https://github.com/ilius/pyglossary
A tool for converting dictionary files aka glossaries. Mainly to help use our offline glossaries in any Open Source dictionary we like on any modern operating system / device.
https://github.com/ilius/pyglossary
dictionary dictionary-conversion dictionary-tools glossaries gtk linux pygi python stardict tkinter
Last synced: about 1 year ago
JSON representation
A tool for converting dictionary files aka glossaries. Mainly to help use our offline glossaries in any Open Source dictionary we like on any modern operating system / device.
- Host: GitHub
- URL: https://github.com/ilius/pyglossary
- Owner: ilius
- License: gpl-3.0
- Created: 2011-01-23T10:24:30.000Z (over 15 years ago)
- Default Branch: master
- Last Pushed: 2025-04-22T12:08:06.000Z (about 1 year ago)
- Last Synced: 2025-04-23T23:17:08.101Z (about 1 year ago)
- Topics: dictionary, dictionary-conversion, dictionary-tools, glossaries, gtk, linux, pygi, python, stardict, tkinter
- Language: Python
- Homepage:
- Size: 11.4 MB
- Stars: 2,365
- Watchers: 61
- Forks: 243
- Open Issues: 6
-
Metadata Files:
- Readme: README.md
- License: LICENSE
- Code of conduct: CODE_OF_CONDUCT.md
- Authors: AUTHORS
Awesome Lists containing this project
- awesome-immersion - pyglossary
