https://github.com/goatcheesesaladwithpeanutoildressing/beam-amazon-batch-example
A practical example of batch processing on Google Cloud Dataflow using the Go SDK for Apache Beam :fire:
https://github.com/goatcheesesaladwithpeanutoildressing/beam-amazon-batch-example
amazon apache-beam batch-processing big-data golang google-cloud-dataflow
Last synced: over 1 year ago
JSON representation
A practical example of batch processing on Google Cloud Dataflow using the Go SDK for Apache Beam :fire:
- Host: GitHub
- URL: https://github.com/goatcheesesaladwithpeanutoildressing/beam-amazon-batch-example
- Owner: goatcheesesaladwithpeanutoildressing
- Created: 2019-09-07T21:11:21.000Z (almost 7 years ago)
- Default Branch: master
- Last Pushed: 2019-09-26T15:54:09.000Z (over 6 years ago)
- Last Synced: 2025-02-23T23:34:06.416Z (over 1 year ago)
- Topics: amazon, apache-beam, batch-processing, big-data, golang, google-cloud-dataflow
- Language: Go
- Homepage:
- Size: 455 KB
- Stars: 3
- Watchers: 2
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# :eyes: gobeam-amazon-reviews :eyes:
A practical example of batch processing 50 * 100 Amazon reviews .csv chunks using the Go SDK for Apache Beam. :fire:
> Be aware that the Go SDK is still in the experimental phase and may not be fully safe for production.
#### Dataset
The data sample was retrieved from [Kaggle](https://www.kaggle.com/datafiniti/consumer-reviews-of-amazon-products/version/5#) and chunked into several .csv files.
#### Output
The pipeline applies a set of transformation steps over 5000 amazon's reviews and builds and extract useful stats such as the top most helpful reviews, an overview of the rating, the recommendation ratio etc.
### Get started
1/ Make sure you have properly installed Go and have added it to your $PATH.
```sh
go version
```
2/ Install the project dependencies
```sh
go get -u -v
```
3/ Run the pipeline locally (use the Direct Runner, reserved for testing/debugging)
```sh
go run main.go
```
4/ (Optional) Deploy to Google Cloud Dataflow runner (requires a worker harness container image)
> Open `deploy_job_to_dataflow.sh` file and replace placeholders by your GCP project ID, your Cloud Storage bucket name and your worker harness container image (if you don't have one: see below).
```sh
chmod -X ./deploy_job_to_dataflow.sh
./deploy_job_to_dataflow.sh
```
4 bis/ (Optional) Run the pipeline on a local Spark cluster
```sh
# cd to the beam source folder
cd ~//github.com/apache/beam/
# build a docker image for the Go SDK
./gradlew :sdks:go:container:docker
# Run the spark job-server
./gradlew :runners:spark:job-server:runShadow
# When the server is running, execute the pipeline :
./run_with_apache_spark.sh
```
You can monitor the running job via the Web Interface : `http://[driverHostname]:4040`.
### How to build and push a worker harness container image
> This is the Docker image that Dataflow will use to host the binary that was uploaded to the staging location on GCS.
1/ Go to the apache-beam source folder
```sh
cd go/src/github.com/apache/beam
```
2/ Run Gradle with the Docker target for Go
```sh
./gradlew -p sdks/go/container docker
```
3/ Tag your image and push it to the repository
**Bintray**
```sh
docker tag .bintray.io/beam/go:latest
docker push .bintray.io/beam/go:latest
```
**Cloud Registry**
```sh
docker tag gcr.io//beam/go:latest
docker push gcr.io//beam/go:latest
```
4/ Update the `./deploy_job_to_dataflow.sh` file with the new Docker image and run it
```
./deploy_job_to_dataflow.sh
```
[Click here](https://github.com/apache/beam/blob/master/sdks/CONTAINERS.md) to view a detailed guide.
## Understand Beam basics in a minute
Beam is a **unified programming model** that allow you to write data processing pipelines that can be run in a batch or a streaming mode on **different runners** such as Cloud Dataflow, Apache Spark, Apache Flink, Storm, Samza etc.
This is a great alternative to the **Lambda Architecture** as you have to write and maintain one single code (may slightly differ) to work with bounded or unbounded dataset.
