https://github.com/hardmaru/estool
Evolution Strategies Tool
https://github.com/hardmaru/estool
Last synced: about 1 year ago
JSON representation
Evolution Strategies Tool
- Host: GitHub
- URL: https://github.com/hardmaru/estool
- Owner: hardmaru
- License: other
- Created: 2017-10-29T07:20:10.000Z (over 8 years ago)
- Default Branch: master
- Last Pushed: 2022-12-08T10:43:25.000Z (over 3 years ago)
- Last Synced: 2024-11-13T21:44:26.311Z (over 1 year ago)
- Language: Jupyter Notebook
- Size: 7.05 MB
- Stars: 936
- Watchers: 32
- Forks: 163
- Open Issues: 8
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
- awesome-deep-reinforcement-learning - hardmaru/estool
- awesome-list - ESTool - Evolution Strategies Tool. (Machine Learning Framework / General Purpose Framework)
README
# ESTool

Evolved Biped Walker.
Implementation of various Evolution Strategies, such as GA, Population-based REINFORCE (Section 6 of [Williams 1992](http://www-anw.cs.umass.edu/~barto/courses/cs687/williams92simple.pdf)), CMA-ES and OpenAI's ES using common interface.
CMA-ES is wrapping around [pycma](https://github.com/CMA-ES/pycma).
# Notes
The tool last tested using the following configuration:
- NumPy 1.13.3 (1.14 has some annoying warning).
- OpenAI Gym 0.9.4 (breaks for 0.10.0+ since they changed the API).
- cma 2.2.0, basically 2+ should work.
- PyBullet 1.6.3 (possible that newer versions might work, but have not tested).
- Python 3, although 2 might work.
- mpi4py 2
## Backround Reading:
[A Visual Guide to Evolution Strategies](http://blog.otoro.net/2017/10/29/visual-evolution-strategies/)
[Evolving Stable Strategies](http://blog.otoro.net/2017/11/12/evolving-stable-strategies/)
## Using Evolution Strategies Library
To use es.py, please check out the `simple_es_example.ipynb` notebook.
The basic concept is:
```
solver = EvolutionStrategy()
while True:
# ask the ES to give us a set of candidate solutions
solutions = solver.ask()
# create an array to hold the solutions.
# solver.popsize = population size
rewards = np.zeros(solver.popsize)
# calculate the reward for each given solution
# using your own evaluate() method
for i in range(solver.popsize):
rewards[i] = evaluate(solutions[i])
# give rewards back to ES
solver.tell(rewards)
# get best parameter, reward from ES
reward_vector = solver.result()
if reward_vector[1] > MY_REQUIRED_REWARD:
break
```
## Parallel Processing Training with MPI
Please read [Evolving Stable Strategies](http://blog.otoro.net/2017/11/12/evolving-stable-strategies/) article for more demos and use cases.
To use the training tool (relies on MPI):
```
python train.py bullet_racecar -n 8 -t 4
```
will launch training jobs with 32 workers (using 8 MPI processes). the best model will be saved as a .json file in log/. This model should train in a few minutes on a 2014 MacBook Pro.
If you have more compute and have access to a 64-core CPU machine, I recommend:
```
python train.py name_of_environment -e 16 -n 64 -t 4
```
This will calculate fitness values based on an average of 16 random runs, on 256 workers (64 MPI processes x 4). In my experience this works reasonably well for most tasks inside `config.py`.