- awesome-language-learning - pyglossary - Amazing library for the creation and conversion of dictionaries in a huge amount of formats. (Developer Resources / Dictionary Data)
README
# PyGlossary

[](https://pypi.org/project/pyglossary/)
[](https://pypi.org/project/pyglossary/)
[](https://github.com/ilius/pyglossary/actions/workflows/test.yml?query=branch%3Amaster)
A tool for converting dictionary files aka glossaries.
The primary purpose is to be able to use our offline glossaries in any Open
Source dictionary we like on any OS/device.
There are countless formats, and my time is limited, so I implement formats that
seem more useful for myself, or for Open Source community. Also diversity of
languages is taken into account. Pull requests are welcome.
## Screenshots
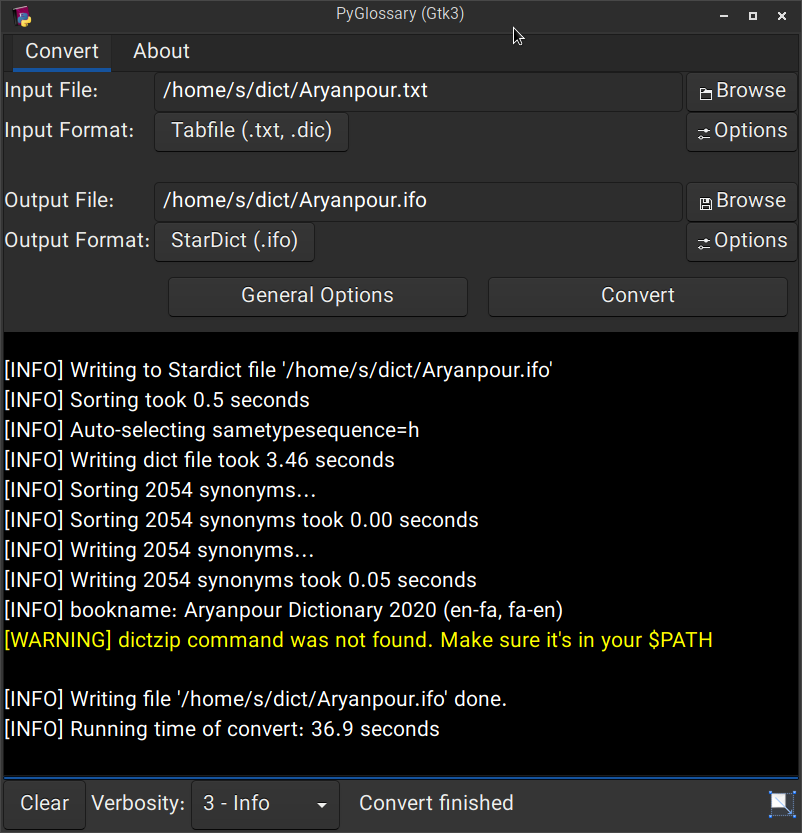
Linux - Gtk3-based interface
______________________________________________________________________
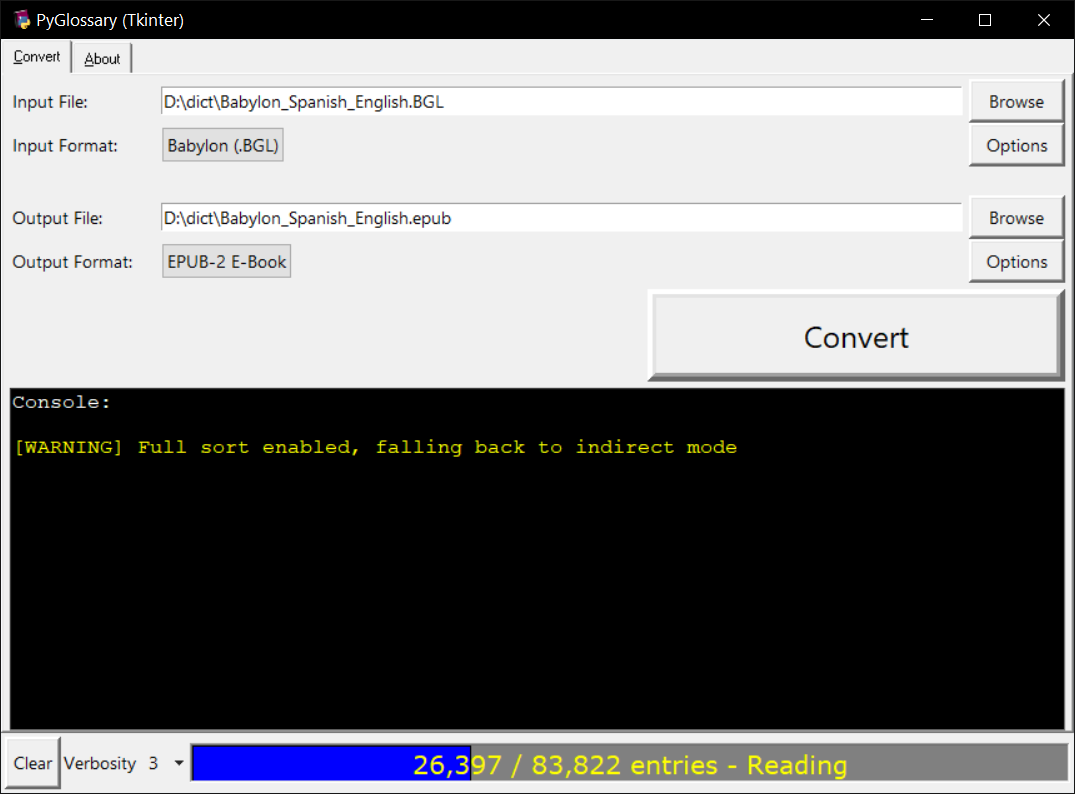
Windows - Tkinter-based interface
______________________________________________________________________
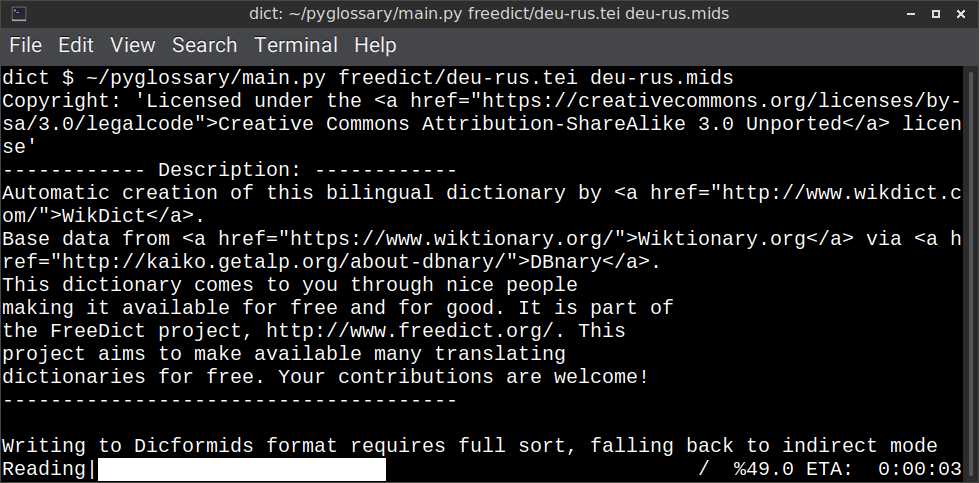
Linux - command-line interface
______________________________________________________________________
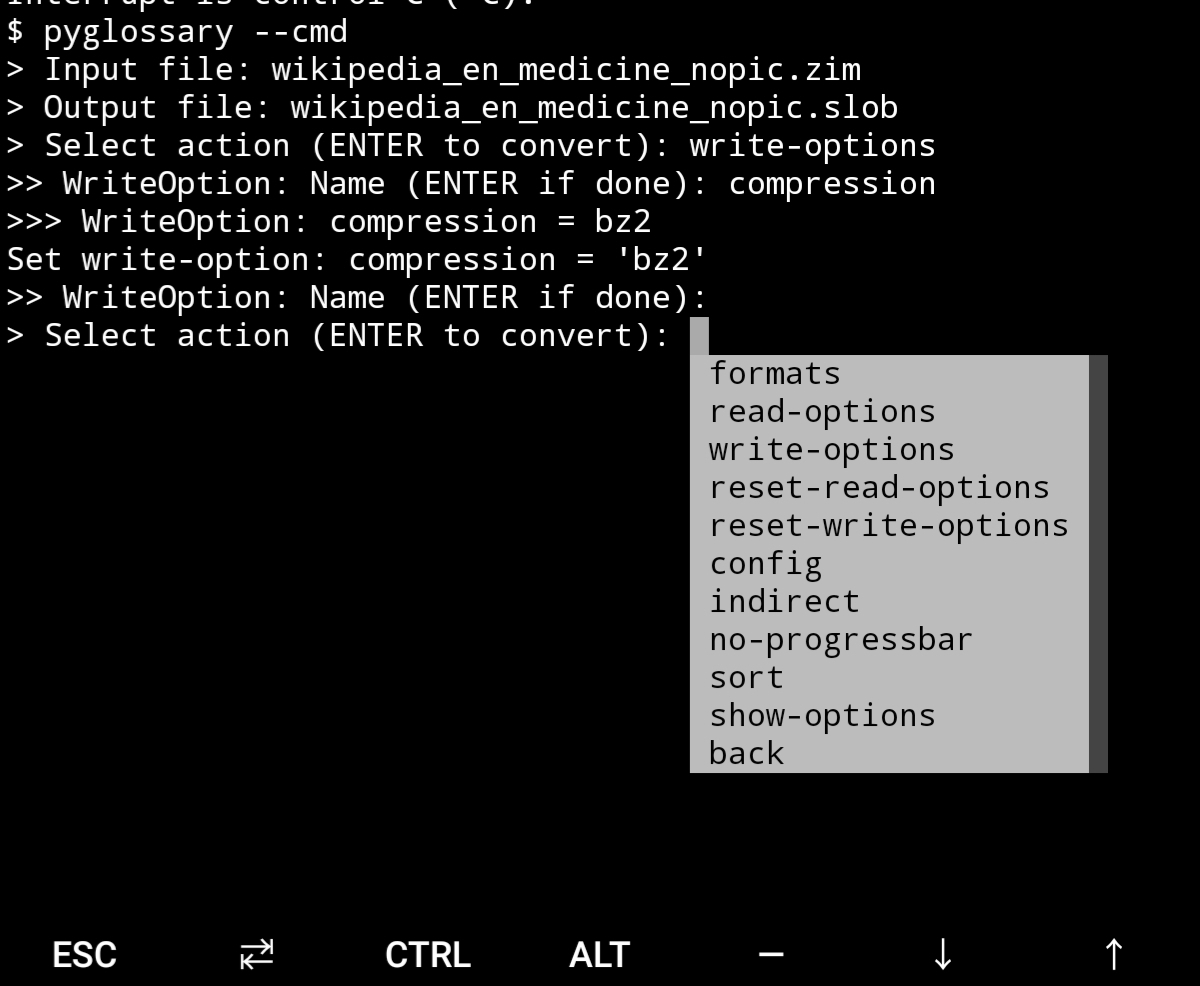
Android Termux - interactive command-line interface
______________________________________________________________________
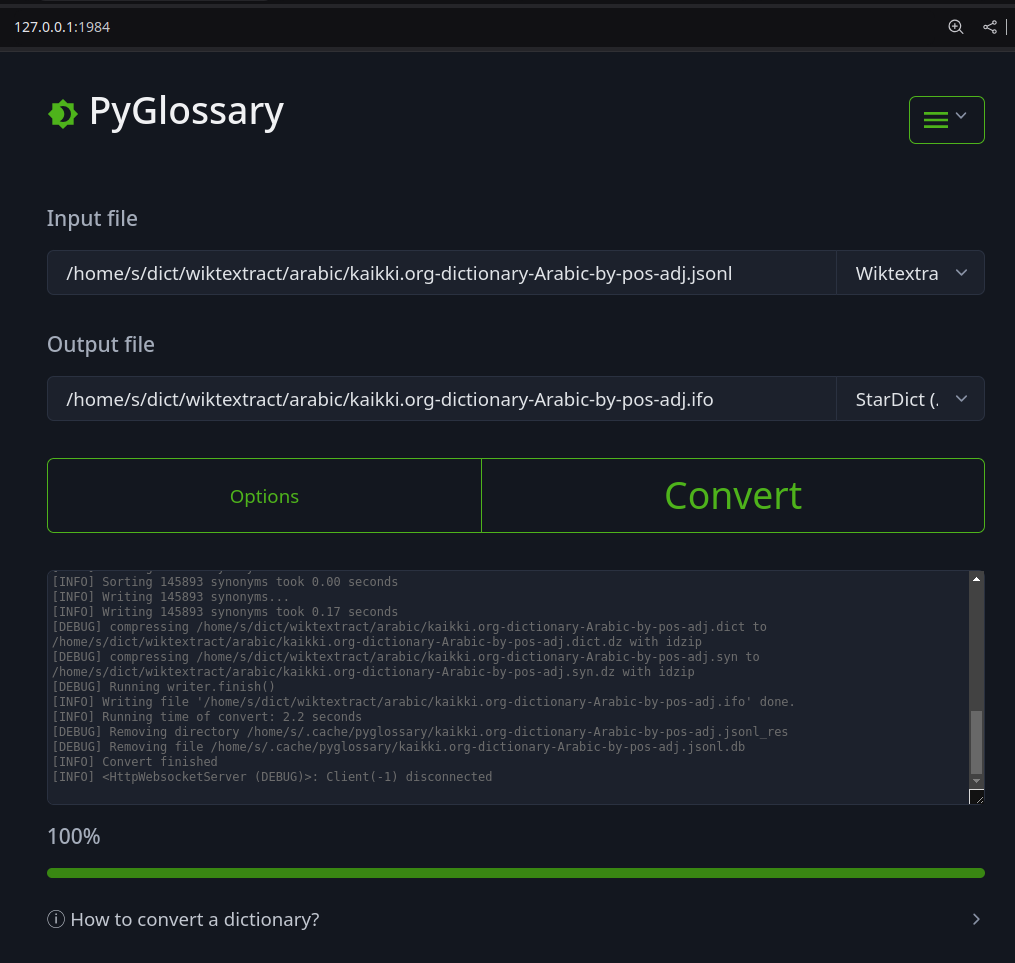