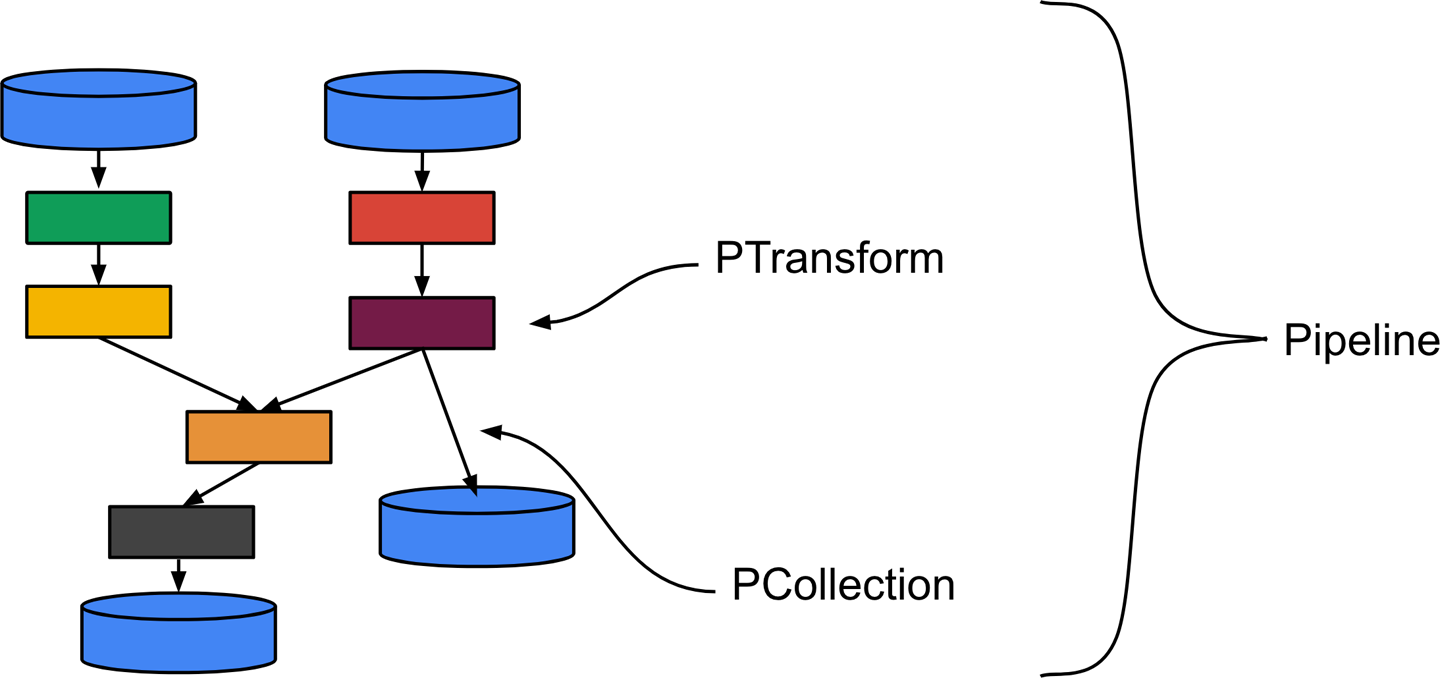
You have to define a **Pipeline** which is a function that contains several transformation steps. Each step is called a **PTransform**. A PTransform is a function that takes a **PCollection** as a main input (and eventually side input PCollections), then compute data and outputs 0, 1 or multiple PCollections.
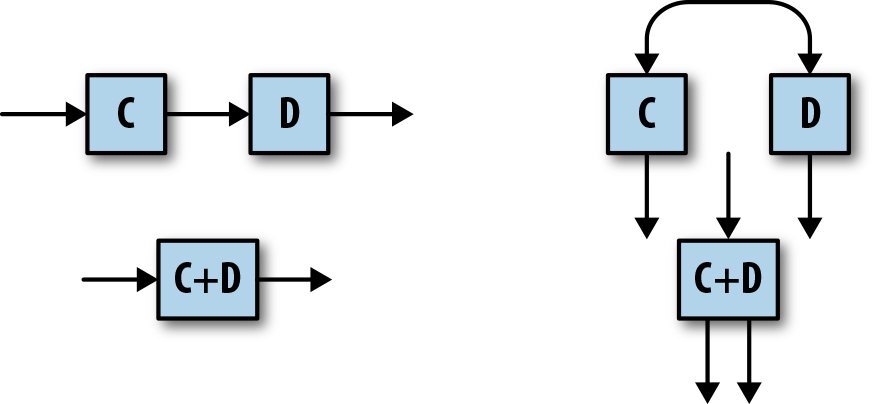
A PTransform can also be a **composite transform** which is a combination of multiple transformation steps. That's useful to write high level transformation steps and to structure your code to improve resuability and readability.
