https://github.com/hereismari/tensorflow-maml
TensorFlow 2.0 implementation of MAML.
https://github.com/hereismari/tensorflow-maml
eager-execution maml meta-learning tensorflow tensorflow2
Last synced: about 1 year ago
JSON representation
TensorFlow 2.0 implementation of MAML.
- Host: GitHub
- URL: https://github.com/hereismari/tensorflow-maml
- Owner: hereismari
- License: apache-2.0
- Created: 2019-04-09T20:05:55.000Z (about 7 years ago)
- Default Branch: master
- Last Pushed: 2019-07-12T20:03:49.000Z (almost 7 years ago)
- Last Synced: 2025-03-30T13:51:16.248Z (over 1 year ago)
- Topics: eager-execution, maml, meta-learning, tensorflow, tensorflow2
- Language: Jupyter Notebook
- Homepage:
- Size: 2.26 MB
- Stars: 83
- Watchers: 2
- Forks: 21
- Open Issues: 2
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# Reproduction of MAML using TensorFlow 2.0.
This reproduction is highly influenced by the pytorch reproduction by Adrien Lucas Effot available at [Paper repro: Deep Metalearning using “MAML” and “Reptile”](https://towardsdatascience.com/paper-repro-deep-metalearning-using-maml-and-reptile-fd1df1cc81b0).
**MAML** | **Neural Net**
 

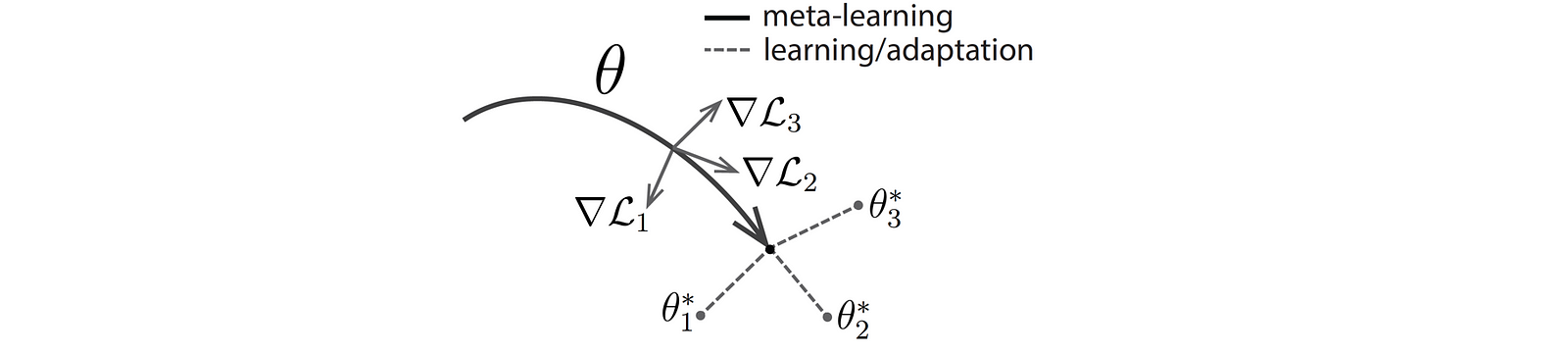
## MAML paper
https://arxiv.org/abs/1703.03400
**Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks**
*Chelsea Finn, Pieter Abbeel, Sergey Levine*
> We propose an algorithm for meta-learning that is model-agnostic, in the sense that it is compatible with any model trained with gradient descent and applicable to a variety of different learning problems, including classification, regression, and reinforcement learning. The goal of meta-learning is to train a model on a variety of learning tasks, such that it can solve new learning tasks using only a small number of training samples. In our approach, the parameters of the model are explicitly trained such that a small number of gradient steps with a small amount of training data from a new task will produce good generalization performance on that task. In effect, our method trains the model to be easy to fine-tune. We demonstrate that this approach leads to state-of-the-art performance on two few-shot image classification benchmarks, produces good results on few-shot regression, and accelerates fine-tuning for policy gradient reinforcement learning with neural network policies.
---