Web interface
## Supported formats
| Format | | Extension | Read | Write |
| ------------------------------------------------------- | :-: | :-------------: | :--: | :---: |
| [Aard 2 (slob)](./doc/p/aard2_slob.md) | 🔢 | .slob | ✅ | ✅ |
| [AppleDict Binary](./doc/p/appledict_bin.md) | 📁 | .dictionary | ✅ | ❌ |
| [AppleDict Source](./doc/p/appledict.md) | 📁 | | | ✅ |
| [Babylon BGL](./doc/p/babylon_bgl.md) | 🔢 | .bgl | ✅ | ❌ |
| [CSV](./doc/p/csv.md) | 📝 | .csv | ✅ | ✅ |
| [DICT.org / Dictd server](./doc/p/dict_org.md) | 📁 | (📝.index) | ✅ | ✅ |
| [DICT.org / dictfmt source](./doc/p/dict_org_source.md) | 📝 | (.dtxt) | | ✅ |
| [dictunformat output file](./doc/p/dictunformat.md) | 📝 | (.dictunformat) | ✅ | |
| [DictionaryForMIDs](./doc/p/dicformids.md) | 📁 | (📁.mids) | ✅ | ✅ |
| [DIKT JSON](./doc/p/dikt_json.md) | 📝 | (.json) | | ✅ |
| [EPUB-2 E-Book](./doc/p/epub2.md) | 📦 | .epub | ❌ | ✅ |
| [FreeDict](./doc/p/freedict.md) | 📝 | .tei | ✅ | ❌ |
| [Gettext Source](./doc/p/gettext_po.md) | 📝 | .po | ✅ | ✅ |
| [HTML Directory (by file size)](./doc/p/html_dir.md) | 📁 | | ❌ | ✅ |
| [JSON](./doc/p/json.md) | 📝 | .json | | ✅ |
| [Kobo E-Reader Dictionary](./doc/p/kobo.md) | 📦 | .kobo.zip | ❌ | ✅ |
| [Kobo E-Reader Dictfile](./doc/p/kobo_dictfile.md) | 📝 | .df | ✅ | ✅ |
