https://github.com/hrussellzfac023/yomu-reader
JPDB/Yomitan popup reader with audio, OCR, and subtitle mining
https://github.com/hrussellzfac023/yomu-reader
japanese jpdb ocr subtitles tampermonkey userscript yomitan
Last synced: 2 days ago
JSON representation
JPDB/Yomitan popup reader with audio, OCR, and subtitle mining
- Host: GitHub
- URL: https://github.com/hrussellzfac023/yomu-reader
- Owner: HRussellZFAC023
- License: gpl-3.0
- Created: 2026-05-06T21:22:06.000Z (about 2 months ago)
- Default Branch: main
- Last Pushed: 2026-06-14T11:21:42.000Z (15 days ago)
- Last Synced: 2026-06-14T11:22:16.304Z (15 days ago)
- Topics: japanese, jpdb, ocr, subtitles, tampermonkey, userscript, yomitan
- Language: TypeScript
- Homepage: https://hrussellzfac023.github.io/yomu-reader/
- Size: 70.9 MB
- Stars: 1
- Watchers: 0
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- Changelog: CHANGELOG.md
- License: LICENSE
- Support: docs/support.md
- Agents: AGENTS.md
Awesome Lists containing this project
README

よむ · Yomu
Read Japanese without leaving the page. Understand it, hear it, and save it for study.
よむ is a Japanese popup reader for websites, manga, game text, PDFs, and subtitles.
It runs as a userscript, works on desktop and mobile, and connects to the tools
Japanese learners already use: Yomitan dictionaries, Anki, Jiten, and JPDB.





Install よむ ·
Setup guide ·
Features ·
PC & gaming ·
Video reader ·
Study app ·
Discord
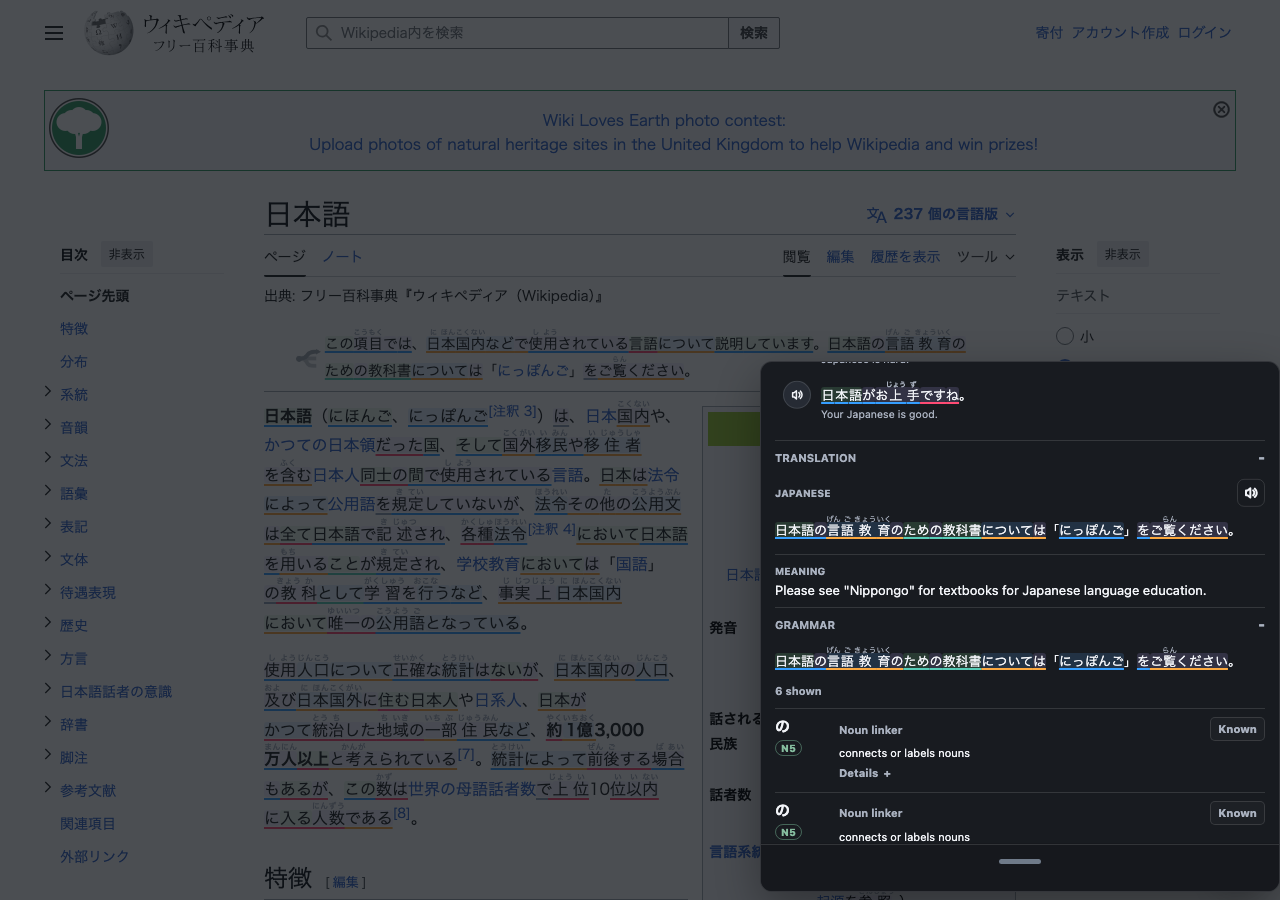
## Why よむ
- **Lookup anywhere:** choose Japanese text on normal pages, OCR results, subtitles, and PDFs.
- **Mine while reading:** create Anki cards, add/review words in Jiten or JPDB, and keep the source sentence/context.
- **Bring your dictionaries:** import Yomitan ZIPs, JMdict, kanji dictionaries, pitch dictionaries, and frequency dictionaries.
- **Read media, not only text:** manga/image OCR, game text handoff, YouTube subtitle mining, a local video reader, and a PDF reader.
- **Mobile-friendly:** works on iPhone/iPad through userscript apps, with touch-first lookup and mobile Anki handoff.
- **Free and open source:** MIT-licensed, no account needed to start.
