https://github.com/idiap/llm-asr-prompt
Reducing Prompt Sensitivity in LLM-based Speech Recognition Through Learnable Projection
https://github.com/idiap/llm-asr-prompt
Last synced: 18 days ago
JSON representation
Reducing Prompt Sensitivity in LLM-based Speech Recognition Through Learnable Projection
- Host: GitHub
- URL: https://github.com/idiap/llm-asr-prompt
- Owner: idiap
- Created: 2025-10-29T07:40:12.000Z (8 months ago)
- Default Branch: main
- Last Pushed: 2026-05-06T07:49:38.000Z (about 1 month ago)
- Last Synced: 2026-05-06T09:40:50.920Z (about 1 month ago)
- Language: Python
- Homepage:
- Size: 1.64 MB
- Stars: 6
- Watchers: 0
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSES/APACHE-2.0.txt
Awesome Lists containing this project
README
# Reducing Prompt Sensitivity in LLM-based Speech Recognition Through Learnable Projection



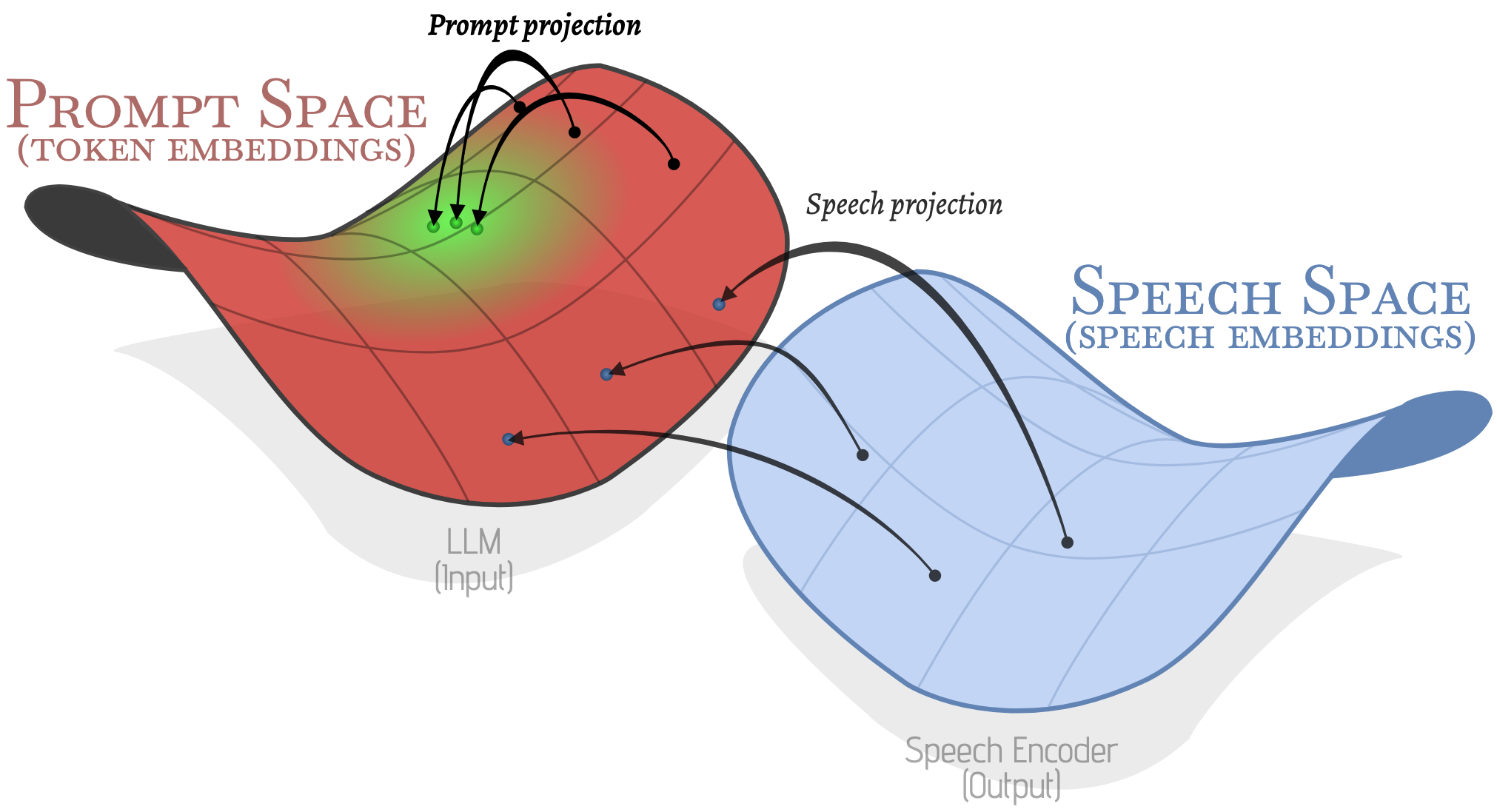
In a typical LLM-based ASR system, speech is passed through a speech encoder and converted into a sequence of embeddings, which are then projected, via a speech projector, onto the LLM input embedding space.