| [Lingoes Source](./doc/p/lingoes_ldf.md) | 📝 | .ldf | ✅ | ✅ |
| [Mobipocket E-Book](./doc/p/mobi.md) | 🔢 | .mobi | ❌ | ✅ |
| [Octopus MDict](./doc/p/octopus_mdict.md) | 🔢 | .mdx | ✅ | ❌ |
| [QuickDic version 6](./doc/p/quickdic6.md) | 🔢 | .quickdic | ✅ | ✅ |
| [SQL](./doc/p/sql.md) | 📝 | .sql | ❌ | ✅ |
| [StarDict](./doc/p/stardict.md) | 📁 | (📝.ifo) | ✅ | ✅ |
| [StarDict Textual File](./doc/p/stardict_textual.md) | 📝 | (.xml) | ✅ | ✅ |
| [Tabfile](./doc/p/tabfile.md) | 📝 | .txt, .tab | ✅ | ✅ |
| [Wiktextract](./doc/p/wiktextract.md) | 📝 | .jsonl | ✅ | ❌ |
| [XDXF](./doc/p/xdxf.md) | 📝 | .xdxf | ✅ | ❌ |
| [Zim (Kiwix)](./doc/p/zim.md) | 🔢 | .zim | ✅ | |
| [ABBYY Lingvo DSL](./doc/p/dsl.md) 🇷🇺 | 📝 | .dsl | ✅ | ❌ |
| [Almaany.com](./doc/p/almaany.md) (Arabic) | 🛢️ | .db | ✅ | ❌ |
| [cc-kedict](./doc/p/cc_kedict.md) 🇰🇷 | 📝 | | ✅ | ❌ |
| [Dict.cc](./doc/p/dict_cc.md) 🇩🇪 | 🛢️ | .db | ✅ | |
| [DigitalNK](./doc/p/digitalnk.md) 🇰🇵 | 🛢️ | .db | ✅ | |
| [EDICT2 (CEDICT)](./doc/p/edict2.md) 🇨🇳 | 📝 | (.u8) | ✅ | ❌ |
| [JMDict](./doc/p/jmdict.md) 🇯🇵 | 📝 | | ✅ | ❌ |
| [JMnedict](./doc/p/jmnedict.md) 🇯🇵 | 📝 | | ✅ | ❌ |
| [WordNet](./doc/p/wordnet.md) 🇬🇧 | 📁 | | ✅ | ❌ |
| [@wordset dictionary](./doc/p/wordset.md) 🇬🇧 | 📁 | | ✅ | |
| [Yomichan / Yomitan](./doc/p/yomichan.md) 🇯🇵 | 📦 | (.zip) | | ✅ |
Legend:
- 📁 Directory
- 📝 Text file
