https://github.com/gurleensethi/codeinfoextractor
An application for parsing out comment information from source code.
https://github.com/gurleensethi/codeinfoextractor
gradle java parser
Last synced: 2 months ago
JSON representation
An application for parsing out comment information from source code.
- Host: GitHub
- URL: https://github.com/gurleensethi/codeinfoextractor
- Owner: gurleensethi
- Created: 2020-10-03T03:47:52.000Z (over 5 years ago)
- Default Branch: master
- Last Pushed: 2020-10-20T21:36:16.000Z (over 5 years ago)
- Last Synced: 2025-08-11T04:28:21.622Z (11 months ago)
- Topics: gradle, java, parser
- Language: Java
- Homepage:
- Size: 120 KB
- Stars: 0
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# CodeInfoExtractor
An application for parsing out comment information from source code.
## Running the project
### From the command line using gradle
Make sure you have gradle installed on your local machine.
```cmd
./gradlew run --args ""
```
Example usage:
#### Single File
```cmd
./gradlew run --args samplefiles/SampleFile.java
```
#### Multiple Files
```cmd
./gradlew run --args "samplefiles/SampleFile.java samplefiles/sample-file.ts samplefiles/sample_file.py"
```
### Using `jar` file
#### Prebuilt `jar` file
Download the jar file from the latest [release](https://github.com/gurleensethi/CodeInfoExtractor/releases).
```cmd
java -jar codeinfoextractor.jar samplefiles/SampleFile.java
```
#### Manually building `jar` file
Build the jar.
```cmd
./gradle jar
```
Run using built jar (The built jar file can be found in `build/libs/`).
```cmd
java -jar build/libs/codeinfoextractor.jar samplefiles/SampleFile.java
```
## Design Overview
The core consists of 3 main parts, `InfoExtractor`, `FileLoader` and `ILanguageParser`. Below is a diagramtic representation of the design.
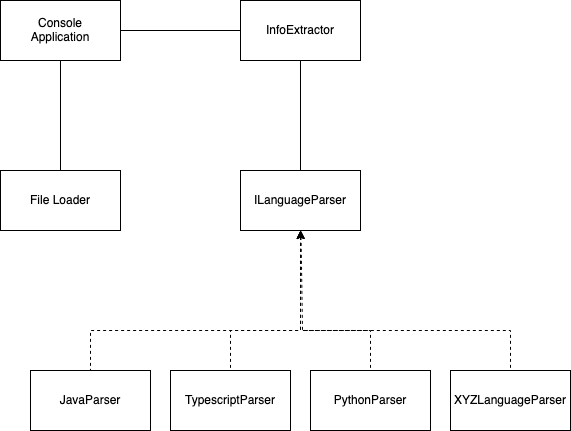
- **ILanguageParser**: Contract that every parser should implement. It contains one method named `parse(String data)` that takes in data as `String` read from the passed file. A parser should implement the parsing logic in this method and return `LanguageParserResult`.
- **FileLoader**: Helps in loading code files and filtering out ones that are inappropriate (such as files with no extensions).
- **InfoExtractor**: Main class to be used for parsing the code data. With the concept of factory method pattern it allows seamless registration of new parsers.
#### `InfoExtractor` usage
```java
InfoExtractor infoExtractor = new InfoExtractor();
infoExtractor.registerParser("java", JavaParser::new);
infoExtractor.registerParser("ts", TypescriptParser::new);
infoExtractor.registerParser("py", PythonParser::new);
final List results = infoExtractor.parseFiles(sourceCodeFileList);
```
## Adding New Parsers
To add a new parser:
- Implement the `ILanguageParser` interface and add the desired logic in `parse` method.
```java
public class MyParser implements ILanguageParser {
@Override
public LanguageParseResult parse(String data) {
final LanguageParseResult result = new LanguageParseResult();
// My parsing logic.
return result;
}
}
```
- Register the parser when using `InfoExtractor` along with the extension of file for which the parser should be used.
```java
InfoExtractor infoExtractor = new InfoExtractor();
infoExtractor.registerParser("myextension", MyParser::new);
```
## Prewritten parsers
The project already contains parsers for `Java`, `Python` and `Typescript`. These can be found in the `codeinfoextractor.parsers` package.
All of these parsers use `regex` to find comments in source code.
Below are some assumptions made when writing these parsers:
- Java/Typescript:
- Single line comments start with `//`.
- Block comments start with `/*` and end when the closest `*/` is found.
- Python:
- Single line comments start with `#` and don't have any other line before or after starting with `#`.
- Block comments start each line with `#`. There has to be 2 or more contiguous lines start with `#` to be considered as block comments.
#### False positives
Although the regex used in the prewritten parsers can detect single-line and block comments, they can also provide false-positives in some cases.
Example:
```java
// This is a comment
System.out.println("// This is not a comment");
```
The java parser will detect two comments in this case.
These parsers can be improvd later on without affecting rest of the project since every parser is isolated.