结构化数据)
- 特性:支持条目式输出(提示词输出类型item),即输出原文(original,必选)、修改后(corrected)、解释(explanation)三项内容,这样可以节省输出token,适用于预期修改比较少的情形,比如专项审校
- 特性:自定义替换表中预置《古籍印刷通用字規範字形表》
### v1.7.2
- bugfix:Cannot read properties of undefined (reading 'CrLf')
### v1.7.1
- 优化:文档和速查手册
### v1.7.0
- 特性:持续发现与监督校对流程(实验功能),即带样例校对,审改校对结果并收集样例,再次带样例校对,如此循环。是对现有几个功能的集成
- 特性:标题树与段内序号检查
- 特性:比较文件时自动收集错误词语与正确词语对,以便整理后用作自定义替换表
- 优化:扩展结果面板为校对面板,即全流程控制面板
- 特性:编辑校对样例;使用样例校对选中文本;合并JSON功能时可以合并一个Markdown文件,比如校对样例文件;切分为句子的命令。
- 特性:用户加载非正则自定义替换表时允许指定是否按词语边界匹配
- 优化:取消jieba调用失败时保持静默并使用备用方案的行为,改为报告并停止处理。
- bugfix:删除opencc-js
### v1.6.3
- 特性:集成jieba-wasm分词库,支持用户词典路径
- 分词后再进行词语检查,提高精确性;
- 在句子对齐和引文核查中,可选分词(默认search模式)后再进行相似度计算,更准确,但速度稍慢。
- 优化:字词检查
- 词典表外异形词划分为单字词和多字词两个选项,都在分词后检查
- 增加《第一批异形词整理表》数据,作为预置的自定义替换表
- 字词检查可选输出统计表
- 简化单字检查逻辑,大大提高速度
- 特性:对文件或选段进行分词,或生成词频词性统计表;生成字频统计表
- !!! caution 安装包体积由726KB增加到3.8MB
### v1.5.3
- 特性:根据词典检查字词,包括异体/繁体字、异形词等
- 特性:根据《通用规范汉字表》检查字词,包括异体/繁体字、异形词等
- 特性:自定义替换表检查,仿TextPro风格的给予批量自定义(正则)替换表的提示与替换
- 优化:提示词管理器改用treeview,与字词检查类型/表、结果一致
- 文档:在docs中增加了commands-cheatsheet.md,包含业务逻辑、命令的便览图标
- 优化:优化了分行符的处理方式,改动有点大,是否有负面影响需要观察
### v1.4.0
- 特性:增加基于本地文献库(Markdown格式,可附带同名PDF以便反查)的引文核对功能,选中引文核对,或全文自动收集引文后核对
### v1.3.1
- 特性:HTML审校记录/勘误表
- 增加备注列,可以填入文字(无法保存,可用表格先准备好,筛选时粘入,再保存为PDF或复制到Word中)
- 打印时可以选择是否分页时添加表头
### v1.3.0
- 特性:增加根据目录表(Markdown形式的标题列表)在文档中标记标题的功能`mark titles from table of contents`
### v1.2.2
- 优化:合并JSON功能,默认改为“拼接模式”;增加更新对应的Markdown文件的功能
### v1.2.0
- 特性:支持提示词重复功能(据谷歌相关研究)
- 特性:重新支持调试日志功能
- 优化:对提示词作了少量优化
- 优化:校对选中文本时可以通过Esc终止
- debug: 扩展前后段落为语境算法跳过本段其余文本、不能处理选中段后分行符问题;校对选中文本、校对JSON改用同一个函数
### v1.1.4
- 优化:优化勘误表相关的句子分切、对齐算法,并允许设定相似度
- 特性:勘误表增加多种筛选功能,如序号筛选,即可挑出要保留的条目
### v1.1.0
- 特性:`diff it with another file`命令增加功能,支持逐句对齐原始文档和校对后的文档,生成一个有筛选和比较功能的HTML文件,从而可用于制作勘误表
### v1.0.4
- 优化:支持直接从`*.proofread.json.md`反查`*.pdf`