- 📦 Package/archive file
- 🛢️ SQLite file
- 🔢 Binary file
- ✅ Supported
- ❌ Will not be supported
**Note**: SQLite-based formats are not detected by extension (`.db`);
So you need to select the format (with UI or `--read-format` flag).
**Also don't confuse SQLite-based formats with [SQLite mode](#sqlite-mode).**
## Requirements
PyGlossary requires **Python 3.10 or higher**, and works in practically all
mainstream operating systems, including *GNU/Linux*, *Windows*, *Mac OS*,
*FreeBSD* and other common Unix-based operating systems.
As shown in screenshots, there are multiple User Interface types (multiple
ways to use the program).
- **Gtk3-based interface**, uses [PyGI](http://pygobject.readthedocs.io/en/latest/getting_started.html)+Gtk3.
See [doc/gtk3.md](./doc/gtk3.md) for how to install it on Linux and Mac OS X.
- **Gtk4-based interface**, uses [PyGI](http://pygobject.readthedocs.io/en/latest/getting_started.html)+Gtk4.
See [doc/gtk4.md](./doc/gtk4.md).
This is still not as complete as Gtk3 interface.
- **Tkinter-based interface**, meant to be used in the lack of Gtk. Specially on
Windows where Tkinter library is installed with Python itself.
You can [install Tkinter](./doc/tkinter.md) on Linux or Mac OS X.
- **Command-line interface**, works in all operating systems without
any specific requirements, just type `./main.py --help` or `pyglossary --help`
- **Interactive command-line interface**
- Requires: `pip install prompt_toolkit`
- Perfect for mobile devices (like Termux on Android) where no GUI is available
- Automatically selected if output file argument is not passed **and** one of these:
- On Linux and `$DISPLAY` environment variable is empty or not set
- For example when you are using a remote Linux machine over SSH
- On Mac and no `tkinter` module is found
- Manually select with `--cmd` or `--ui=cmd`
- Minimally: `./main.py --cmd`
- You can still pass input file, or any flag/option
- If both input and output files are passed, non-interactive cmd ui will be default.
- Pass `--interactive` to change it.
- If you are writing a script, you can pass `--no-interactive` to force disable interactive ui
- Then you have to pass both input and output file arguments
- Don't forget to use *Up/Down* or *Tab* keys in prompts!
- Up/Down key shows you recent values you have used
- Tab key shows available values/options
- You can press Control+C (on Linux/Windows) at any prompt to exit
## UI (User Interface) selection
When you run PyGlossary without any command-line arguments or options/flags, PyGlossary will try to run the first available interface:
- It tries to find PyGI+Gtk3 and open **Gtk3-based** interface.