After training, to run pre-trained models:
```
python model.py bullet_ant log/name_of_your_json_file.json
```
### Self-Contained Cartpole Swingup Task
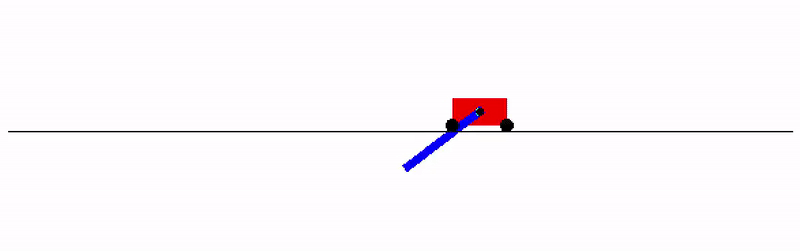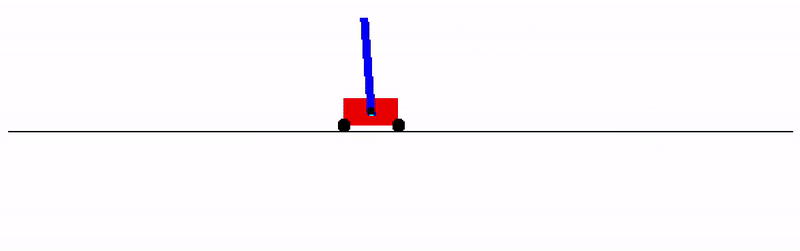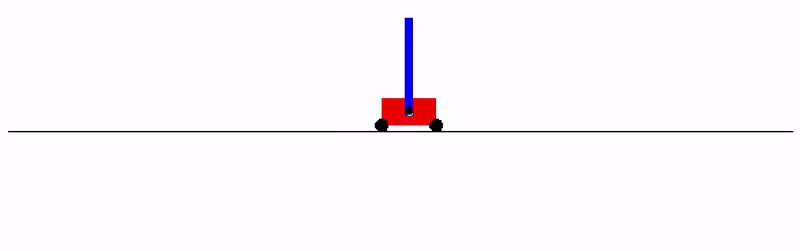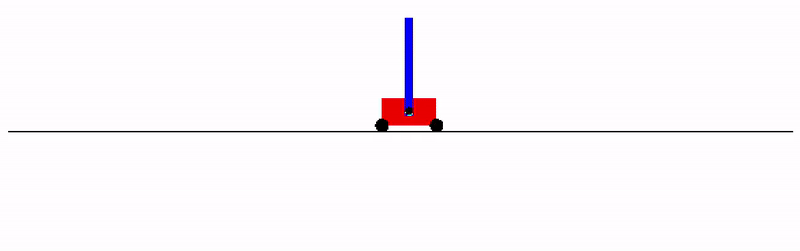
If you don't want to install a physics engine, try it on the `cartpole_swingup` task that doesn't have any dependencies:
Training command:
```
python train.py cartpole_swingup -n 8 -e 1 -t 4 --sigma_init 1.0
```
After 400 generations, the final average score (over 32 trials) should be over 900. You can run it with this command:
```
python model.py cartpole_swingup log/cartpole_swingup.cma.1.32.best.json
```
If you haven't bothered to run the previous training command, you can load the pre-trained version:
```
python model.py cartpole_swingup zoo/cartpole_swingup.cma.json
```
### Self-Contained Slime Volleyball Gym Environment
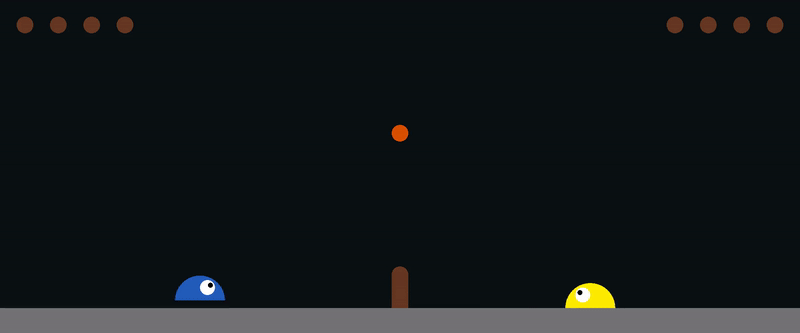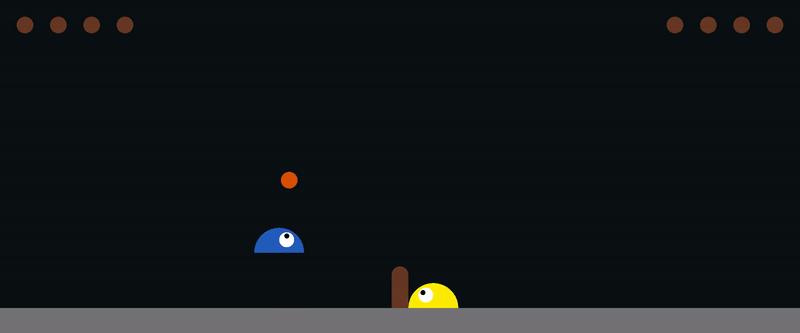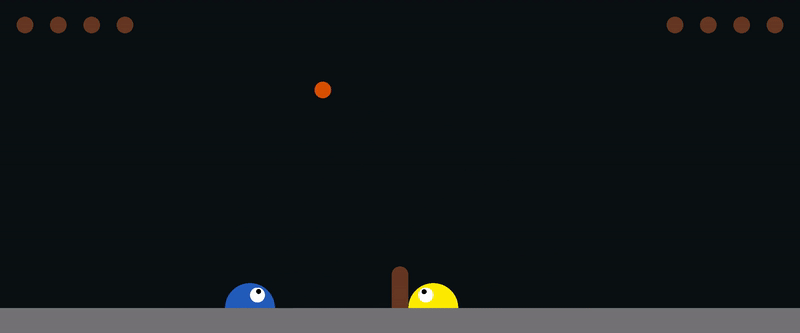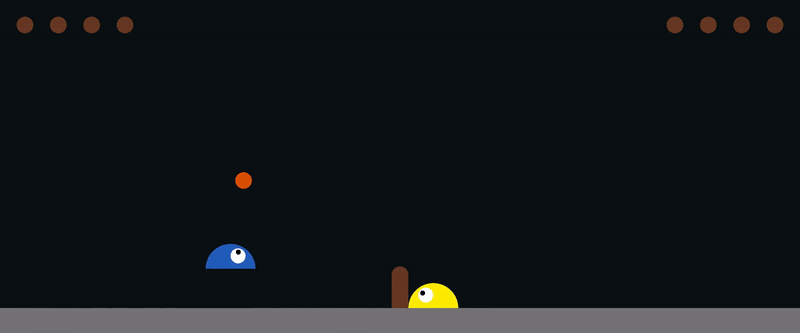
Here is an example for training [slime volleyball gym](https://github.com/hardmaru/slimevolleygym) environment:
Training command:
```
python train.py slimevolley -n 8 -e 8 -t 4 --sigma_init 0.5
```
Pre-trained model:
```
python model.py slimevolley zoo/slimevolley.cma.64.96.best.json
```
### PyBullet Envs

bullet_ant pybullet environment. Population-based REINFORCE.
