https://github.com/hyzhak/mle
Machine Learning: Maximum Likelihood Estimation (MLE)
https://github.com/hyzhak/mle
machine-learning map maximum-a-posteriori-estimation maximum-likelihood-estimation mle
Last synced: about 1 year ago
JSON representation
Machine Learning: Maximum Likelihood Estimation (MLE)
- Host: GitHub
- URL: https://github.com/hyzhak/mle
- Owner: hyzhak
- License: mit
- Created: 2017-05-18T11:20:44.000Z (about 9 years ago)
- Default Branch: master
- Last Pushed: 2017-06-20T10:57:44.000Z (about 9 years ago)
- Last Synced: 2025-02-15T05:27:27.024Z (over 1 year ago)
- Topics: machine-learning, map, maximum-a-posteriori-estimation, maximum-likelihood-estimation, mle
- Language: Jupyter Notebook
- Size: 655 KB
- Stars: 1
- Watchers: 3
- Forks: 3
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# MLE and MAP
Machine Learning: Maximum Likelihood Estimation (MLE) and Maximum a Posteri (MAP) Estimation
## Subtleties
ML doesn't work good with sparse data because `P(X | Y)` might be zero.
(for example, Xi = birthdate, Xi = Jan_25_1992)
```
P(Y=1 | X1...Xn) = (P(Y=1) * Mult P(Xi | Y=1) for i) / P (X1...Xn)
```
We can solve it by using prior with MAP estimation.
# MLE
## Pros
- invariant under reparameterization. So we can wrap

in any function.
# MAP
## Pros
- avoid overfitting (regularization / shrinkage)
- tends to look like MLE asymptotically
## Cons
- point estimation (no representation of uncertainty in θ).
Because it could choose spike of θ because it has higher probability
- not invariant under reparameterization
- must assume prior on θ
## Examples
### Univariate Gaussian mean

in other words it is sample mean plus prior mean.
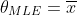
so when n->0 we get

but when n->∞ we get

- [MLE symbolic example](https://github.com/hyzhak/mle/blob/master/mle.ipynb)
- [MLE statsmodel example](https://github.com/hyzhak/mle/blob/master/mle-statsmodel.ipynb)
## Related Topics
- The Cramer-Rao Lower Bound
- [Central Limit Theorem](https://en.wikipedia.org/wiki/Central_limit_theorem)
sum independent random variables are tend toward a normal distribution
- [Likelihood Ratio Test](https://en.wikipedia.org/wiki/Likelihood-ratio_test) (compare zero hypothesis with ml value)
- [Wald Test](https://en.wikipedia.org/wiki/Wald_test)
- etc
## Videos
### Jeff Miller (mathematicalmonk)
- [(ML 6.1) Maximum a posteriori (MAP) estimation](https://www.youtube.com/watch?v=kkhdIriddSI)
- [(ML 6.2) MAP for univariate Gaussian mean](https://www.youtube.com/watch?v=KogqeZ_88-g)
- [(ML 6.3) Interpretation of MAP as convex combination](https://www.youtube.com/watch?v=SFQK57G5VF8)