- It tries to find PyGI+Gtk4 and open **Gtk4-based** interface.
- It tries to find Tkinter and open **Tkinter-based** interface.
- If it's run in command line (with stdin connected to a terminal) it tries to find `prompt_toolkit` and run **interactive command-line** interface.
- It runs a HTTP server and opens the **web interface** in your browser.
The order depends on operating system. Currently on Mac OS and Windows, Tkinter is checked before Gtk.
You can explicitly select user interface type using `--ui`
- `./main.py --ui=gtk3`
- `./main.py --ui=gtk4`
- `./main.py --ui=gtk` which currently selects `gtk3`
- `./main.py --ui=tk`
- `./main.py --ui=web`
- `./main.py --ui=cmd`
## Installation on Windows
- [Download and install Python](https://www.python.org/downloads/windows/) (3.10 or above)
- Open Start -> type Command -> right-click on Command Prompt -> Run as administrator
- To ensure you have `pip`, run: `python -m ensurepip --upgrade`
- To install, run: `pip install --upgrade pyglossary`
- Now you should be able to run `pyglossary` command
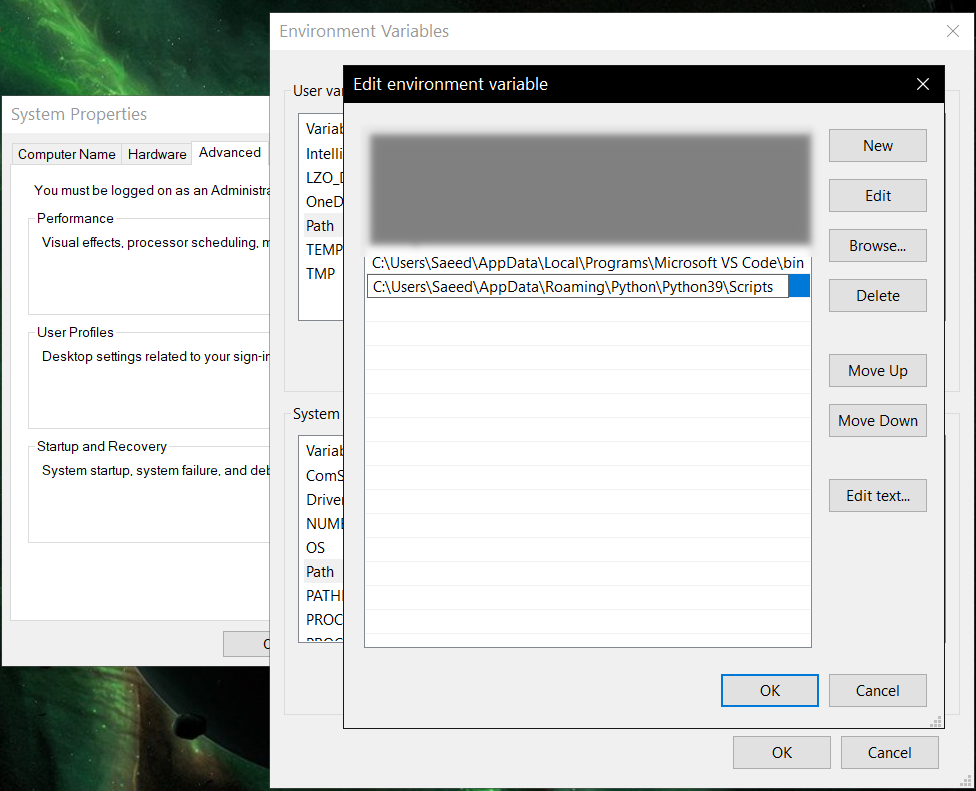
- If command was not found, make sure Python environment variables are set up:
## Feature-specific requirements
- Using [Sort by Locale](#sorting) feature requires [PyICU](./doc/pyicu.md)
- Using `--remove-html-all` flag requires:
`pip install lxml beautifulsoup4`
Some formats have additional requirements.
