https://github.com/hilmanski/contentswift
ContentSwift - Free content research / optimization tool for SEO. As an alternative for Surfer, Neuronwriter, Frase, etc..
https://github.com/hilmanski/contentswift
keyword seo seo-tools seooptimization seotools
Last synced: about 1 year ago
JSON representation
ContentSwift - Free content research / optimization tool for SEO. As an alternative for Surfer, Neuronwriter, Frase, etc..
- Host: GitHub
- URL: https://github.com/hilmanski/contentswift
- Owner: hilmanski
- Created: 2023-10-02T06:36:07.000Z (almost 3 years ago)
- Default Branch: main
- Last Pushed: 2023-10-31T01:09:53.000Z (over 2 years ago)
- Last Synced: 2025-04-14T23:43:59.218Z (about 1 year ago)
- Topics: keyword, seo, seo-tools, seooptimization, seotools
- Language: TypeScript
- Homepage:
- Size: 242 KB
- Stars: 130
- Watchers: 7
- Forks: 24
- Open Issues: 14
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
- awesome-seo-tools - ContentSwift - An open source content research/optimization tool for SEO. (Content Optimization)
- awesome-seo-mcp-servers - ContentSwift
README

# About
ContentSwift - Content research/optimization tool for SEO.
Watch [Demo Video at Youtube](https://www.youtube.com/watch?v=HL9sPYXd1Ws&t=115s)
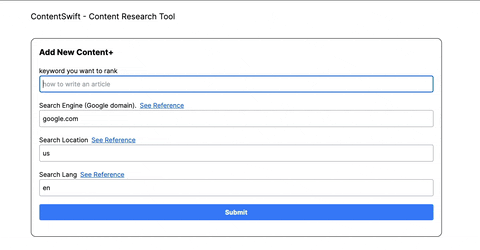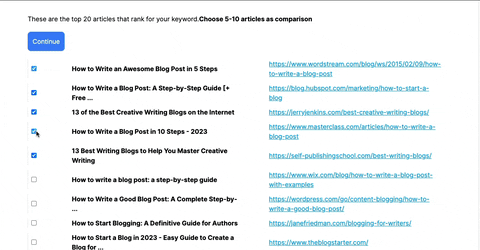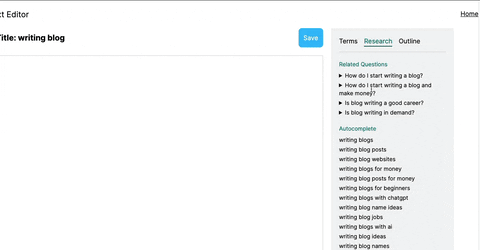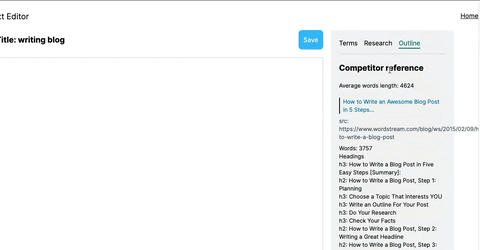
Using this tool, you'll get relevant information regarding specific keyword searches and hints on what other top-ranking results did with their article/page.

> Right now we're focusing on Google SERP only
The commercial version for this open-source tool would be something like Surfer SEO, Frase io, NeuronWriter, etc.. (of course, they offer more features than this).
- This is for personaluse. No authentication setup is needed in the app itself.
- Sign up to [SerpApi](https://serpapi.com?ref=contentswift) to get FREE Serp search results credit.
## Status
Under heavy development. Not for production.
## Tech
### Backend
`backend-crt` is a docker setup for:
- `fastApi` at `src` for main logic
- `Golang` at `go-app dir` for scraping helper // current free alt to prevent getting blocked
- `Postgre` as database
### Frontend
`frontend-crt` is manual `nextjs` installation
### Scrape API (SerpAPI)
Scraping Google search result on our own will require a lot of time to prevent us from getting blocked and getting the proper structure. That's why we're using simple solution from SerpApi.
### library used
There are many libraries used in this project, which is not possible to mention one by one.
- [NLTK](https://www.nltk.org/)
- [Newspaper](https://newspaper.readthedocs.io/en/latest/)
- [Beautifulsoup](https://pypi.org/project/beautifulsoup4/)
- [GoColly](https://github.com/gocolly/colly)
## Setup env file
- Create new empty `.env` file at `/backend-crt/src` folder
- Get your `API_KEY` from serpapi.com
- Paste your Serp api key in `.env` file at `backend-crt`
```
SERPAPI_KEY=$here_is_your_api_key
```
## Run the project
Make sure docker app is open
1. run backend (API)
```
cd backend-crt && docker-compose up -d --build
```
2. Setup Database (1 time only)
Cd into src
```
cd backend-crt/src
```
Activating a virtual env (setup if not yet)
```
source env/bin/activate
```
Run migration
```
python db/models.py
```
3. Run Frontend (API)
- Not inside python virtual env
- Now from root folder (another terminal or just go back).
```
cd frontend-crt && yarn dev
```
Project is available at http://localhost:3000
## TODO
- Add visual screenshot
- Add sample compare to other research tool
- add proper doc/landing page
- Add short video
## Potential Issue / improvement
- Remove code as part of word frequency: Ignore content between triple backtick
- User rotating-proxy to bypass individual web scraping (Find free proxy as a start)