Similarly, we propose learning a new projection able to project the original prompt embeddings onto higher-performing regions of the LLM input embedding space (green zone above).
## 📘 More About This Work
> [!IMPORTANT]
> This repository contains the code for our paper on **Prompt Projector for LLM-based ASR**, accepted at **ICASSP 2026**. Our work builds upon the [SLAM-LLM](https://github.com/X-LANCE/SLAM-LLM) framework, specifically extending the [ASR example](https://github.com/X-LANCE/SLAM-LLM/tree/main/examples/asr_librispeech) and is **based on a cloned version of the original repo**.
>
> **Quick Links:** [ArXiv Paper](https://arxiv.org/pdf/2601.20898) · [Extended Results](appendix.pdf) · [Scripts](scripts/README.md) · [Installation](#-installation) · [License](#-license)
### 🧪 Abstract
> LLM-based automatic speech recognition (ASR), a well-established approach, connects speech foundation models to large language models (LLMs) through a speech-to-LLM projector, yielding promising results. A common design choice in these architectures is the use of a fixed, manually defined prompt during both training and inference. This setup not only enables applicability across a range of practical scenarios, but also helps maximize model performance.
> However, the impact of prompt design remains underexplored.
> This paper presents a comprehensive analysis of commonly used prompts across diverse datasets, showing that prompt choice significantly affects ASR performance and introduces instability, with no single prompt performing best across all cases. Inspired by the speech-to-LLM projector, we propose a **prompt projector module**, a simple, model-agnostic extension that learns to project prompt embeddings to more effective regions of the LLM input space, without modifying the underlying LLM-based ASR model.
> Experiments on four datasets show that the addition of a prompt projector consistently improves performance, reduces variability, and outperforms the best manually selected prompts.
### 📊 Extended Results & Appendix
> [!IMPORTANT]
> Complementary experimental results referenced in the paper are consolidated in [`appendix.pdf`](appendix.pdf).
> The appendix includes: a comparison of Vicuna-7B vs. LLaMA3-8B performance in the LLM-based ASR setup, an analysis of the impact of k (the number of learnable embeddings) in prompt tuning experiments, and a series of experiments supporting the importance of freezing or not freezing the underlying model while training the Prompt Projector module.
## 🛠️ Implementation
Our **prompt projector** is implemented as a PEFT (Parameter-Efficient Fine-Tuning) mechanism by modifying the original HuggingFace PEFT library. We cloned and extended the [PEFT repository](https://github.com/huggingface/peft) to support the prompt projector as a new PEFT method. The `peft/` directory in this repository contains our modified version with the prompt projector implementation.
## 🔧 Modifications to Original Code
### 🌀 Changes to SLAM-LLM
We extended the original SLAM-LLM codebase with the following enhancements:
#### 🧩 Enhanced Prompt Configuration (YAML files in `conf/`)
- **Flexible `` token placement**: Unlike the original implementation where speech was always prepended to the prompt, our version allows the `` token to be placed anywhere in the prompt template.
- **Learnable token insertion with ``**: Insert N learnable tokens at any position in the prompt using the `` syntax (e.g., `` inserts 5 learnable tokens).
- **Text-initialized learnable tokens with ``**: Initialize learnable tokens with user-provided text using the `` syntax (e.g., ``).
