https://github.com/huggingface/smollm
Everything about the SmolLM and SmolVLM family of models
https://github.com/huggingface/smollm
Last synced: 10 months ago
JSON representation
Everything about the SmolLM and SmolVLM family of models
- Host: GitHub
- URL: https://github.com/huggingface/smollm
- Owner: huggingface
- License: apache-2.0
- Created: 2024-11-04T13:01:54.000Z (over 1 year ago)
- Default Branch: main
- Last Pushed: 2025-07-11T10:49:47.000Z (about 1 year ago)
- Last Synced: 2025-07-18T07:45:31.845Z (about 1 year ago)
- Language: Python
- Homepage: https://huggingface.co/HuggingFaceTB
- Size: 1.71 MB
- Stars: 2,910
- Watchers: 24
- Forks: 187
- Open Issues: 35
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
- awesome-mobile-ai - HuggingFaceTB/SmolLM - 1.7B | Ultra-compact for edge devices | (🧠 SOTA 2024-2025: Mobile LLMs & Multimodal / 🤖 On-Device Large Language Models)
- StarryDivineSky - huggingface/smollm - 1.7B-Instruct,支持多种使用方式,包括 `transformers`、`trl` 和 `llama.cpp` 等工具。此外,新推出的 SmolVLM 是基于 SmolLM2 的视觉语言模型。 (A01_文本生成_文本对话 / 大语言对话模型及数据)
- awesome-vision-language-pretraining - [github
- awesome-latest-LLM - SmolLM (Huggingface) - 6723884218bcda64b34d7db9)| 135M~1.7B| apache-2.0 | | (Small language models (SLM))
- awesome-ai-native - SmolLM - Hugging Face's fully open family of small text and vision models, with training data and code released for on-device use. (Models & robotics / Small language models)
- awesome-open-source-lms - SmolLM repo
- awesome-mobile-llm - code - 6723884218bcda64b34d7db9) | (Mobile-First LLMs)
README
# Smol Models 🤏
Welcome to Smol Models, a family of efficient and lightweight AI models from Hugging Face. Our mission is to create fully open powerful yet compact models, for text and vision, that can run effectively on-device while maintaining strong performance.
## [NEW] SmolLM3 (Language Model)

Our 3B model outperforms Llama 3.2 3B and Qwen2.5 3B while staying competitive with larger 4B alternatives (Qwen3 & Gemma3). Beyond the performance numbers, we're sharing exactly how we built it using public datasets and training frameworks.
Ressources:
- [SmolLM3-Base](https://hf.co/HuggingFaceTB/SmolLM3-3B-Base)
- [SmolLM3](https://hf.co/HuggingFaceTB/SmolLM3-3B)
- [blog](https://hf.co/blog/smollm3)
Summary:
- **3B model** trained on 11T tokens, SoTA at the 3B scale and competitive with 4B models
- **Fully open model**, open weights + full training details including public data mixture and training configs
- **Instruct model** with **dual mode reasoning,** supporting think/no_think modes
- **Multilingual support** for 6 languages: English, French, Spanish, German, Italian, and Portuguese
- **Long context** up to 128k with NoPE and using YaRN

## 👁️ SmolVLM (Vision Language Model)
[SmolVLM](https://huggingface.co/HuggingFaceTB/SmolVLM-Instruct) is our compact multimodal model that can:
- Process both images and text and perform tasks like visual QA, image description, and visual storytelling
- Handle multiple images in a single conversation
- Run efficiently on-device
## Repository Structure
```
smollm/
├── text/ # SmolLM3/2/1 related code and resources
├── vision/ # SmolVLM related code and resources
└── tools/ # Shared utilities and inference tools
├── smol_tools/ # Lightweight AI-powered tools
├── smollm_local_inference/
└── smolvlm_local_inference/
```
## Getting Started
### SmolLM3
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "HuggingFaceTB/SmolLM3-3B"
device = "cuda" # for GPU usage or "cpu" for CPU usage
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
).to(device)
# prepare the model input
prompt = "Give me a brief explanation of gravity in simple terms."
