https://github.com/higgsfield-ai/higgsfield
Fault-tolerant, highly scalable GPU orchestration, and a machine learning framework designed for training models with billions to trillions of parameters
https://github.com/higgsfield-ai/higgsfield
cluster-management deep-learning distributed llama llama2 llm machine-learning mlops pytorch
Last synced: 7 months ago
JSON representation
Fault-tolerant, highly scalable GPU orchestration, and a machine learning framework designed for training models with billions to trillions of parameters
- Host: GitHub
- URL: https://github.com/higgsfield-ai/higgsfield
- Owner: higgsfield-ai
- License: apache-2.0
- Created: 2018-05-26T22:47:43.000Z (about 8 years ago)
- Default Branch: main
- Last Pushed: 2024-05-25T17:43:07.000Z (about 2 years ago)
- Last Synced: 2025-12-11T05:25:06.072Z (8 months ago)
- Topics: cluster-management, deep-learning, distributed, llama, llama2, llm, machine-learning, mlops, pytorch
- Language: Jupyter Notebook
- Homepage:
- Size: 4.83 MB
- Stars: 3,509
- Watchers: 72
- Forks: 585
- Open Issues: 5
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
- StarryDivineSky - higgsfield-ai/higgsfield - 3 deepspeed API 和 PyTorch 的全分片数据并行 API,实现万亿参数模型的高效分片。提供一个框架,用于在分配的节点上启动、执行和监控大型神经网络的训练。通过维护用于运行试验的队列来管理资源争用。通过与 GitHub 和 GitHub Actions 的无缝集成,促进机器学习开发的持续集成,Higgsfield 简化了训练大型模型的过程,并为开发人员提供了多功能且强大的工具集。 (A01_文本生成_文本对话 / 大语言对话模型及数据)
- awesome-2026-ai-machine-learning-1000projects - higgsfield - tolerant, highly scalable GPU orchestration, and machine learning framework designed for training models from billions to trillions of parameters| (📚 Project Purpose / Machine Learning (Intermediate-Level)
README
# higgsfield - multi node training without crying
Higgsfield is an open-source, fault-tolerant, highly scalable GPU orchestration, and a machine learning framework designed for training models with billions to trillions of parameters, such as Large Language Models (LLMs).
[](https://badge.fury.io/py/higgsfield)
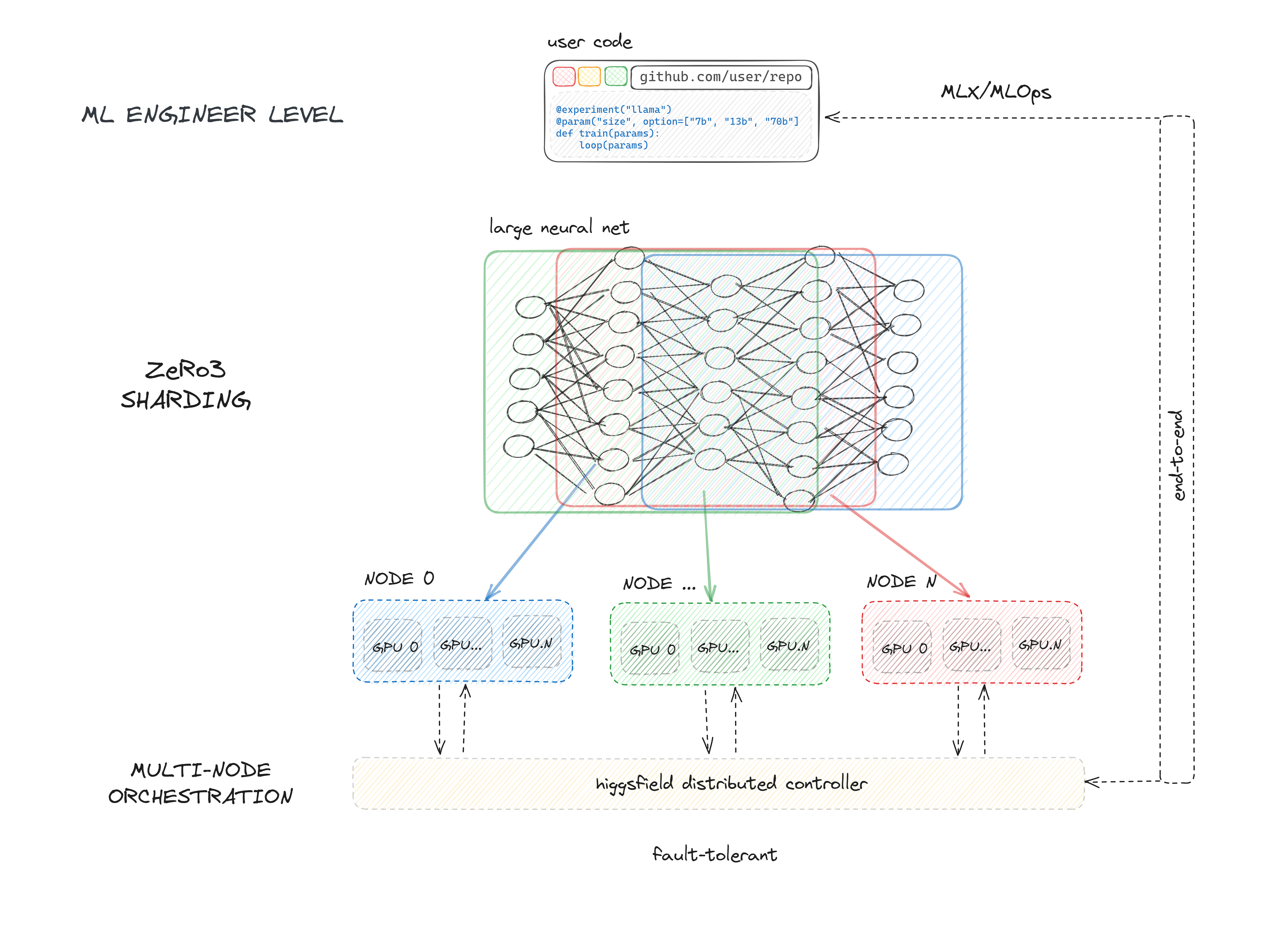
Higgsfield serves as a GPU workload manager and machine learning framework with five primary functions:
1. Allocating exclusive and non-exclusive access to compute resources (nodes) to users for their training tasks.
2. Supporting ZeRO-3 deepspeed API and fully sharded data parallel API of PyTorch, enabling efficient sharding for trillion-parameter models.
