https://github.com/googtech/crawler-learning
🕷 一个基于 HttpClient,Jsoup,WebMagic 的迷你版 JD 商城图书爬虫 ~
https://github.com/googtech/crawler-learning
httpclient jsoup mybatis mysql springboot
Last synced: over 1 year ago
JSON representation
🕷 一个基于 HttpClient,Jsoup,WebMagic 的迷你版 JD 商城图书爬虫 ~
- Host: GitHub
- URL: https://github.com/googtech/crawler-learning
- Owner: GoogTech
- License: mit
- Created: 2019-07-08T14:43:02.000Z (about 7 years ago)
- Default Branch: master
- Last Pushed: 2022-11-08T07:32:12.000Z (over 3 years ago)
- Last Synced: 2025-02-28T07:55:01.655Z (over 1 year ago)
- Topics: httpclient, jsoup, mybatis, mysql, springboot
- Language: Java
- Homepage:
- Size: 684 KB
- Stars: 8
- Watchers: 0
- Forks: 4
- Open Issues: 8
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
## 🕷 JD商城图书爬虫
### 版本介绍
#### JDBookCrawler 1.0
*涉及技术 : `HttpClient`,`Jsoup`,`MySQL`,详细介绍及使用指南见 : [`博客文章`](https://yubuntu0109.github.io/2019/07/14/%E5%B0%8F%E7%88%AC%E8%99%AB-JDBookCrawler-V1-0/)*
#### JDBookCrawler 2.0
*涉及技术 : `WebMagic`,`MyBatis`,`MySQL`,详细介绍及使用指南见 : [`博客文章`](https://yubuntu0109.github.io/2019/07/15/%E5%B0%8F%E7%88%AC%E8%99%AB-JDBookCrawler-V2-0/)*
#### JDBookCrawler 3.0
*涉及技术 : `Spring Boot`,`WebMagic`,`MyBatis`,`MySQL`,爬虫功能基于`JDBookCrawler 2.0`,前端设计参考项目[`springboot-beginner`](https://github.com/YUbuntu0109/springboot-beginner),简单点说`v3.0`就等于`v2.0` + `springboot`,😅不尴尬嘿嘿嘿~*
### 开发环境
| 工具 | 版本或描述 |
| ------- | ------------------------ |
| `OS` | Windows 10 |
| `JDK` | 1.8 |
| `IDE` | IntelliJ IDEA 2019.1 |
| `Maven` | 3.6.0 |
| `MySQL` | 8.0.11 |
> 本项目的数据库版本为`8.0.11`,请广大版本为`5.0.0+`的同学注意咯:可通过逐个复制表结构来创建该数据库哟 ~
### 项目概述( `JDBookCrawler 3.0` )
> 除此项目概述外,你也可以参考 : [博客文章](https://yubuntu0109.github.io/2019/07/17/%E5%B0%8F%E7%88%AC%E8%99%AB-JDBookCrawler-V3-0/)
#### 项目结构图
```
├─bookcrawler-v3.0
│ │ crawler.sql
│ │ pom.xml
│ │
│ │
│ └─src
│ └─main
│ ├─java
│ │ └─pers
│ │ └─huangyuhui
│ │ └─bookcrawler
│ │ │ BookcrawlerApplication.java
│ │ │
│ │ ├─controller
│ │ │ BookController.java
│ │ │
│ │ ├─crawler
│ │ │ │ BookCrawlerTest.java
│ │ │ │
│ │ │ ├─dao
│ │ │ │ BookDao.java
│ │ │ │
│ │ │ ├─mapper
│ │ │ │ BookMapper.xml
│ │ │ │
│ │ │ ├─pojo
│ │ │ │ Book.java
│ │ │ │
│ │ │ ├─resources
│ │ │ │ db.properties
│ │ │ │ log4j.properties
│ │ │ │ mybatis-config.xml
│ │ │ │
│ │ │ ├─task
│ │ │ │ BookProcessor.java
│ │ │ │
│ │ │ └─util
│ │ │ FileUtils.java
│ │ │ HttpUtils.java
│ │ │ MyBatisUtils.java
│ │ │
│ │ ├─dao
│ │ │ BookMapper.java
│ │ │ BookMapper.xml
│ │ │
│ │ ├─pojo
│ │ │ Book.java
│ │ │
│ │ └─service
│ │ │ BookService.java
│ │ │
│ │ └─impl
│ │ BookServiceImpl.java
│ │
│ └─resources
│ │ application.properties
│ │
│ ├─static
│ │ │ exist.txt
│ │ │
│ │ └─easyui
│ │ │ jquery.easyui.min.js
│ │ │ jquery.min.js
│ │ │
│ │ ├─css
│ │ │ default.css
│ │ │ demo.css
│ │ │
│ │ ├─js
│ │ │ outlook2.js
│ │ │ validateExtends.js
│ │ │
│ │ └─themes
| | |
│ │ |(略..)