- 优化:文档
### v1.0.3
- bug修复
- 优化:默认并发数改为10、rpm改为600、超时改为90秒
- 优化:外语校对提示
### v1.0.0
- !!! caution 设置中的毫秒改为秒
### v0.1.17
- 特性:段落整理:在原有段末添加空行基础上,增加了删除段内分行的功能
### v0.1.16
- 特性:在段末添加空行,适用于从PDF转出的断行、无空行文本
- 优化:“按长度切分,扩展前后段落为上下文”,修改为“按长度切分,以前后段落为上下文”,不再重复提交target自身
- 优化:合并JSON功能增加“拼接”模式
- 优化:只有当校对前后的JSON长度不一时才备份、删除,否则不备份;在参数确认后才开始备份;保持面板、菜单、命令各入口一致
- 优化:文档
### v0.1.15
- 修复:并发失效问题
- 修复:内容为空字符串问题(直接返回原内容)
- 优化:文件转换工具兼容多平台和常用终端
- 优化:统一文件备份逻辑为备份旧文件为bak
### v0.1.14
- 优化:支持 pdftotext 常用参数,模式、切边、页码等
### v0.1.13
- 优化:删除所有文件转换后的打开文件的功能
- 优化:处理面板中增加校对耗时信息;删除重复的校对结果统计信息
- 优化:取消用户设置提示词的数量限制
- 优化:删除调试日志功能
### v0.1.12
- bug修复:测试pdftotext是否存在改为更通用的方法
- 优化:使用前测试pandoc是否存在
### v0.1.11
- 增加使用pdftotext工具把PDF文件转换为Markdown文件(实际是纯文本)的功能
### v0.1.10
- result panel 优化:紧凑设计,减少冗余信息,尽量一屏展示;色调更淡雅
### v0.1.9
- 修复了转换子目录中的文档时不能正确处理图片的问题
- 更新了文档
### v0.1.8
- 新增功能:JSON批量提交LLM前展示所有参数,请用户确认或取消
- 显示文件路径、总段落数、处理参数(平台、模型、温度、并发数、请求频率、提示词)
- 用户可以选择确认开始或取消操作
- 支持所有触发方式:右键菜单、命令面板、webview面板按钮等
- 改进webwiew panel
- 增加进度条
- 呈现切分摘要信息,如段落数、超长段落等
- 查看日志文件时自动滚动到底部
- debug:重用webwiew报错
### v0.1.7
- 取消校对时生成jsdiff html,改成提示用户生成
### v0.1.6
- 切分和校对结果改成Webview Panel呈现,在一个切分、校对流程中可以重新打开
- 切分结果菜单增加一个“校对JSON结果”按钮
### v0.1.5
- 禁用Gemini模型思考功能
- 添加重试机制
### v0.1.4
- 新增功能:支持Ollama本地模型,无需网络连接即可使用本地大语言模型进行校对(适合专家用户)
- 优化:为本地模型增加了更长的超时时间,适应本地计算的特点
- 优化:完善校对过程中给用户的配置信息、日志文件中输出的配置信息
### v0.1.3
- 新增功能:markdown切分/选段校对时,可以加入前后段落作为context
- 优化:转换半角引号为全角的算法,避免跨行引号转换错误
### v0.1.2
- 扩展了jsdiff比较并生成html的功能,支持JSON文件,并允许用户指定每次比较的片段数量,避免过长文本无法渲染的问题
### v0.1.1
- 优化了文件切分功能,新增统一的切分入口
- 改进了校对进度显示和取消操作
- 增强了自动备份功能
- 优化了临时文件管理
- 修复了并发请求数的默认值问题
- 完善了错误处理和用户提示
## 7. 开发命令
```bash
# 安装依赖
npm install
# 首次开发需先执行一次打包,确保 sql.js 和 jieba-wasm 已复制到 dist
npm run package
# 开发时实时编译
npm run watch
# 打包
npm run package
# 构建 vsix 扩展安装文件用
npm run package-vsix
# 发布
npm run publish
```