https://github.com/homaei/rl-rpl-ua
A reinforcement learning-enhanced RPL protocol (RL-RPL-UA) for adaptive and energy-efficient routing in underwater IoT networks. Includes Aqua-Sim simulations, performance evaluation, and LaTeX source of the JITEL 2025 manuscript.
https://github.com/homaei/rl-rpl-ua
Last synced: 4 months ago
JSON representation
A reinforcement learning-enhanced RPL protocol (RL-RPL-UA) for adaptive and energy-efficient routing in underwater IoT networks. Includes Aqua-Sim simulations, performance evaluation, and LaTeX source of the JITEL 2025 manuscript.
- Host: GitHub
- URL: https://github.com/homaei/rl-rpl-ua
- Owner: Homaei
- License: gpl-3.0
- Created: 2025-06-20T19:02:37.000Z (12 months ago)
- Default Branch: main
- Last Pushed: 2025-06-20T19:36:08.000Z (12 months ago)
- Last Synced: 2025-06-20T20:28:04.234Z (12 months ago)
- Size: 806 KB
- Stars: 0
- Watchers: 0
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# 📡 RL-RPL-UA: Reinforcement Learning-Based Telematic Routing for the Internet of Underwater Things
This repository accompanies the paper titled:
**"A Reinforcement Learning-Based Telematic Routing Protocol for the Internet of Underwater Things"**
📝 Presented at the XVII Jornadas de Ingeniería Telemática (JITEL 2025), Cáceres, Spain
## 📄 Abstract
The Internet of Underwater Things (IoUT) faces challenges such as high latency, limited bandwidth, and energy constraints. Traditional routing protocols like RPL fall short in such environments. This work introduces **RL-RPL-UA**, an enhanced RPL-based routing protocol that integrates a lightweight reinforcement learning (RL) agent within each node to adaptively select the best parent based on local metrics like energy, link quality, buffer occupancy, and delivery history. Simulation results demonstrate that RL-RPL-UA significantly improves delivery ratio, energy efficiency, and network lifetime in both static and mobile underwater scenarios.
## 🔍 Highlights
- ✅ Lightweight Q-learning agent embedded in each node
- 📶 Dynamic parent selection based on local observations
- 🧠 Adaptive Objective Function (OF) replaces static RPL metrics
- 💡 Compatible with RPL control messages (DIO/DAO)
- 📊 Outperforms UWF-RPL, Co-DRAR, UA-RPL, and UWMRPL in Aqua-Sim simulations
## 🔍 Highlights of background
## 📊 Table 1 – Comparison of Recent Routing Protocols with RL-RPL-UA
| Protocol | RL | RPL | Adaptive OF | Mobility | Citation |
|----------------------------|------|-------|--------------------|----------|-----------------|
| C-GCo-DRAR | ❌ | ❌ | Static OF | Limited | Guo2023 |
| FLCEER | ❌ | ❌ | Static OF | Moderate | Natesan2020 |
| IDA-OEP | ❌ | ❌ | Static OF | Limited | Wang2024 |
| GTRP | ❌ | ❌ | Static OF | Moderate | Khan2021 |
| RL Protocol | ✅ | ❌ | Static OF | Moderate | Eris2024 |
| Q-Learning | ✅ | ❌ | Dynamic OF | Moderate | Nandyala2023 |
| Multi-agent RL | ✅ | ❌ | Static OF | High | Li2020 |
| UA-RPL | ❌ | ✅ | Static OF | Moderate | Liu2022 |
| URPL | ❌ | ✅ | Dynamic OF | Moderate | Tarifdm2024 |
| Fuzzy-CR | ❌ | ✅ | Decision Making | Moderate | Tariffuzzy2024 |
| UWF-RPL | ❌ | ✅ | Static Fuzzy OF | Moderate | Tarif2025 |
| UW/MRPL (prev. work) | ❌ | ✅ | Static OF | High | Homaei2025 |
| **RL-RPL-UA (this work)** | ✅ | ✅ | **Dynamic** | High | — |
## 📊 Table 2 – Key Differences Between UWF-RPL, UWMRPL, and RL-RPL-U
| Feature | UWF-RPL (Tarif2025) | UWMRPL (Homaei2025) | RL-RPL-UA (This Work) |
|----------------------|--------------------------------------------------|---------------------------------------------------|-------------------------------------------------------------|
| Main Concept | Fuzzy-logic RPL for optimized routing | Mobility-aware RPL with static tunable OF | RL-based dynamic routing with local agents |
| Routing Adaptability | Semi-adaptive via static fuzzy logic rules | Semi-adaptive via predefined logic | Fully adaptive via real-time RL updates |
| OF | Static fuzzy logic (depth, energy, latency, ETX)| Static/custom (ETX, depth) | Dynamic composite (energy, LQI, queue, PDR) |
| RPL Compatibility | Extended DIO/DAO with fuzzy logic metrics | Standard-compliant | Extended DIO/DAO with RL metrics |
| Learning Agent | None (static fuzzy logic) | None | Q-learning or DQN per node |
| Reward Mechanism | None | None | α·PDR − β·Delay − γ·Cost |
| Overhead | Moderate (fuzzy logic computations) | Low (no learning updates) | Low (optimized RL updates) |