│ │
| |
│ └─templates
│ bookList.html
│ intro.html
│ main.html
│
└─demonstration-images
BookCrawler-V3.0-bookList.PNG
BookCrawler-V3.0-Intro.PNG
```
> `crawler`包存放的是`JDBookCrawler-v2.0`,既`3.0`使用了`2.0`的爬虫功能,其本身仅加入了页面可视化功能
#### 运行指南
1. *crawler.sql : 数据库文件*
```
BookCrawler-v3.0/bookcrawler-v3.0/crawler.sql
```
2. *BookCrawlerTest.java : 爬虫启动程序*
```java
package pers.huangyuhui.bookcrawler.crawler;
import pers.huangyuhui.bookcrawler.crawler.task.BookProcessor;
import pers.huangyuhui.bookcrawler.crawler.util.FileUtils;
/**
* @project: bookcrawler
* @description: 爬虫测试程序
* @author: 黄宇辉
* @date: 7/11/2019-9:12 PM
* @version: 2.0
* @website: https://yubuntu0109.github.io/
*/
public class BookCrawlerTest {
//指定图书关键字
private static final String KEY_WORD = "网络爬虫";
//指定页码数,每页可爬取三十条数据( 注:下一页的页码数为前一页的页码数加二 )
private static final int END_PAGE_NUM = 2;
private static final int CURRENT_PAGE_NUM = 1;
//指定项目下存储书籍图片的文件夹路径
private static final String IMAGE_PATH = FileUtils.getDirPath("/static/download/bookImage/");
//指定JD商城书籍列表页面的链接
private static final String URL = "https://search.jd.com/Search?keyword=" + KEY_WORD + "&enc=utf-8&page=";
/**
* @description: 启动爬虫程序
* @date: 2019-07-15 4:09 PM
