https://github.com/gokumohandas/testing-ml
Learn how to create reliable ML systems by testing code, data and models.
https://github.com/gokumohandas/testing-ml
great-expectations machine-learning mlops pytest testing
Last synced: about 1 year ago
JSON representation
Learn how to create reliable ML systems by testing code, data and models.
- Host: GitHub
- URL: https://github.com/gokumohandas/testing-ml
- Owner: GokuMohandas
- Created: 2022-08-01T22:41:32.000Z (almost 4 years ago)
- Default Branch: main
- Last Pushed: 2022-09-12T11:58:43.000Z (almost 4 years ago)
- Last Synced: 2025-04-30T07:36:10.724Z (about 1 year ago)
- Topics: great-expectations, machine-learning, mlops, pytest, testing
- Language: Jupyter Notebook
- Homepage:
- Size: 28.3 KB
- Stars: 86
- Watchers: 2
- Forks: 13
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# Testing ML
Learn how to create reliable ML systems by testing code, data and models.




👉 This repository contains the [interactive notebook](https://colab.research.google.com/github/GokuMohandas/testing-ml/blob/main/testing.ipynb) that complements the [testing lesson](https://madewithml.com/courses/mlops/testing/), which is a part of the [MLOps course](https://github.com/GokuMohandas/mlops-course). If you haven't already, be sure to check out the [lesson](https://madewithml.com/courses/mlops/testing/) because all the concepts are covered extensively and tied to software engineering best practices for building ML systems.



- [Data](#data)
- [Expectations](#expectations)
- [Production](#production)
- [Models](#models)
- [Training](#training)
- [Behavioral](#behavioral)
- [Adversarial](#adversarial)
- [Inference](#inference)
## Data
Tools such as [pytest](https://madewithml.com/courses/mlops/testing/#pytest) allow us to test the functions that interact with our data but not the validity of the data itself. We're going to use the [great expectations](https://github.com/great-expectations/great_expectations) library to create expectations as to what our data should look like in a standardized way.
```bash
!pip install great-expectations==0.15.15 -q
```
```python
import great_expectations as ge
import json
import pandas as pd
from urllib.request import urlopen
```
```python
# Load labeled projects
projects = pd.read_csv("https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/projects.csv")
tags = pd.read_csv("https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/tags.csv")
df = ge.dataset.PandasDataset(pd.merge(projects, tags, on="id"))
print (f"{len(df)} projects")
df.head(5)
```
### Expectations
When it comes to creating expectations as to what our data should look like, we want to think about our entire dataset and all the features (columns) within it.
```python
# Presence of specific features
df.expect_table_columns_to_match_ordered_list(
column_list=["id", "created_on", "title", "description", "tag"]
)
```
```python
# Unique combinations of features (detect data leaks!)
df.expect_compound_columns_to_be_unique(column_list=["title", "description"])
```
```python
# Missing values
df.expect_column_values_to_not_be_null(column="tag")
```
```python
# Unique values
df.expect_column_values_to_be_unique(column="id")
```
```python
# Type adherence
df.expect_column_values_to_be_of_type(column="title", type_="str")
```
```python
# List (categorical) / range (continuous) of allowed values
tags = ["computer-vision", "graph-learning", "reinforcement-learning",
"natural-language-processing", "mlops", "time-series"]
df.expect_column_values_to_be_in_set(column="tag", value_set=tags)
```
There are just a few of the different expectations that we can create. Be sure to explore all the [expectations](https://greatexpectations.io/expectations/), including [custom expectations](https://docs.greatexpectations.io/docs/guides/expectations/creating_custom_expectations/overview/). Here are some other popular expectations that don't pertain to our specific dataset but are widely applicable:
- feature value relationships with other feature values → `expect_column_pair_values_a_to_be_greater_than_b`
- row count (exact or range) of samples → `expect_table_row_count_to_be_between`
- value statistics (mean, std, median, max, min, sum, etc.) → `expect_column_mean_to_be_between`
### Production
The advantage of using a library such as great expectations, as opposed to isolated assert statements is that we can:
- reduce redundant efforts for creating tests across data modalities
- automatically create testing [checkpoints](https://madewithml.com/courses/mlops/testing#checkpoints) to execute as our dataset grows
- automatically generate [documentation](https://madewithml.com/courses/mlops/testing#documentation) on expectations and report on runs
- easily connect with backend data sources such as local file systems, S3, databases, etc.