| Mobility Handling | Reactive via fuzzy logic evaluation | Reactive DAG repair | Proactive via learned feedback |
| Queue Management | Included (congestion control) | Not included | Included (adaptive queue management) |
| Energy Efficiency | Good (static optimized) | Moderate (no dynamic optimization) | High (real-time optimization) |
| Key Contribution | Improved stability and efficiency via fuzzy logic | Mobility and energy-aware extension of RPL | Online adaptive parent selection via RL |
## 📊 Table 3 – Simulation Parameters
| Parameter | Value |
|---------------------------|--------------------------------|
| Simulation Area | 300 × 300 × 300 m³ |
| Number of Nodes | 50 |
| Initial Energy per Node | 5 J |
| Transmission Power | 0.5 W |
| Acoustic Bandwidth | 10 kHz |
| Propagation Speed | 1500 m/s |
| MAC Protocol | TDMA |
| Routing Protocols | RL-RPL-UA, RPL (OF0), Q-Routing|
| RL Algorithm | Q-learning (tabular) |
| Learning Rate (η) | 0.1 |
| Discount Factor (γ) | 0.9 |
| Reward Weights (α, β, γ) | (1.0, 0.6, 0.4) |
| Simulation Time | 1000 s |
| Traffic Model | CBR, 1 packet/10 s |
| Packet Size | 64 Bytes |
| Mobility Model | Random Waypoint (0.1–0.3 m/s) |
## 📊 Simulation Results (Aqua-Sim / NS-2)
| Metric | RL-RPL-UA vs Baselines |
|--------|-------------------------|
| Packet Delivery Ratio | +9.2% over UWRPL |
| Energy per Packet | −14.8% energy use |
| Network Lifetime | +80 seconds |
| Routing Overhead | 45% lower |
| End-to-End Delay | 10–25% reduction |
## 🧠 Protocol Architecture
🧠 RL-RPL-UA Routing Algorithm
Algorithm: RL-Enhanced RPL Routing for Underwater IoT
1. Initialize Q-table or DQN, Neighbor Table, Default Rank
2. Observe initial state:
s ← [E, LQI, Q, PDR, T]
3. Broadcast DIO with OF_RL(n_i) and node state
4. While node is active:
Receive DIOs from neighbors
For each neighbor n_i:
Extract features: s_n ← [E, LQI, Q, PDR, T]
Compute OF_RL(n_i)
Estimate Q(s, a = n_i)
Select parent:
a* ← argmax Q(s, a = n_i)
Update RPL Rank based on OF_RL(a*)
Forward packets to a*
Wait for ACK or timeout
Observe outcome:
Measure: PDR_t, Delay_t, EnergyCost_t
Compute reward: r_t ← α·PDR − β·Delay − γ·Cost
Observe next state: s′
RL update:
If Q-learning:
Q(s, a) ← Q(s, a) + η [r + γ·max Q(s′, a′) − Q(s, a)]
Else if DQN:
Store (s, a, r, s′) in buffer
Train DQN using minibatch sampling
Update current state: s ← s′
5. Periodically broadcast updated DIO with new Rank and OF_RL
Function observe_state():
Measure E, LQI, Q, PDR, T
Return [E, LQI, Q, PDR, T]
Each node includes:
- Sensing Unit
- RL Agent (Q-learning)
- Extended RPL Stack
- Acoustic MAC (TDMA)
Decision process modeled as an MDP with custom reward:
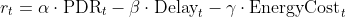
---
## 📁 Repository Contents
- `RL-RPL-UA.tex` – Full LaTeX source of the manuscript
- `figures/` – Static and mobile simulation graphs (PDR, delay, energy, lifetime)
- `aqua-sim-scenarios/` – NS-2 / Aqua-Sim configuration files
- `readme/` – Abstract, key tables, and citation formats
## 📚 How to Cite This Work
### 📌 APA (7th Edition)
Homaei, M., Tarif, M., Di Bartolo, A., & Ávila Vegas, M. (2025). *A Reinforcement Learning-Based Telematic Routing Protocol for the Internet of Underwater Things*. JITEL 2025.
---
### 📌 IEEE
M. Homaei, M. Tarif, A. Di Bartolo, and M. Ávila Vegas, “A Reinforcement Learning-Based Telematic Routing Protocol for the Internet of Underwater Things,” in *Proc. XVII Jornadas de Ingeniería Telemática (JITEL 2025)*, Cáceres, Spain, Nov. 2025.
---
### 📌 BibTeX
```bibtex
@misc{homaei2025rlrplu,
doi = {10.48550/ARXIV.2506.00133},
url = {https://arxiv.org/abs/2506.00133},
author = {Homaei, Mohammadhossein and Tarif, Mehran and Di Bartolo, Agustin and Gutierrez, and Avila, Mar},
keywords = {Networking and Internet Architecture (cs.NI), Artificial Intelligence (cs.AI), Machine Learning (cs.LG), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {A Reinforcement Learning-Based Telematic Routing Protocol for the Internet of Underwater Things},
publisher = {arXiv},
year = {2025},
copyright = {Creative Commons Attribution Share Alike 4.0 International}
}
```
---
```bibtex
@inproceedings{homaei2025rlrplua,
author = {Homaei, Mohammadhossein and Tarif, Mehran and Di Bartolo, Agustin and Ávila Vegas, Mar},
title = {A Reinforcement Learning-Based Telematic Routing Protocol for the Internet of Underwater Things},
booktitle = {Proc. XVII Jornadas de Ingeniería Telemática (JITEL)},
year = {2025},
address = {Cáceres, Spain},
month = {November}
}