#### ⚙️ New Training Configuration Options
Added the following settings to `train_config`:
- `save_checkpoint_only_at_epoch_end` (bool): Save checkpoints only at the end of each epoch instead of at every checkpoint interval.
- `freeze_projector` (bool): Freeze the projector module during training.
- `use_bf16` (bool): Enable bfloat16 training format.
- `peft_config.peft_method`: Added support for `"p-projector"` as valid PEFT method.
- `prompt_token` (str): Token used to mark learnable positions in prompts (default: `"
"`).
- `prompt_num_virtual_tokens` (int): Number of virtual tokens for "prefix" method.
### 📦 Changes to PEFT Library
We modified the original HuggingFace PEFT library to add:
- **P_PROJECTOR**: A new PEFT type that implements our prompt projector mechanism.
- **User-provided embedding initialization**: Support for initializing prompt embeddings with custom embeddings via the `virtual_token_embs` parameter in `PromptEncoder`.
## 🚀 Installation
### 🧱 Environment Setup
We provide a conda environment file for easy setup. To create and activate the environment:
```bash
conda env create -f environment.yml
conda activate slam_llm
```
> [!TIP]
> For additional installation details, troubleshooting, or alternative setup methods, please refer to the [original SLAM-LLM repository](https://github.com/X-LANCE/SLAM-LLM/).
## ▶️ Running Experiments
To reproduce the experiments from our paper:
1. First, read the two subsections below to understand the input data format and where to download the required model binaries.
2. Then, refer to the **[`scripts/`](scripts/) folder**, which contains all necessary training and evaluation scripts along with a detailed README explaining the complete workflow.
### 📁 Data preparation
You need to prepare the data jsonl in this format.
```
{"key": "1001-134707-0000_ASR", "source": "/data/open_data/librispeech_audio/audio/librispeech_1001-134707-0000.wav", "target": "1 little recks the laborer. How near his work is holding him to God, The loving laborer through space and time, after all, not to create, only or found only."}
...
{"key": "1001-134707-0000_ASR", "source": "/data/open_data/librispeech_audio/audio/librispeech_1001-134707-0000.wav", "target": "1 little recks the laborer. How near his work is holding him to God, The loving laborer through space and time, after all, not to create, only or found only."}
```
### Speech encoder and LLM model binaries
- Speech encoder: [WavLM-large](https://drive.google.com/file/d/12-cB34qCTvByWT-QtOcZaqwwO21FLSqU/view)
- LLM: [vicuna-7b-v1.5](https://huggingface.co/lmsys/vicuna-7b-v1.5)
For more details on the base SLAM-LLM framework, please refer to the [README.md of the original repo](https://github.com/X-LANCE/SLAM-LLM/tree/main/examples/asr_librispeech).
## 📚 Citation
If you find our work useful, please consider citing it:
```bibtex
@INPROCEEDINGS{11464534,
title={Reducing Prompt Sensitivity in LLM-Based Speech Recognition Through Learnable Projection},
author={Burdisso, Sergio and Villatoro-Tello, Esaú and Kumar, Shashi and Madikeri, Srikanth and Carofilis, Andrés and Rangappa, Pradeep and E, Manjunath K and Hacioglu, Kadri and Motlicek, Petr and Stolcke, Andreas},
booktitle={ICASSP 2026 - 2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
year={2026},
volume={},
number={},
pages={16372-16376},
doi={10.1109/ICASSP55912.2026.11464534}}
```
## 📄 License
Our original code additions and modifications (including the prompt projector mechanism, enhanced prompt handling, new training configuration options, and PEFT extensions) are licensed under the MIT License. Portions of this repository remain under their original upstream licenses:
- SLAM-LLM original code: MIT License
- HuggingFace components and PEFT upstream code: Apache License 2.0
- Certain integrated logic referencing Llama materials (e.g., adaptation utilities) is subject to the Llama 2 Community License
Please consult individual file headers and the `LICENSES/` directory for the full text of each applicable license:
- `LICENSES/MIT.txt`
- `LICENSES/APACHE-2.0.txt`
- `LICENSES/LLAMA2.txt`
Files we modified have a header block that explicitly lists the changes; only those listed modifications are under our MIT license. Everything else in those files keeps its original upstream license. Check each file header and the `LICENSES/` directory for exact licensing.