The SDK provides built-in element-wise/count/aggregate primitive transformations such as **ParDo**, **Combine**, **Count**, **GroupByKey** which can be composite transforms under the hood. Beam hides that to make it easier for developers.
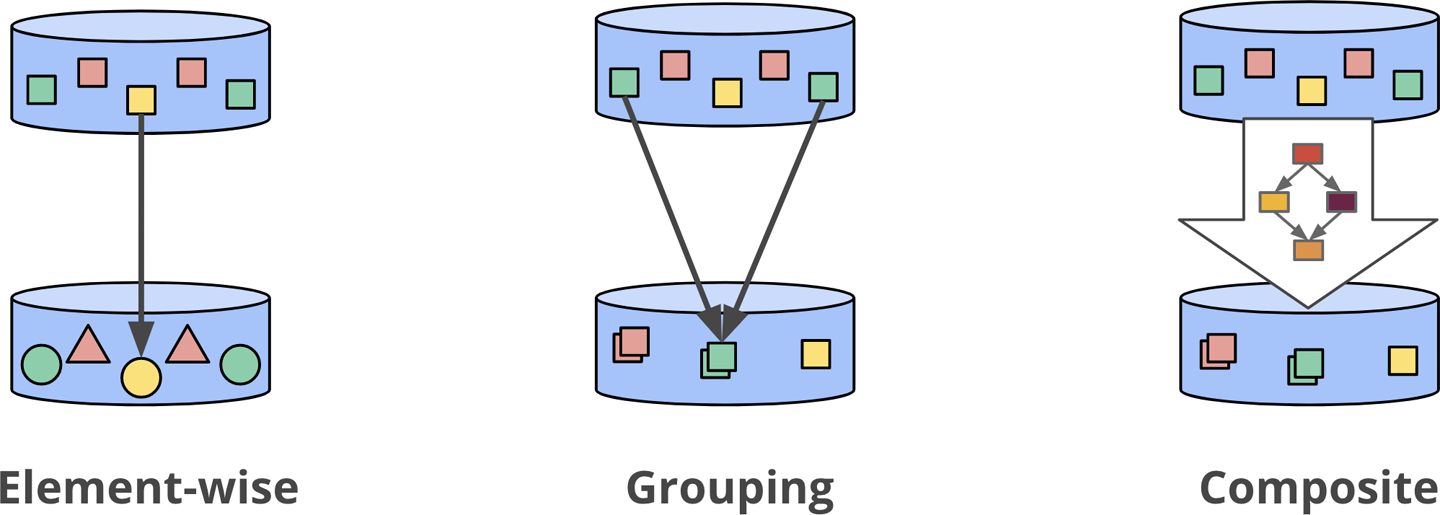
A PCollection is like a box that will contain all the data that will pass through your pipeline. It's immutable (cannot be modified) and can be big, massive or unbounded. The nature of a PCollection depends on which **source** has created it. Most of the time, a fixed size PCollection is created by a text file or a database table and an infinite size PCollection is created by a streaming source such as **Cloud Pub/Sub** or **Apache Kafka**.