messages_think = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages_think,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# Generate the output
generated_ids = model.generate(**model_inputs, max_new_tokens=32768)
# Get and decode the output
output_ids = generated_ids[0][len(model_inputs.input_ids[0]) :]
print(tokenizer.decode(output_ids, skip_special_tokens=True))
```
### SmolVLM
```python
from transformers import AutoProcessor, AutoModelForVision2Seq
processor = AutoProcessor.from_pretrained("HuggingFaceTB/SmolVLM-Instruct")
model = AutoModelForVision2Seq.from_pretrained("HuggingFaceTB/SmolVLM-Instruct")
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": "What's in this image?"}
]
}
]
```
## Ecosystem
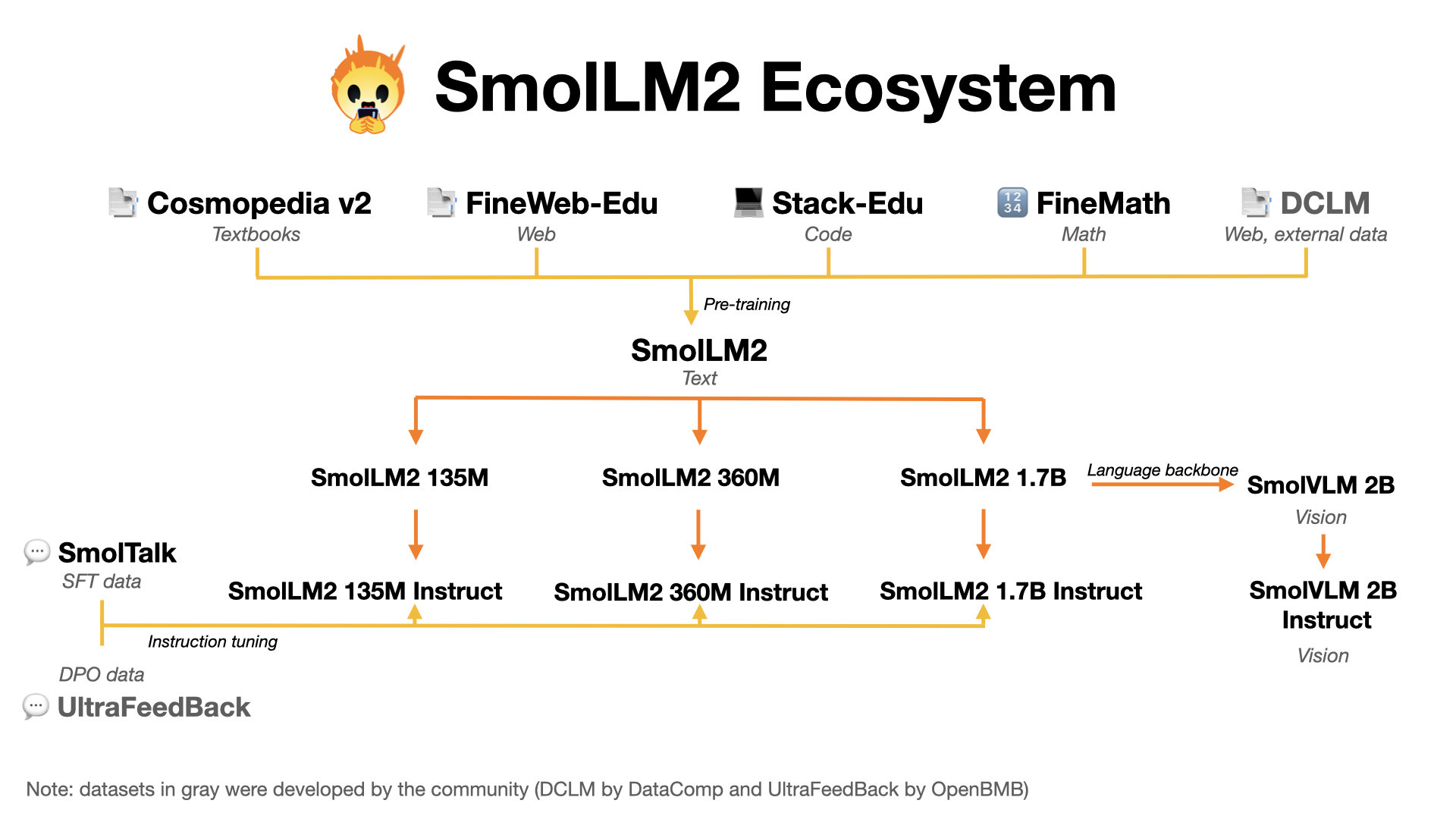
## Resources
### Documentation
- [SmolLM3 Documentation](text/README.md)
- [SmolLM2 paper](https://arxiv.org/abs/2502.02737v1)
- [SmolVLM Documentation](vision/README.md)
- [Local Inference Guide](tools/README.md)
### Pretrained Models
- [SmolLM3 Models Collection](https://huggingface.co/collections/HuggingFaceTB/smollm3-686d33c1fdffe8e635317e23)
- [SmolLM2 Models Collection](https://huggingface.co/collections/HuggingFaceTB/smollm2-6723884218bcda64b34d7db9)
- [SmolVLM Model](https://huggingface.co/HuggingFaceTB/SmolVLM-Instruct)
### Datasets
- [SmolLM3 Pretraining dataset](https://huggingface.co/collections/HuggingFaceTB/smollm3-pretraining-datasets-685a7353fdc01aecde51b1d9)
- [SmolTalk](https://huggingface.co/datasets/HuggingFaceTB/smoltalk) - Our instruction-tuning dataset
- [FineMath](https://huggingface.co/datasets/HuggingFaceTB/finemath) - Mathematics pretraining dataset
- [FineWeb-Edu](https://huggingface.co/datasets/HuggingFaceFW/fineweb-edu) - Educational content pretraining dataset