## Install
The easiest path is the step-by-step guide:
```text
https://yomureader.com/getting-started
```
Already have Tampermonkey or another userscript manager? Install directly:
```text
https://yomureader.com/yomu.user.js
```
Browser-store packages for Chrome, Firefox, and Safari are in preparation. Until then, the userscript is the production install path.
## What It Does
| Workflow | よむ helps with |
| --- | --- |
| Web reading | Popup dictionary lookup, furigana, pitch/accent color, audio, examples, and kanji drilldown |
| Manga and images | OCR overlays that make recognized Japanese lookup-ready without covering the page |
| Games | Steam Deck and PC handoff guide for browser-readable text, copied lines, OCR helpers, and text-hook outputs |
| Video | ASB-style subtitle overlay, transcript lookup, mining, and a hosted local-file video reader |
| PDFs | Browser PDF reader with selectable text, OCR fallback, and the same popup/mining flow |
| Study | AnkiConnect cards, mobile Anki handoff, Jiten/JPDB actions, offline cached reviews, and the hosted study page |
| Dictionaries | Yomitan imports, JMdict, local dictionaries, kanji data, grammar hints, and source ordering |
## Hosted Tools
- [Homepage PWA](https://yomureader.com/) installs as one Yomu shell with offline docs fallback and shortcuts to Study, Video, PDF, and setup.
- [Video reader](https://yomureader.com/video-player/index.html) for local video files and subtitles.
- [PDF reader](https://yomureader.com/pdf-reader/) for Japanese PDFs and scanned pages.
- [Study page](https://yomureader.com/newtab/) for review cards in a browser tab or mobile Home Screen shortcut.
- [PC & gaming guide](https://yomureader.com/guides/read-games-on-steam-deck) for Steam Deck and desktop game text workflows.
- [Feature guide](https://yomureader.com/features) for screenshots and detailed behavior.
## Privacy
よむ keeps imported Yomitan dictionaries and settings in your browser. Anki mining talks to your local AnkiConnect endpoint. Jiten, JPDB, Immersion Kit, Nadeshiko, custom audio, local OCR, and optional kanji data sources are contacted only when their related features are enabled or used.