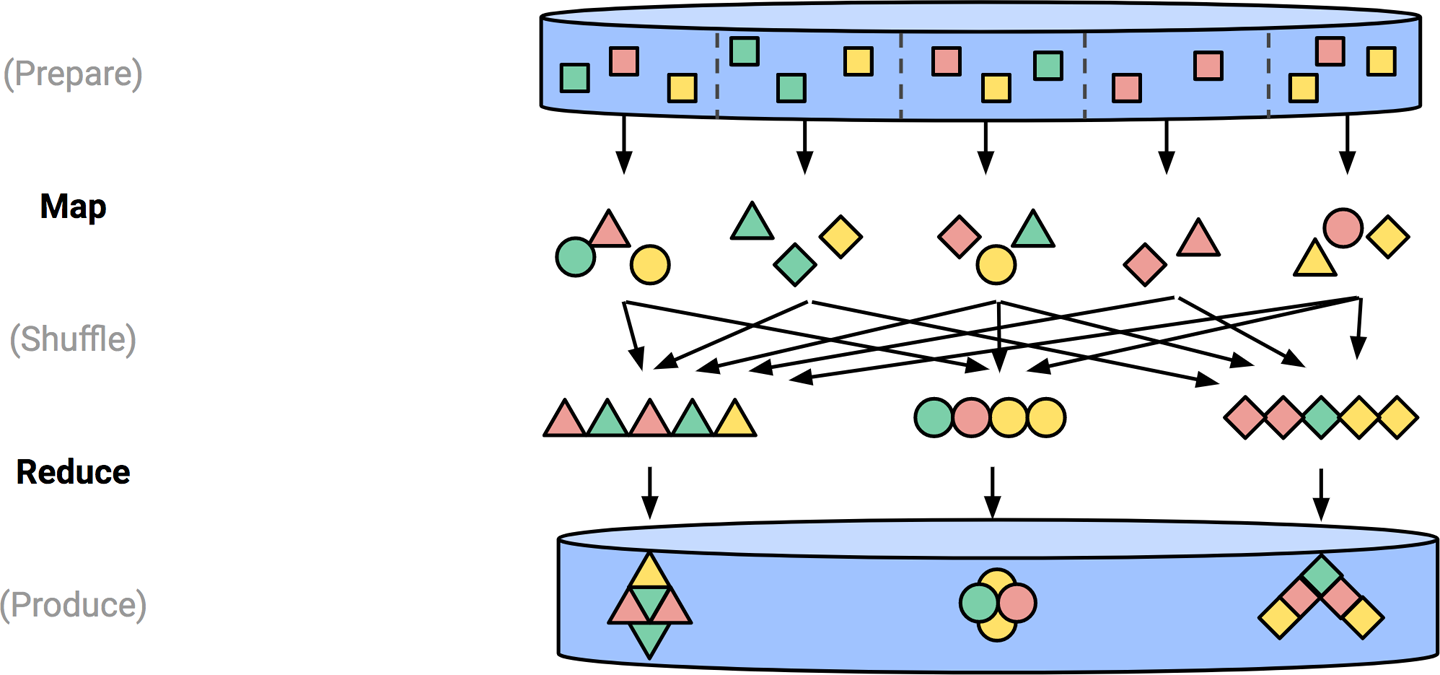
When you deploy the pipeline to a runner, it will generate an optimised Directed Acyclic Graph (or DAG) which is basically a combination of nodes and edges (nodes are going to be PCollections, edges gonna be PTransforms).
The targeted runner will next set up a cluster of workers and execute some of the transformation steps in parallel in a Map-Shuffle-Reduce style's algorithm.
Learn more about Apache Beam [here](https://beam.apache.org/documentation/programming-guide/).
The Go SDK is still **experimental** and doesnt provides features that makes streaming mode possible, such as advanced windowing strategies, watermarks, triggers and all of the tools to handle late data.
> Images credits: [Streaming Systems](http://streamingsystems.net/)
## Learn more about Apache-Beam
* [The GoDoc for the Beam Go SDK](https://godoc.org/github.com/apache/beam/sdks/go/pkg/beam)
* [The official Apache Beam programming guide](https://beam.apache.org/documentation/programming-guide/)
* [Andrew Brampton's article](https://blog.bramp.net/post/2019/01/05/apache-beam-and-google-dataflow-in-go/)
* [Beam execution model](https://beam.apache.org/documentation/execution-model/)
* [Dataflow whitepaper](https://storage.googleapis.com/pub-tools-public-publication-data/pdf/43864.pdf)
* [RFC: Beam Go SDK](https://docs.google.com/document/d/1yjhttps://github.com/angulartist/gobeam-amazon-reviews/edit/master/README.md0_hxq2J1iestjFUUrm_BVQLsFxQiiqtcFhgodzIgM)
* [Streaming systems](http://streamingsystems.net/)
* [Martin Gorner - Dataflow Explained](https://www.youtube.com/watch?v=AZht1rkHIxk)
* [Google MapReduce paper](https://static.googleusercontent.com/media/research.google.com/en//archive/mapreduce-osdi04.pdf)
* [FlumeJava paper](https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/35650.pdf)
* [Computerphile - MapReduce](https://www.youtube.com/watch?v=cvhKoniK5Uo)
* [GCP Podcasts](https://www.gcppodcast.com/search/?s=beam)