https://github.com/geekquad/random-forest-from-scratch
A basic implementation of the Random Forest Classifier from Scratch and using Seaborn to find important features.
https://github.com/geekquad/random-forest-from-scratch
iris-dataset random-forest random-forest-classifier seaborn sklearn
Last synced: about 1 month ago
JSON representation
A basic implementation of the Random Forest Classifier from Scratch and using Seaborn to find important features.
- Host: GitHub
- URL: https://github.com/geekquad/random-forest-from-scratch
- Owner: geekquad
- Created: 2020-06-27T18:51:02.000Z (about 6 years ago)
- Default Branch: master
- Last Pushed: 2020-06-28T20:39:50.000Z (almost 6 years ago)
- Last Synced: 2025-01-07T05:16:29.349Z (over 1 year ago)
- Topics: iris-dataset, random-forest, random-forest-classifier, seaborn, sklearn
- Language: Jupyter Notebook
- Homepage:
- Size: 49.8 KB
- Stars: 1
- Watchers: 2
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# Random-Forest-from-Scratch
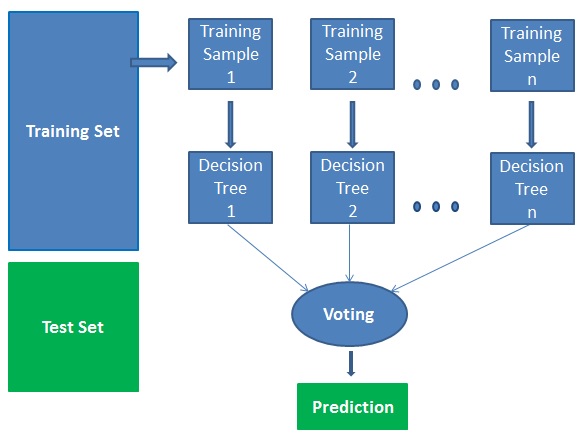
Random forests is a supervised learning algorithm. It can be used both for classification and regression. It is also the most flexible and easy to use algorithm. A forest is comprised of trees. It is said that the more trees it has, the more robust a forest is. Random forests creates decision trees on randomly selected data samples, gets prediction from each tree and selects the best solution by means of voting. It also provides a pretty good indicator of the feature importance.
## Working of the Algorithm
It works in four steps:
- Select random samples from a given dataset.
- Construct a decision tree for each sample and get a prediction result from each decision tree.
- Perform a vote for each predicted result.
- Select the prediction result with the most votes as the final prediction.
## Documentation of Random Forest:
https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html
## Parameters of the Algorithm:
- min_samples_split (default value = 2)
- criterion : optional (default=”gini”)
- n_estimators(default value = 100
nodes cannot be further seperated below this value.
It controls how a Decision Tree decides where to split the data.
It is the measure of impurity in a bunch of examples.
This parameter allows us to use the different-different attribute selection measure. Supported criteria are “gini” for the Gini index and “entropy” for the information gain.
This parameter tells is the number of trees in the forest.
## Evaluation of the Algorithm:
### a) Without Parameter Tuning:
precision recall f1-score support
0 1.00 1.00 1.00 14
1 0.94 0.94 0.94 17
2 0.93 0.93 0.93 14
avg / total 0.96 0.96 0.96 45
#### Accuracy: 0.9555555555555556
### b) After Parameter Tuning:
precision recall f1-score support
0 1.00 1.00 1.00 14
1 1.00 0.94 0.97 17
2 0.93 1.00 0.97 14
avg / total 0.98 0.98 0.98 45
#### Accuracy: 0.9777777777777777
## Finding Imoprtant Features using Seaborn Library:
Finding important features or selecting features in the IRIS dataset.