Game OCR helpers, Decky plugins, clipboard capture, screenshot capture, audio capture, and cloud OCR or translation services are external to よむ unless you explicitly choose them.
For the fuller privacy and setup notes, read the docs at [yomureader.com](https://yomureader.com/).
## Development
```bash
npm install
npm run check
```
Common commands:
```bash
npm run dev # userscript/docs dev harness
npm run dev:vite # plain Vite/new-tab dev server
npm run build # production userscript + hosted assets
npm run verify # userscript metadata and size checks
npm run qa # build + smoke/a11y/complexity checks
```
Greasy Fork's upload budget is 2,000,000 raw bytes for `dist/yomu.user.js`; `npm run verify` enforces the hard limit and warns when the bundle gets tight.
Deployment notes
GitHub Actions cover CI, userscript bundling, docs deployment, extension builds, and release publishing.
- `CI` runs typecheck, tests, build, and userscript metadata verification.
- `Build Userscript` builds `dist/yomu.user.js` and commits it back to `main` when the bundle changes.
- `Deploy Docs` builds the VitePress docs and publishes GitHub Pages.
- `Release` publishes the compiled userscript and browser-extension artifacts when a `v*` tag is pushed or the workflow is run manually.
GreasyFork does not provide a general write API for unattended publishing. After the first logged-in publish, configure GreasyFork to sync updates from:
```text
https://raw.githubusercontent.com/HRussellZFAC023/yomu-reader/main/dist/yomu.user.js
```
Project notes
- Imported dictionaries stay in IndexedDB and do not need to be imported again.
- OCR reads likely images near the viewport, caches results, and makes recognized text lookup-ready without covering the image.
- YouTube subtitle detection uses caption metadata when available and visible DOM captions as a fallback.
- Local `.srt`, `.vtt`, `.ass`, and `.ssa` subtitle files can be loaded manually.
- On iPhone/iPad, desktop helpers such as AnkiConnect, self-hosted audio, and local OCR servers must be reachable over the network.
- Support links, Factory Reset, API keys, imports, and appearance settings live in the settings panel.
## Support
- Documentation: https://yomureader.com/
- Issues: https://github.com/HRussellZFAC023/yomu-reader/issues
- Discord: https://discord.gg/jD6NPURewD
- Donate: https://paypal.me/HenryRussell163
If よむ helps you read more Japanese, a star makes it easier for other learners to find.

Credits and source licenses
よむ is its own userscript, but several open projects shaped the design and edge-case coverage:
- [anki-jpdb.reader](https://github.com/Kagu-chan/anki-jpdb.reader) for JPDB reader inspiration, parser edge cases, mining flow, and ASB-style integration ideas.
- [Yomitan](https://github.com/yomidevs/yomitan) for dictionary import formats, structured glossary handling, audio-source conventions, and scanning UX references.
- [JPDB Custom Dictionary Mod](https://gitlab.com/nakura/jpdb_cdm) for JPDB/Yomitan dictionary-on-JPDB UX reference only, with no code copied.
- [JMdict for Yomitan](https://github.com/yomidevs/jmdict-yomitan) and EDRDG/JMdict for the recommended dictionary package.
- [Kanjium](https://github.com/mifunetoshiro/kanjium) for documented pitch-accent source data and licensing research around local pitch dictionaries.
- [Kuuuube's Yomitan dictionaries](https://github.com/Kuuuube/yomitan-dictionaries) for the recommended JPDBv2㋕ local frequency package.
- [asbplayer](https://github.com/asbplayer/asbplayer) for subtitle mining concepts and video-reader interaction patterns.
- [YomiNinja](https://github.com/matt-m-o/YomiNinja), [Decky Translator](https://github.com/cat-in-a-box/Decky-Translator), [GameSentenceMiner](https://github.com/bpwhelan/GameSentenceMiner), [Kamite](https://github.com/fauu/Kamite), [Translumo](https://github.com/ramjke/Translumo), [Game2Text](https://github.com/mathewthe2/Game2Text), [Tango Lens](https://tango.acorntalk.com/help), and [Kamui](https://kamui.gg/) for game OCR, capture, overlay, and mining workflow references.
