https://github.com/godalida/koala-diff
Blazingly fast data comparison tool for Python, powered by Rust. Compare massive CSV/Parquet datasets instantly.
https://github.com/godalida/koala-diff
csv data-engineering data-quality diff high-performance parquet polars python rust simd
Last synced: 5 months ago
JSON representation
Blazingly fast data comparison tool for Python, powered by Rust. Compare massive CSV/Parquet datasets instantly.
- Host: GitHub
- URL: https://github.com/godalida/koala-diff
- Owner: godalida
- License: mit
- Created: 2026-02-13T15:13:49.000Z (5 months ago)
- Default Branch: main
- Last Pushed: 2026-02-16T14:23:20.000Z (5 months ago)
- Last Synced: 2026-02-20T04:54:37.101Z (5 months ago)
- Topics: csv, data-engineering, data-quality, diff, high-performance, parquet, polars, python, rust, simd
- Language: Python
- Homepage:
- Size: 1.96 MB
- Stars: 4
- Watchers: 0
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
- awesome-data-engineering - koala-diff - A high-performance Python library for comparing large datasets (CSV, Parquet) locally using Rust and Polars. It features zero-copy streaming to prevent OOM errors and generates interactive HTML data quality reports. (Data Comparison)
README

Koala Diff
Blazingly Fast Data Comparison for the Modern Stack.






🚀 Quickstart |
🚩 Issues |
📊 Benchmarks
---
**Koala Diff** is the "git diff" for your data lake. It compares massive datasets (CSV, Parquet, JSON) instantly to find added, removed, and modified rows.
Built in **Rust** 🦀 for speed, wrapped in **Python** 🐍 for ease-of-use. It streams data to compare datasets larger than RAM and generates beautiful HTML reports.
### 🚀 Why Koala Diff?
* **Zero-Copy Streaming:** Compare 100GB files on a laptop without crashing RAM.
* **Rust-Powered Analytics:** Go beyond row counts. Track **Value Variance**, **Null Drift**, and **Match Integrity** per column.
* **Professional Dashboards:** Auto-generates premium, stakeholder-ready HTML reports with status badges and join attribution.
* **Deep-Dive API:** Extract mismatched records as Polars DataFrames for instant remediation.
---
## 📈 The "Magic" Benchmark
> **"Process 100M rows on a laptop in seconds, not minutes."**
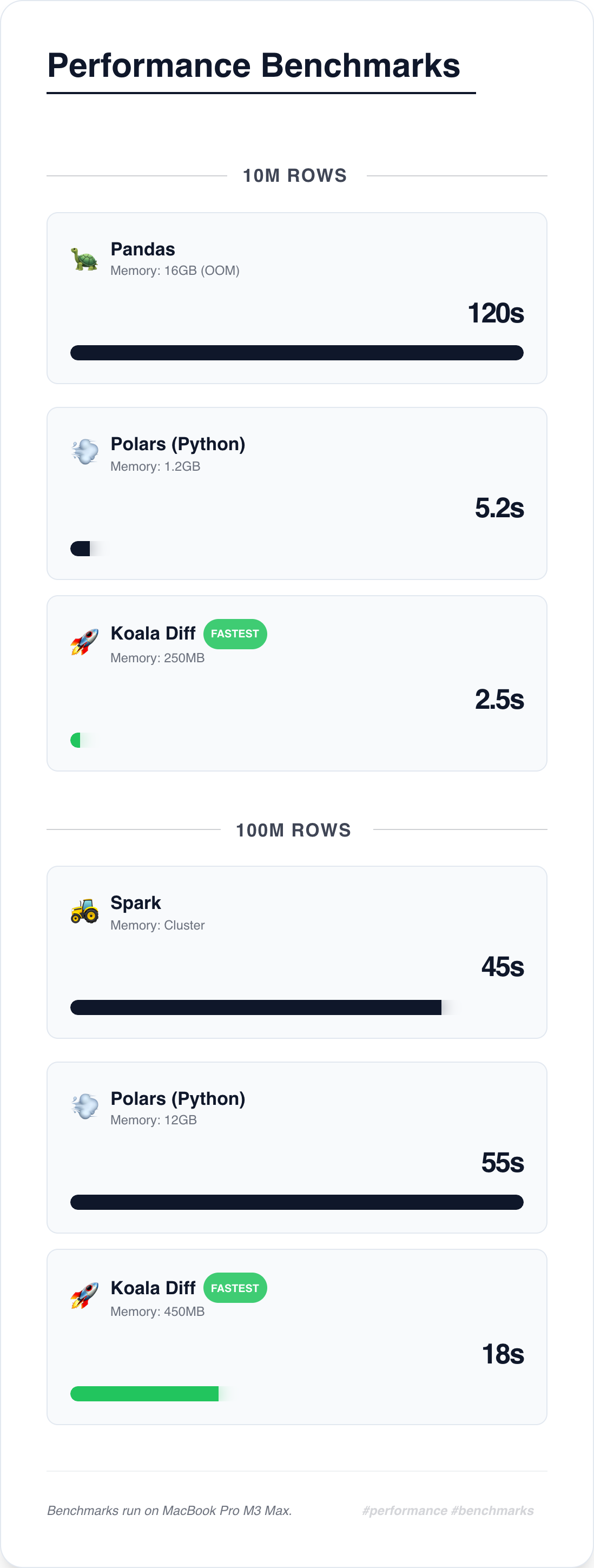
### ⚡ Performance at a Glance
* **Time:** 🟦🟦 **1x** (Koala) vs 🟦🟦🟦🟦🟦 **3x** (Polars) vs 🟦🟦...🟦 **30x+** (Pandas)
* **RAM:** 🟩 **0.4GB** (Koala Diff) vs 🟩🟩🟩🟩🟩🟩🟩🟩 **12GB+** (Polars)
* **Edge:** Native Rust `XXHash64` handles massive joins locally without cluster overhead.
---
### 🧐 Why not just use Polars/Spark?
While Polars and Spark are incredible for general data processing, **Koala Diff** is a specialized tool for **Data Quality & Regression**:
| Feature | Polars / Spark | 🚀 Koala Diff |
| :--- | :--- | :--- |
| **Specialization** | General Purpose ETL | **Data Quality & Diffing** |
| **Memory** | High (Join-heavy) | **Ultra-Low (Streaming)** |
| **Output** | Raw DataFrames | **Pro Dashboards + Metrics** |
| **Logic** | Manual Join/Filter code | **Out-of-the-box Analytics** |
| **Stakeholders** | Engineer-facing | **Business-Ready Reports** |
*Koala Diff doesn't replace your processing engine; it verifies that its output is correct.*
---
---
*> Benchmarks run on MacBook Pro M3 Max.*
---
## 🎯 Common Use Cases
* **ETL Regression Testing:** Automatically verify that your daily pipeline didn't accidentally mutate 1 million rows after a code change.
* **Data Migration Validation:** Ensure 100% parity when moving data between systems (e.g., Hive to Snowflake or S3 to BigQuery).
* **Environment Drift Detection:** Compare **Production** vs. **Staging** datasets to find out why your model is behaving differently.
* **Compliance Auditing:** Generate unalterable HTML snapshots of data changes for regulatory or financial reviews.
* **CI/CD for Data:** Run `koala-diff` in your CI pipeline to block PRs that introduce unexpected data quality regressions.
---
## 📦 Installation
```bash
pip install koala-diff
```
## ⚡ Quick Start
### 1. Generate a "Pro" Report
```python
from koala_diff import DataDiff, HtmlReporter
# Initialize with primary keys
differ = DataDiff(key_columns=["user_id"])
# Run comparison
result = differ.compare("source.parquet", "target.parquet")
# Generate a professional dashboard
reporter = HtmlReporter("data_quality_report.html")
reporter.generate(result)
```
### 2. Mismatch Deep-Dive
Need to fix the data? Pull the exact differences directly into Python:
```python
# Get a Polars DataFrame of ONLY mismatched rows
mismatch_df = differ.get_mismatch_df()
# Analyze variance or push to a remediation pipeline
print(mismatch_df.head())
```
### 2. CLI Usage (Coming Soon)
```bash
koala-diff production.csv staging.csv --key user_id --output report.html
```
## 🏗 Architecture
Koala Diff uses a streaming hash-join algorithm implemented in Rust:
1. **Reader:** Lazy Polars scan of both datasets.
2. **Hasher:** XXHash64 computation of row values (SIMD optimized).
3. **Differ:** fast set operations to classify rows as `Added`, `Removed`, or `Modified`.
4. **Reporter:** Jinja2 rendering of results.
## 🤝 Contributing
We welcome contributions! Whether it's a new file format reader, a performance optimization, or a documentation fix.
1. Check the [Issues](https://github.com/godalida/koala-diff/issues).
2. Read our [Contribution Guide](CONTRIBUTING.md).
## 📄 License
MIT © 2026 [godalida](https://github.com/godalida) - [KoalaDataLab](https://koaladatalab.com)