Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/gummif/fastarrayops.jl
Fast inplace Array floating point operations for Julia
https://github.com/gummif/fastarrayops.jl
Last synced: about 1 month ago
JSON representation
Fast inplace Array floating point operations for Julia
- Host: GitHub
- URL: https://github.com/gummif/fastarrayops.jl
- Owner: gummif
- License: other
- Created: 2014-10-29T00:07:09.000Z (about 10 years ago)
- Default Branch: master
- Last Pushed: 2016-10-01T17:10:28.000Z (over 8 years ago)
- Last Synced: 2024-10-15T15:11:54.865Z (3 months ago)
- Language: Julia
- Homepage:
- Size: 1.6 MB
- Stars: 1
- Watchers: 1
- Forks: 2
- Open Issues: 2
-
Metadata Files:
- Readme: README.md
- License: LICENSE.md
Awesome Lists containing this project
README
*WARNING*: This package is not maintained and is deprecated.
FastArrayOps.jl
===============
[](https://travis-ci.org/gummif/FastArrayOps.jl)
[](https://coveralls.io/r/gummif/FastArrayOps.jl)
A [Julia](https://github.com/JuliaLang/julia) package for fast general inplace element-wise operations for floating point Arrays.
Contains a large collection of benchmarks in `/perf`. They (should) show that the functions in this package provide the fastest way of performing the specified operation in julia, on average over a large range of parameters.
Different or new implementations or benchmark cases are welcome as issues or pull requests.
Benchmarks are currently under developement for all cases and performance will likely improve as the benchmarks become more exstensive.
See license (MIT) in LICENSE.md.
Usage
---------
Install via the package manager and load with `using`
```julia
julia> Pkg.add("FastArrayOps")
julia> using FastArrayOps
```
*Warning:* Many of the functions in the package might be slower than the equivalent function in `Base` for one-time evaluation (compile time in particular). If used multiple times in a code (e.g. loops or iterations) performance gains become more noticable.
API
---------
* All functions have inplace and out-of-place versions, overwriting the first argument.
* No Array allocations.
* Element types supported are real and complex floating point numbers (`Float32, Float64, Complex64, Complex128`)
* `x,y,z` are Arrays of any size, `a` is a scalar, `incx` is the stride of `x`, `ix` is the starting index of `x`, `n` is the number of elements to use or modify. A negative stride `incx` reverses the indexing order. Negative `incx` is however not supported for methods with only 1 Array argument.
* All functions `f` have an `unsafe_f` version without any argument or bounds checks (e.g. `unsafe_fast_scale!`).
#### General methods (slower)
```julia
# scale by scalar
fast_scale!(x, ix, incx, a, n) # x = a*x
fast_scale!(x, ix, incx, y, iy, incy, a, n) # x = a*y
# scale by array
fast_scale!(x, ix, incx, y, iy, incy, n) # x = x.*y
fast_scale!(x, ix, incx, y, iy, incy, z, iz, incz, n) # x = y.*z
# add scalar
fast_add!(x, ix, incx, a, n) # x = x + a
fast_add!(x, ix, incx, y, iy, incy, a, n) # x = y + a
# add array
fast_add!(x, ix, incx, y, iy, incy, n) # x = x + y
fast_add!(x, ix, incx, y, iy, incy, z, iz, incz, n) # x = y + z
# add array times scalar
fast_addscal!(x, ix, incx, y, iy, incy, a, n) # x = x + a*y
fast_addscal!(x, ix, incx, y, iy, incy, z, iz, incz, a, n) # x = y + a*z
# copy array
fast_copy!(x, ix, incx, y, iy, incy, n) # x = y
# fill
fast_fill!(x, ix, incx, a, n) # x = a
```
```julia
# utilities
fast_check1(x, ix, incx, n) # bounds check functions
fast_check2(x, ix, incx, y, iy, incy, n)
fast_check3(x, ix, incx, y, iy, incy, z, iz, incz, n)
nmax2nel(i, inc, nmax) # number of elements given max index
nel2nmax(i, inc, nel) # max index for nmax2nel returning nel
fast_args2range(i, inc, n) # convert FAO arguments to index range
fast_range2args(r) # inverse of fast_args2range
```
#### Faster Methods
There are faster methods than the above general methods, which are called by supplying fewer arguments, meaning a more specific and faster method. Method kinds:
* *general*
* `fast_scale!(x, ix, incx, y, iy, incy, a, n)`
* *inceq*: all `inc` arguments are equal, exclude all but `incx`
* `fast_scale!(x, ix, incx, y, iy, a, n)`
* *inc1*: all `inc` arguments are equal to 1, exclude all `inc`
* `fast_scale!(x, ix, y, iy, a, n)`
* *inc1ieq*: all `inc` arguments are equal to 1 and all `i` arguments are equal, exclude all `inc` and exclude all but `ix`
* `fast_scale!(x, ix, y, a, n)`
Benchmarks
---------
See directory `/perf` for code and setup details and further results.
##### Op `x = a*x`


Scale columns of a `n` by `16` matrix by the first row elements.
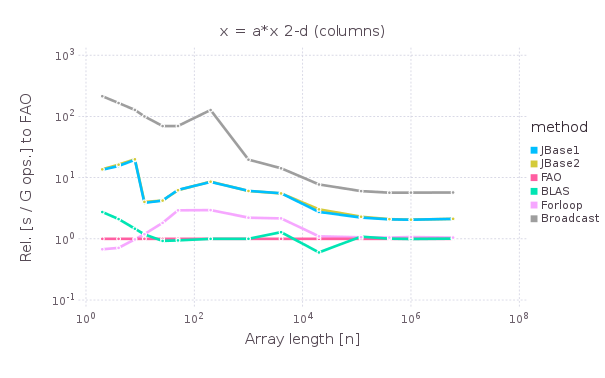
##### Op `x = a*y`
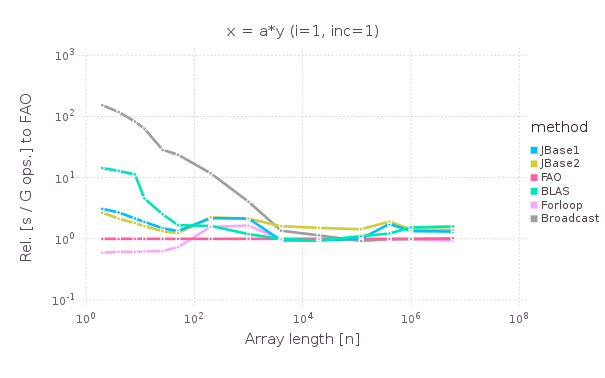
##### Op `x = a`

##### Op `x = x + y`

##### Op `x = y + z`

TODO
---------
* add inceqieq macros