- [KanjiVG](https://github.com/KanjiVG/kanjivg), [Kanji Canvas](https://github.com/asdfjkl/kanjicanvas), [Kanji Alive](https://github.com/kanjialive/kanji-data-media), [The Kanji Map](https://thekanjimap.com/), and [Uchisen](https://uchisen.com/) for kanji data, presentation, and study references.
- [NihongoTube](https://www.nihongotube.app/) for the Japanese-only YouTube immersion idea as reference only.
- [JPDB RTK Information Inserter](https://greasyfork.org/en/scripts/546314-jpdb-rtk-information-inserter), [JPDB Immersion Kit Examples](https://github.com/AwooDesu/JPDB-Immersion-Kit-Examples), and [JPDB Nadeshiko Examples](https://greasyfork.org/en/scripts/529745-jpdb-nadeshiko-examples) for optional JPDB-side behavior references.
- [Yomikiri](https://github.com/BlueGreenMagick/yomikiri), [Tofugu grammar guides](https://www.tofugu.com/japanese-grammar/), Ultimate Yomitan Audio, and local audio server references for workflow inspiration.
- [Immersion Kit](https://www.immersionkit.com/), [Nadeshiko](https://nadeshiko.co/), [AnkiConnect](https://foosoft.net/projects/anki-connect/), [Jiten](https://jiten.moe/), and [JPDB](https://jpdb.io) for external services users can connect to.
| Source | License / terms used by よむ |
| --- | --- |
| [よむ source code](https://github.com/HRussellZFAC023/yomu-reader) | MIT |
| [KanjiVG](https://github.com/KanjiVG/kanjivg) | Creative Commons Attribution-ShareAlike 3.0 |
| [Kanji Canvas](https://github.com/asdfjkl/kanjicanvas) | MIT; stroke normalization and distance matching approach adapted with attribution |
| [JMdict / JMdict for Yomitan](https://github.com/yomidevs/jmdict-yomitan) | JMdict data is EDRDG CC BY-SA 4.0; yomidevs packaging code is MIT |
| [Kanjium](https://github.com/mifunetoshiro/kanjium) | Creative Commons Attribution-ShareAlike 4.0; used as source/license reference for pitch-accent recommendations, not bundled |
| [JPDBv2 frequency dictionaries](https://github.com/Kuuuube/yomitan-dictionaries) | External Yomitan frequency packages; optional local import, not bundled |
| [Kanji Alive data/media](https://github.com/kanjialive/kanji-data-media) | Creative Commons Attribution 4.0, with project-documented exceptions |
| [The Kanji Map](https://github.com/gabor-kovacs/the-kanji-map) | MIT for the app; underlying data/media keep their upstream terms |
| [Yomitan](https://github.com/yomidevs/yomitan), [fflate](https://github.com/101arrowz/fflate), [asbplayer](https://github.com/asbplayer/asbplayer), [anki-jpdb.reader](https://github.com/Kagu-chan/anki-jpdb.reader), [JPDB Immersion Kit Examples](https://github.com/AwooDesu/JPDB-Immersion-Kit-Examples), [JPDB Nadeshiko Examples](https://greasyfork.org/en/scripts/529745-jpdb-nadeshiko-examples) | Upstream terms apply; used as compatible formats, libraries, or behavior references |
| [YomiNinja](https://github.com/matt-m-o/YomiNinja), [Decky Translator](https://github.com/cat-in-a-box/Decky-Translator), and [GameSentenceMiner](https://github.com/bpwhelan/GameSentenceMiner) | GPL-3.0 projects used as workflow references only; よむ does not bundle their code |
| [Kamite](https://github.com/fauu/Kamite) | AGPL-3.0 project used as a workflow reference only; よむ does not bundle its code |
| [Translumo](https://github.com/ramjke/Translumo) and [Game2Text](https://github.com/mathewthe2/Game2Text) | Apache-2.0 projects used as workflow references only; よむ does not bundle their code |
| [Tango Lens](https://tango.acorntalk.com/help), [Kamui](https://kamui.gg/), [AnkiConnect](https://foosoft.net/projects/anki-connect/), [NihongoTube](https://www.nihongotube.app/), [Immersion Kit](https://www.immersionkit.com/), [Nadeshiko](https://nadeshiko.co/), and optional local OCR/audio services | External/runtime services or references; よむ does not bundle their corpora or service code |