https://github.com/gordon801/us-medicare-fraud
Machine learning methods applied to US Medicare data to predict the fraudulency of US Medicare Providers. (Python)
https://github.com/gordon801/us-medicare-fraud
Last synced: 2 months ago
JSON representation
Machine learning methods applied to US Medicare data to predict the fraudulency of US Medicare Providers. (Python)
- Host: GitHub
- URL: https://github.com/gordon801/us-medicare-fraud
- Owner: gordon801
- Created: 2021-07-22T09:10:59.000Z (almost 4 years ago)
- Default Branch: main
- Last Pushed: 2021-07-31T16:38:54.000Z (almost 4 years ago)
- Last Synced: 2025-01-21T20:09:03.051Z (4 months ago)
- Language: Python
- Homepage:
- Size: 33.2 KB
- Stars: 0
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# US Medicare Fraud Analysis
## Overview
In this project, US Medicare data was used to build and assess several predictive models for the purpose of classifying known Healthcare Providers as fraudulent. The best-performing predictive model was then used to analyse unknown Providers to flag as potentially fraudulent.
The following statistical learning methods were considered:
* Logistic Regression with L2 Regularisation (Ridge Regression)
* Logistic Regression with L1 Regularisation (Lasso)
* K-Nearest Neighbours
* Random Forest
* Improved Random Forest (using feature importance)
* Linear Discriminant Analysis (LDA)
* Quadratic Discriminant Analysis (QDA)
* Support Vector Machine (SVM)
The models are assessed based on their Area under the ROC Curve (AUC) score and any model predictions used are based on the probability threshold that maximises Youden's J statistic (i.e. max(TPR - FPR)). In other words, statistics such as the confusion matrix, accuracy, sensitivity, specificity, and F1-Score are calculated using this set of predictions. Also, where applicable, cross-validation has been applied to tune each of the models' hyper-parameters to ensure an optimal fit.
The Improved Random Forest model was assessed to be the best-performing model in terms of AUC, and was used to produce the ultimate set of predictions for the unknown Providers.
## Input Data
Input data was too large to upload, but can be viewed/downloaded here: https://drive.google.com/drive/folders/1Vovj_PTrj3HF5dXWZ1peZ-eW9vy1W3bG?usp=sharing
### Training Data (used to train the models):
* Medicare_Outpatient_Inpatient_Beneficiary_PartB.csv: Patient claims data consisting of 436,254 individual claims with 55 different features.
* Medicare_Provider_PartB.csv: Provider data consisting of 4,436 US Medicare Providers and a categorical indicator for fraudulency.
### Evaluation Data (unknown data used by the final model for prediction):
* Medicare_Outpatient_Inpatient_Beneficiary_PartB.csv: Patient claims data consisting of 121,957 individual claims with the same 55 features.
* Medicare_Provider_PartB.csv: 975 US Medicare Providers with an unknown fraudulency status.
## Results
### Logistic Regression with Ridge Regression:

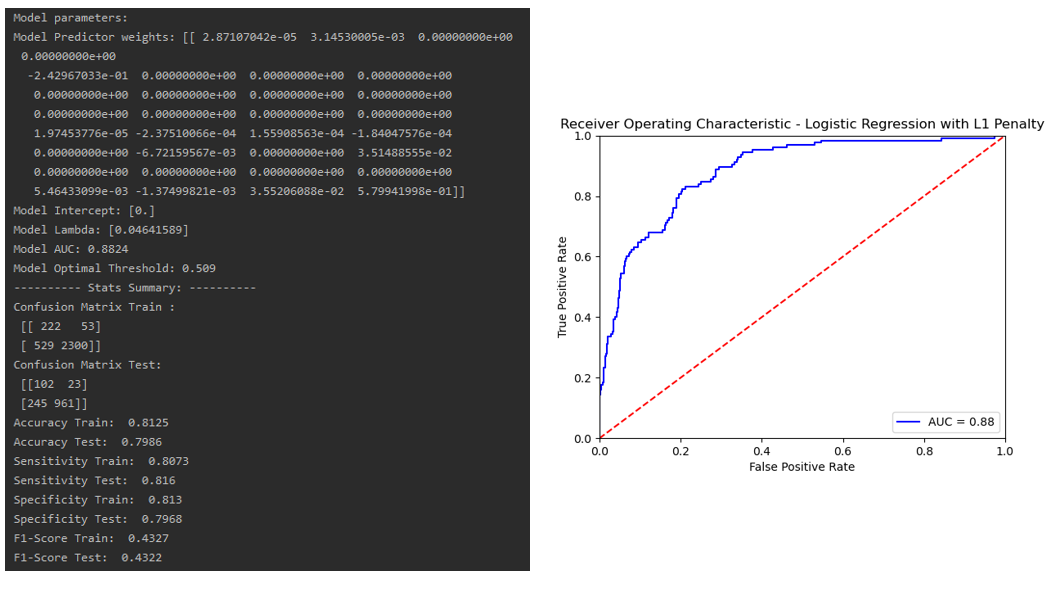
### Logistic Regression with Lasso:
### K-Nearest Neighbours:

### Random Forest:

A feature importance chart was generated for this Random Forest model and the highlighted features were used as the sole predictors in the Improved Random Forest model.

### Improved Random Forest:

### LDA:

### QDA:

### SVM:

## Conclusion
The Improved Random Forest performed the best out of all the statistical learning methods with an AUC of 0.9144, and was therefore selected to predict fraudulency status using the unknown dataset.
## Output
Provider_Fraud_Results.csv: Output table consisting of the 975 unknown US Medicare Providers with their predicted fraudulency status and associated fraudulency probabilities.