If you have trouble with any format, please check the [link given for that format](#supported-formats) to see its documentations.
**Using Termux on Android?** See [doc/termux.md](./doc/termux.md)
## Configuration
See [doc/config.rst](./doc/config.rst).
## Direct and indirect modes
Indirect mode means that input glossary is completely read and loaded into RAM, then converted
into output format. This was the only method available in old versions (before [3.0.0](https://github.com/ilius/pyglossary/releases/tag/3.0.0)).
Direct mode means entries are one-at-a-time read, processed and written into output glossary.
Direct mode was added to limit memory usage for large glossaries; But it may reduce the
conversion time for most cases as well.
Converting glossaries into these formats requires [sorting](#sorting) entries:
- [StarDict](./doc/p/stardict.md)
- [EPUB-2](./doc/p/epub2.md)
- [Mobipocket E-Book](./doc/p/mobi.md)
- [Yomichan](./doc/p/yomichan.md)
- [DictionaryForMIDs](./doc/p/dicformids.md)
That's why direct mode will not work for these formats, and PyGlossary has to
switch to indirect mode (or it previously had to, see [SQLite mode](#sqlite-mode)).
For other formats, direct mode will be default. You may override this by `--indirect` flag.
## SQLite mode
As mentioned above, converting glossaries to some specific formats will
need them to loaded into RAM.
This can be problematic if the glossary is too big to fit into RAM. That's when
you should try adding `--sqlite` flag to your command. Then it uses SQLite3 as intermediate
storage for storing, sorting and then fetching entries. This fixes the memory issue, and may
even reduce running time of conversion (depending on your home directory storage).
The temporary SQLite file is stored in [cache directory](#cache-directory) then
deleted after conversion (unless you pass `--no-cleanup` flag).
SQLite mode is automatically enabled for writing these formats if `auto_sqlite`
[config parameter](./doc/config.rst) is `true` (which is default).
This also applies to when you pass `--sort` flag for any format.
You may use `--no-sqlite` to override this and switch to indirect mode.
Currently you can not disable alternates in SQLite mode (`--no-alts` is ignored).
## Sorting
There are two things than can activate sorting entries:
- Output format requires sorting (as explained [above](#direct-and-indirect-modes))
- You pass `--sort` flag in command line.
In the case of passing `--sort`, you can also pass:
- `--sort-key` to select sort key aka sorting order (including locale), see [doc/sort-key.md](./doc/sort-key.md)
- `--sort-encoding` to change the encoding used for sort
- UTF-8 is the default encoding for all sort keys and all output formats (unless mentioned otherwise)
- This will only effect the order of entries, and will not corrupt words / definition
- Non-encodable characters are replaced with `?` byte (*only for sorting*)
## Cache directory
Cache directory is used for storing temporary files which are either moved or deleted
after conversion. You can pass `--no-cleanup` flag in order to keep them.
The path for cache directory:
- Linux or BSD: `~/.cache/pyglossary/`
- Mac: `~/Library/Caches/PyGlossary/`
- Windows: `C:\Users\USERNAME\AppData\Local\PyGlossary\Cache\`
## User plugins
If you want to add your own plugin without adding it to source code directory,
or you want to use a plugin that has been removed from repository,
you can place it in this directory:
- Linux or BSD: `~/.pyglossary/plugins/`
- Mac: `~/Library/Preferences/PyGlossary/plugins/`
- Windows: `C:\Users\USERNAME\AppData\Roaming\PyGlossary\plugins\`
## Linux packaging status
[](https://repology.org/project/pyglossary/versions)
## Using PyGlossary as a library
See [doc/lib-usage.md](./doc/lib-usage.md) for how to use PyGlossary as a Python library.
## Internals
See [doc/internals.md](./doc/internals.md) for information about internal glossary structure and entry filters.