https://github.com/i4ds/dtw-sentence-alignment
A simple, low-dependency package for aligning sentences by minimizing a chosen metric.
https://github.com/i4ds/dtw-sentence-alignment
dtw dtw-algorithm dynamic-time-warping sentence-alignment sentence-similarity
Last synced: 5 months ago
JSON representation
A simple, low-dependency package for aligning sentences by minimizing a chosen metric.
- Host: GitHub
- URL: https://github.com/i4ds/dtw-sentence-alignment
- Owner: i4Ds
- License: mit
- Created: 2024-09-16T09:47:49.000Z (over 1 year ago)
- Default Branch: main
- Last Pushed: 2024-09-17T11:07:12.000Z (over 1 year ago)
- Last Synced: 2025-04-12T07:17:23.042Z (about 1 year ago)
- Topics: dtw, dtw-algorithm, dynamic-time-warping, sentence-alignment, sentence-similarity
- Language: Python
- Homepage:
- Size: 316 KB
- Stars: 1
- Watchers: 3
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# DTW-Sentence-Alignment
A simple, low-dependency package for aligning sentences by minimizing a chosen metric.
## Motivation
I needed to match sentences between two lists and was disappointed to find that there wasn't a simple package available for this task without excessive dependencies or unintuitive interfaces.
## Overview
DTW-Sentence-Alignment is a Python package for aligning sentences using Dynamic Time Warping (DTW). It supports custom similarity functions and predefined metrics, maximizing alignment scores. Unlike traditional implementations, it allows flexible starting and ending points for alignment.
## Installation
To install the package, you can use pip:
```bash
pip install dtwsa
```
## Usage
Here's a basic example of how to use the package:
```python
from dtwsa import SentenceAligner
from dtwsa.metrics import WER_similarity
# Align sentences
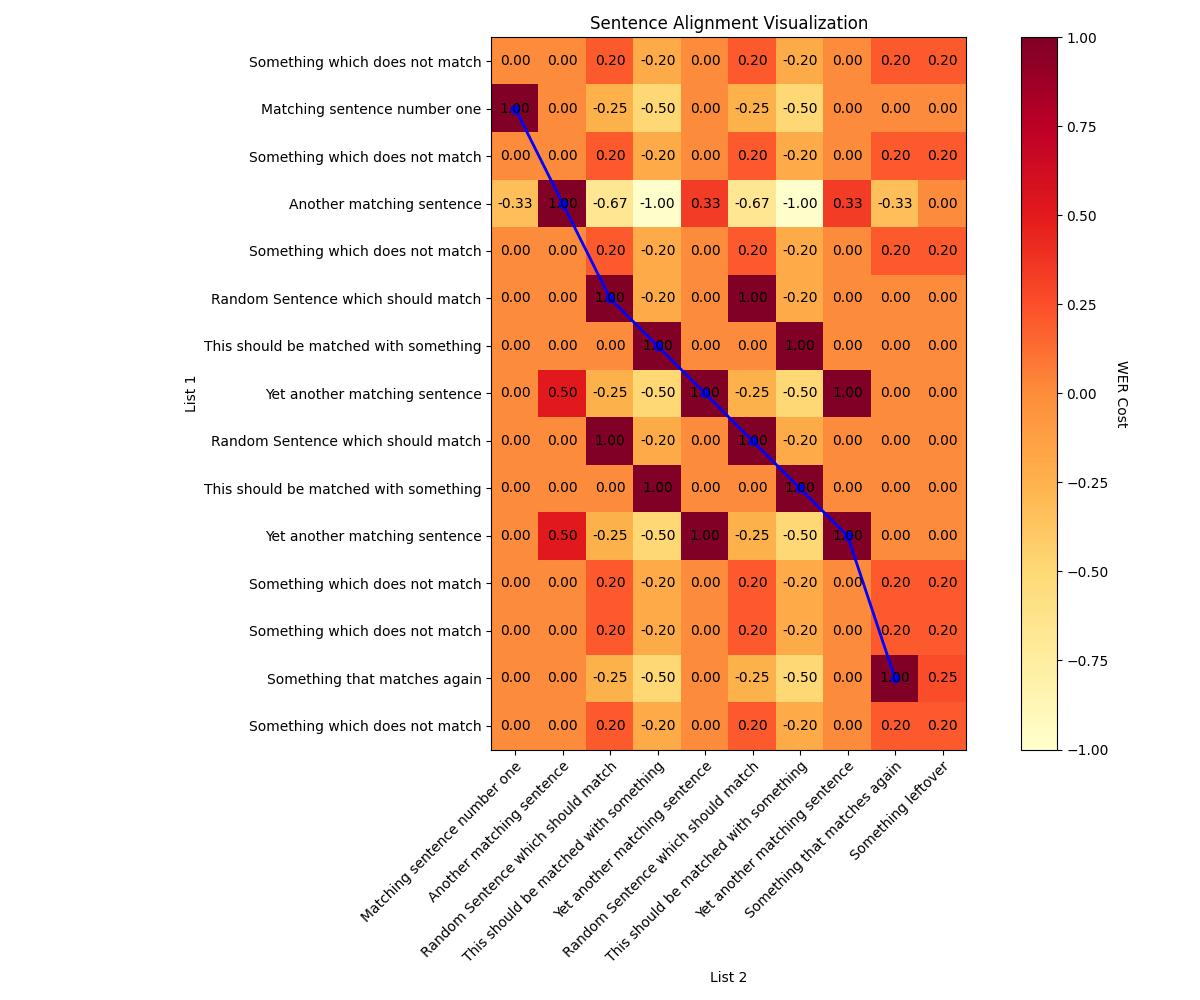
list_1 = [
"Something which does not match",
"Matching sentence number one",
"Something which does not match",
"Another matching sentence",
"Something which does not match",
"Random Sentence which should match",
"This should be matched with something",
"Yet another matching sentence",
"Random Sentence which should match",
"This should be matched with something",
"Yet another matching sentence",
"Something which does not match",
"Something which does not match",
"Something that matches again",
"Something which does not match",
]
list_2 = [
"Matching sentence number one",
"Another matching sentence",
"Random Sentence which should match",
"This should be matched with something",
"Yet another matching sentence",
"Random Sentence which should match",
"This should be matched with something",
"Yet another matching sentence",
"Something that matches again",
"Something leftover",
]
# Create a SentenceAligner object with the WER_similarity metric and 0.7 as the minimum matching value
# The minimum matching value is useful to avoid matching sentences that are not similar enough.
# Better to not match anything than to match something that is not similar enough.
aligner = SentenceAligner(WER_similarity, min_matching_value=0.7)
# Align the sentences and get the alignment and score
alignment, score = aligner.align_sentences(list_1, list_2)
print(f"Alignment: {alignment}") # [(0, 0), (1, 1), (3, 2), (5, 3), (6, 4), (7, 5), (8, 6), (9, 7), (10, 8), (13, 9)]
print(f"Score: {score}") # 10.0
# Plot the alignment
aligner.visualize_alignment(list_1, list_2)
```
## Features
- Flexible sentence alignment using custom similarity functions
- Predefined metrics like Word Error Rate (WER) similarity
- Simple API for easy integration
## TODO
1. Improve efficiency of the alignment algorithm by limiting the choices of the alignment by limiting the maximum distance of indexes between matches.
2. Improve efficiency of the alignment algorithm by implementing a version of PrunedDTW.
3. Improve efficiency of the alignment algorithm by parallelization.
2. Add new metrics for sentence comparison (e.g., BLEU score, cosine similarity)