Another example: to run a minitaur duck model, run this locally:
```
python model.py bullet_minitaur_duck zoo/bullet_minitaur_duck.cma.256.json
```

Custom Minitaur Env.
In the .hist.json file, and on the screen output, we track the progress of training. The ordering of fields are:
- generation count
- time (seconds) taken so far
- average fitness
- worst fitness
- best fitness
- average standard deviation of params
- average timesteps taken
- max timesteps taken
Using `plot_training_progress.ipynb` in an IPython notebook, you can plot the traning logs for the `.hist.json` files. For example, in the `bullet_ant` task:

Bullet Ant training progress.
You need to install mpi4py, pybullet, gym etc to use various environments. Also roboschool/Box2D for some of the OpenAI gym envs.
On Windows, it is easiest to install mpi4py as follows:
- Download and install mpi_x64.Msi from the HPC Pack 2012 MS-MPI Redistributable Package
- Install a recent Visual Studio version with C++ compiler
- Open a command prompt
```
git clone https://github.com/mpi4py/mpi4py
cd mpi4py
python setup.py install
```
Modify the train.py script and replace mpirun with mpiexec and -np with -n
### Citation
If you find this work useful, please cite it as:
```
@article{ha2017evolving,
title = "Evolving Stable Strategies",
author = "Ha, David",
journal = "blog.otoro.net",
year = "2017",
url = "http://blog.otoro.net/2017/11/12/evolving-stable-strategies/"
}
```