*/
public static void main(String[] args) {
new BookProcessor(URL, IMAGE_PATH, CURRENT_PAGE_NUM, END_PAGE_NUM).run();
}
}
```
> 启动爬虫后其控制台输出的日志信息请参考 : [`JDBookCrawler v2.0`](https://yubuntu0109.github.io/2019/07/15/%E5%B0%8F%E7%88%AC%E8%99%AB-JDBookCrawler-V2-0/)
3. *BookcrawlerApplication.java : 项目启动类( 爬虫程序成功运行完成后,就可以启动该`springboot`项目啦,这操作不尴尬哈哈哈 ~ )*
```java
package pers.huangyuhui.bookcrawler;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
/**
* @project: bookcrawler
* @description: springboot项目启动类
* @author: 黄宇辉
* @date: 7/11/2019-9:16 PM
* @version: 3.0
* @website: https://yubuntu0109.github.io/
*/
@SpringBootApplication
@MapperScan("pers.huangyuhui.bookcrawler.dao") //扫描Mapper接口
public class BookcrawlerApplication {
public static void main(String[] args) { SpringApplication.run(BookcrawlerApplication.class, args); }
}
```
4. *项目成功启动后,其项目主页,图书数据管理页如下图所示 :*
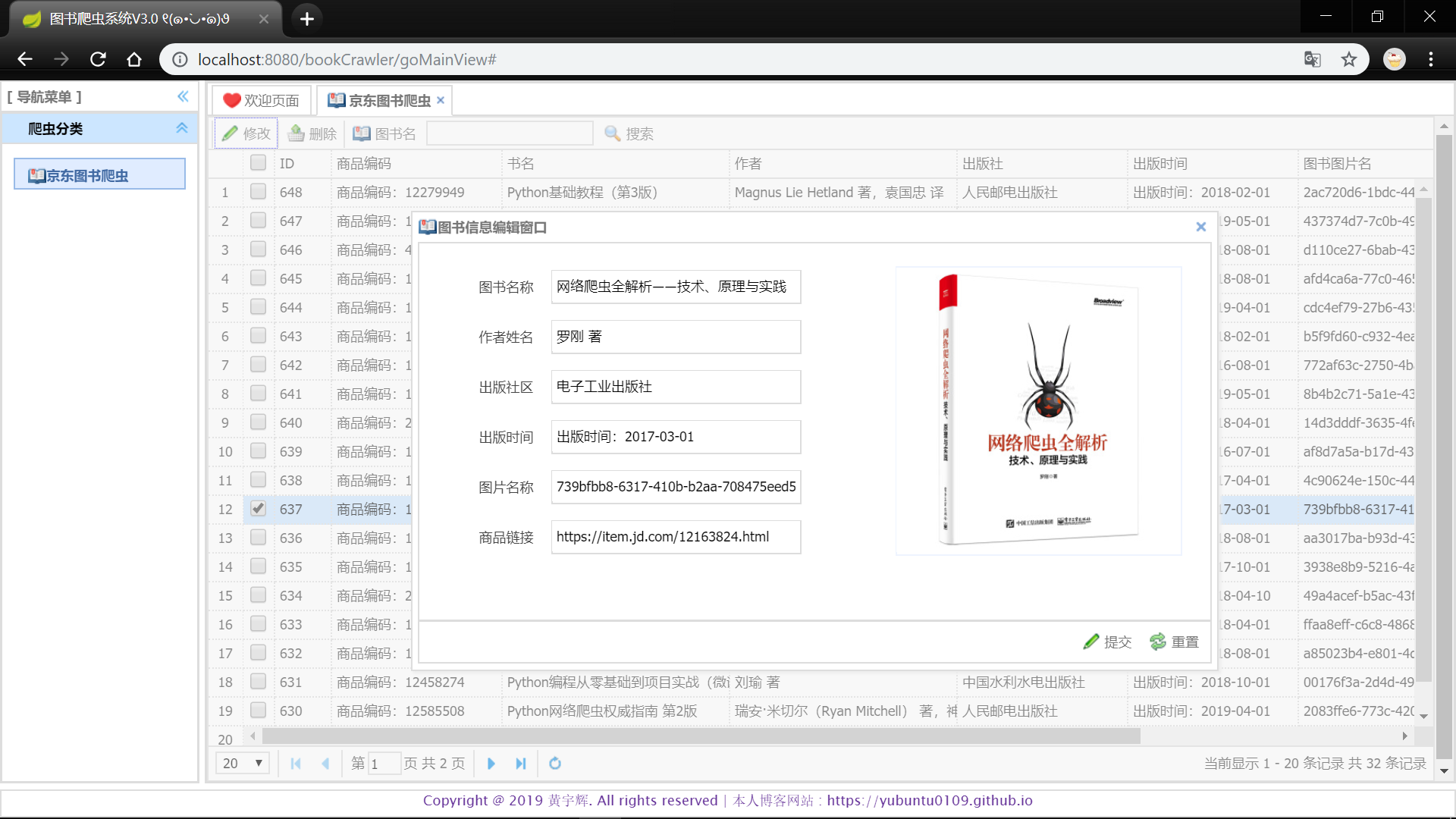
*:books:更多有趣项目及详细学习笔记请前往我的个人博客哟(づ ̄3 ̄)づ╭❤~ : https://yubuntu0109.github.io/*
*👩💻学习笔记已全部开源 : https://github.com/YUbuntu0109/YUbuntu0109.github.io*
*:coffee: Look forward to your contribution, if you need any help, please contact me~ QQ : 3083968068*