```python
# Run all tests on our DataFrame at once
expectation_suite = df.get_expectation_suite(discard_failed_expectations=False)
df.validate(expectation_suite=expectation_suite, only_return_failures=True)
```
```json
"success": true,
"evaluation_parameters": {},
"results": [],
"statistics": {
"evaluated_expectations": 6,
"successful_expectations": 6,
"unsuccessful_expectations": 0,
"success_percent": 100.0
}
```
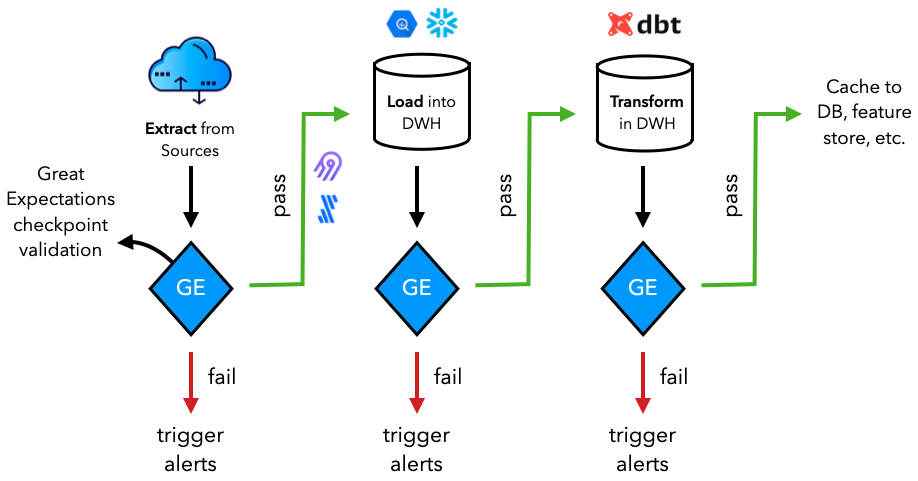
Many of these expectations will be executed when the data is extracted, loaded and transformed during our [DataOps workflows](https://madewithml.com/courses/mlops/orchestration#dataops). Typically, the data will be extracted from a source ([database](https://madewithml.com/courses/mlops/data-stack#database), [API](https://madewithml.com/courses/mlops/api), etc.) and loaded into a data system (ex. [data warehouse](https://madewithml.com/courses/mlops/data-stack#data-warehouse)) before being transformed there (ex. using [dbt](https://www.getdbt.com/)) for downstream applications. Throughout these tasks, Great Expectations checkpoint validations can be run to ensure the validity of the data and the changes applied to it.
## Models
Once we've tested our data, we can use it for downstream applications such as training machine learning models. It's important that we also test these model artifacts to ensure reliable behavior in our application.
### Training
Unlike traditional software, ML models can run to completion without throwing any exceptions / errors but can produce incorrect systems. We want to catch errors quickly to save on time and compute.
- Check shapes and values of model output
```python
assert model(inputs).shape == torch.Size([len(inputs), num_classes])
```
- Check for decreasing loss after one batch of training
```python
assert epoch_loss < prev_epoch_loss
```
- Overfit on a batch
```python
accuracy = train(model, inputs=batches[0])
assert accuracy == pytest.approx(0.95, abs=0.05) # 0.95 ± 0.05
```
- Train to completion (tests early stopping, saving, etc.)
```python
train(model)
assert learning_rate >= min_learning_rate
assert artifacts
```
- On different devices
```python
assert train(model, device=torch.device("cpu"))
assert train(model, device=torch.device("cuda"))
```
### Behavioral
Behavioral testing is the process of testing input data and expected outputs while treating the model as a black box (model agnostic evaluation). A landmark paper on this topic is [Beyond Accuracy: Behavioral Testing of NLP Models with CheckList](https://arxiv.org/abs/2005.04118) which breaks down behavioral testing into three types of tests:
- `invariance`: Changes should not affect outputs.
```python
# INVariance via verb injection (changes should not affect outputs)
tokens = ["revolutionized", "disrupted"]
texts = [f"Transformers applied to NLP have {token} the ML field." for token in tokens]
predict.predict(texts=texts, artifacts=artifacts)
```
['natural-language-processing', 'natural-language-processing']
- `directional`: Change should affect outputs.
```python
# DIRectional expectations (changes with known outputs)
tokens = ["text classification", "image classification"]
texts = [f"ML applied to {token}." for token in tokens]
predict.predict(texts=texts, artifacts=artifacts)
```
['natural-language-processing', 'computer-vision']
- `minimum functionality`: Simple combination of inputs and expected outputs.
```python
# Minimum Functionality Tests (simple input/output pairs)
tokens = ["natural language processing", "mlops"]
texts = [f"{token} is the next big wave in machine learning." for token in tokens]
predict.predict(texts=texts, artifacts=artifacts)
```
['natural-language-processing', 'mlops']
### Adversarial
Behavioral testing can be extended to adversarial testing where we test to see how the model would perform under edge cases, bias, noise, etc.
```python
texts = [
"CNNs for text classification.", # CNNs are typically seen in computer-vision projects
"This should not produce any relevant topics." # should predict `other` label
]
predict.predict(texts=texts, artifacts=artifacts)
```
['natural-language-processing', 'other']
### Inference
When our model is deployed, most users will be using it for inference (directly / indirectly), so it's very important that we test all aspects of it.
#### Loading artifacts
This is the first time we're not loading our components from in-memory so we want to ensure that the required artifacts (model weights, encoders, config, etc.) are all able to be loaded.
```python
artifacts = main.load_artifacts(run_id=run_id)
assert isinstance(artifacts["label_encoder"], data.LabelEncoder)
...
```
#### Prediction
Once we have our artifacts loaded, we're readying to test our prediction pipelines. We should test samples with just one input, as well as a batch of inputs (ex. padding can have unintended consequences sometimes).
```python
# test our API call directly
data = {
"texts": [
{"text": "Transfer learning with transformers for text classification."},
{"text": "Generative adversarial networks in both PyTorch and TensorFlow."},
]
}
response = client.post("/predict", json=data)
assert response.status_code == HTTPStatus.OK
assert response.request.method == "POST"
assert len(response.json()["data"]["predictions"]) == len(data["texts"])
...
```
## Learn more
While these are the foundational concepts for testing ML systems, there are a lot of software best practices for testing that we cannot show in an isolated repository. Learn a lot more about comprehensively testing code, data and models for ML systems in our [testing lesson](https://madewithml.com/courses/mlops/testing/).