3. Offering a framework for initiating, executing, and monitoring the training of large neural networks on allocated nodes.
4. Managing resource contention by maintaining a queue for running experiments.
5. Facilitating continuous integration of machine learning development through seamless integration with GitHub and GitHub Actions.
Higgsfield streamlines the process of training massive models and empowers developers with a versatile and robust toolset.
## Install
```bash
$ pip install higgsfield==0.0.3
```
## Train example
That's all you have to do in order to train LLaMa in a distributed setting:
```python
from higgsfield.llama import Llama70b
from higgsfield.loaders import LlamaLoader
from higgsfield.experiment import experiment
import torch.optim as optim
from alpaca import get_alpaca_data
@experiment("alpaca")
def train(params):
model = Llama70b(zero_stage=3, fast_attn=False, precision="bf16")
optimizer = optim.AdamW(model.parameters(), lr=1e-5, weight_decay=0.0)
dataset = get_alpaca_data(split="train")
train_loader = LlamaLoader(dataset, max_words=2048)
for batch in train_loader:
optimizer.zero_grad()
loss = model(batch)
loss.backward()
optimizer.step()
model.push_to_hub('alpaca-70b')
```
## How it's all done?
1. We install all the required tools in your server (Docker, your project's deploy keys, higgsfield binary).
2. Then we generate deploy & run workflows for your experiments.
3. As soon as it gets into Github, it will automatically deploy your code on your nodes.
4. Then you access your experiments' run UI through Github, which will launch experiments and save the checkpoints.
## Design
We follow the standard pytorch workflow. Thus you can incorporate anything besides what we provide, `deepspeed`, `accelerate`, or just implement your custom `pytorch` sharding from scratch.
**Enviroment hell**
No more different versions of pytorch, nvidia drivers, data processing libraries.
You can easily orchestrate experiments and their environments, document and track the specific versions and configurations of all dependencies to ensure reproducibility.
**Config hell**
No need to define [600 arguments for your experiment](https://github.com/huggingface/transformers/blob/aaccf1844eccbb90cc923378e3c37a6b143d03fb/src/transformers/training_args.py#L161). No more [yaml witchcraft](https://hydra.cc/).
You can use whatever you want, whenever you want. We just introduce a simple interface to define your experiments. We have even taken it further, now you only need to design the way to interact.
## Compatibility
**We need you to have nodes with:**
- Ubuntu
- SSH access
- Non-root user with sudo privileges (no-password is required)
**Clouds we have tested on:**
- Azure
- LambdaLabs
- FluidStack
Feel free to open an issue if you have any problems with other clouds.
## Getting started
#### [Setup](./setup.md)
Here you can find the quick start guide on how to setup your nodes and start training.
- [Initialize the project](https://github.com/higgsfield/higgsfield/blob/main/setup.md#initialize-the-project)
- [Setup the environment](https://github.com/higgsfield/higgsfield/blob/main/setup.md#setup-the-environment)
- [Setup git](https://github.com/higgsfield/higgsfield/blob/main/setup.md#setup-git)
- [Time to setup your nodes!](https://github.com/higgsfield/higgsfield/blob/main/setup.md#time-to-setup-your-nodes)
- [Run your very first experiment](https://github.com/higgsfield/higgsfield/blob/main/setup.md#run-your-very-first-experiment)
- [Fasten your seatbelt, it's time to deploy!](https://github.com/higgsfield/higgsfield/blob/main/setup.md#fasten-your-seatbelt-its-time-to-deploy)
#### [Tutorial](./tutorial.md)
API for common tasks in Large Language Models training.
- [Working with distributed model](https://github.com/higgsfield/higgsfield/blob/main/tutorial.md#working-with-distributed-model)
- [Preparing Data](https://github.com/higgsfield/higgsfield/blob/main/tutorial.md#preparing-data)
- [Optimizing the Model Parameters](https://github.com/higgsfield/higgsfield/blob/main/tutorial.md#optimizing-the-model-parameters)
- [Saving Model](https://github.com/higgsfield/higgsfield/blob/main/tutorial.md#saving-model)
- [Training stabilization techniques](https://github.com/higgsfield/higgsfield/blob/main/tutorial.md#training-stabilization-techniques)
- [Monitoring](https://github.com/higgsfield/higgsfield/blob/main/tutorial.md#monitoring)
| Platform | Purpose | Estimated Response Time | Support Level |
| ----------------------------------------------------------------- | ----------------------------------------------------------------- | ----------------------- | --------------- |
| [Github Issues](https://github.com/higgsfield/higgsfield/issues/) | Bug reports, feature requests, install issues, usage issues, etc. | < 1 day | Higgsfield Team |
| [Twitter](https://twitter.com/higgsfield_ai/) | For staying up-to-date on new features. | Daily | Higgsfield Team |
| [Website](https://higgsfield.ai/) | Discussion, news. | < 2 days | Higgsfield Team |