https://github.com/iml1111/imquanter
엄청 쉬운 퀀트 투자 라이브러리
https://github.com/iml1111/imquanter
backtesting python quant
Last synced: about 2 months ago
JSON representation
엄청 쉬운 퀀트 투자 라이브러리
- Host: GitHub
- URL: https://github.com/iml1111/imquanter
- Owner: iml1111
- License: mit
- Created: 2022-05-28T15:43:28.000Z (over 3 years ago)
- Default Branch: main
- Last Pushed: 2024-03-19T06:27:03.000Z (over 1 year ago)
- Last Synced: 2025-06-15T07:02:16.149Z (4 months ago)
- Topics: backtesting, python, quant
- Language: Python
- Homepage:
- Size: 16.6 KB
- Stars: 1
- Watchers: 1
- Forks: 1
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# IMQuanter
엄청 쉬운 퀀트 투자 라이브러리, IMQuanter입니다 :)
- **종목 추출 라이브러리(IMQaunter) 개발**
- Inspired by **aLLatte**
- **쉽고, 빠르고, 간편하게 종목 정보를 수집하고 분석하자.**
### 설계의 방향성
- **쉬워야 한다.** 가치 지표의 개념 정도는 알지 언정, 계산 방법까지는 몰라도 된다.
- **빨라야 한다.** 한번 인터넷에서 수집한 정보를 다시 가져올 필요는 없다.
- **확장 가능해야 한다.** 사용자가 쉽게 다루게 하면서 다양한 커스터마이징을 지원해야 한다.
## 프로그램 흐름도
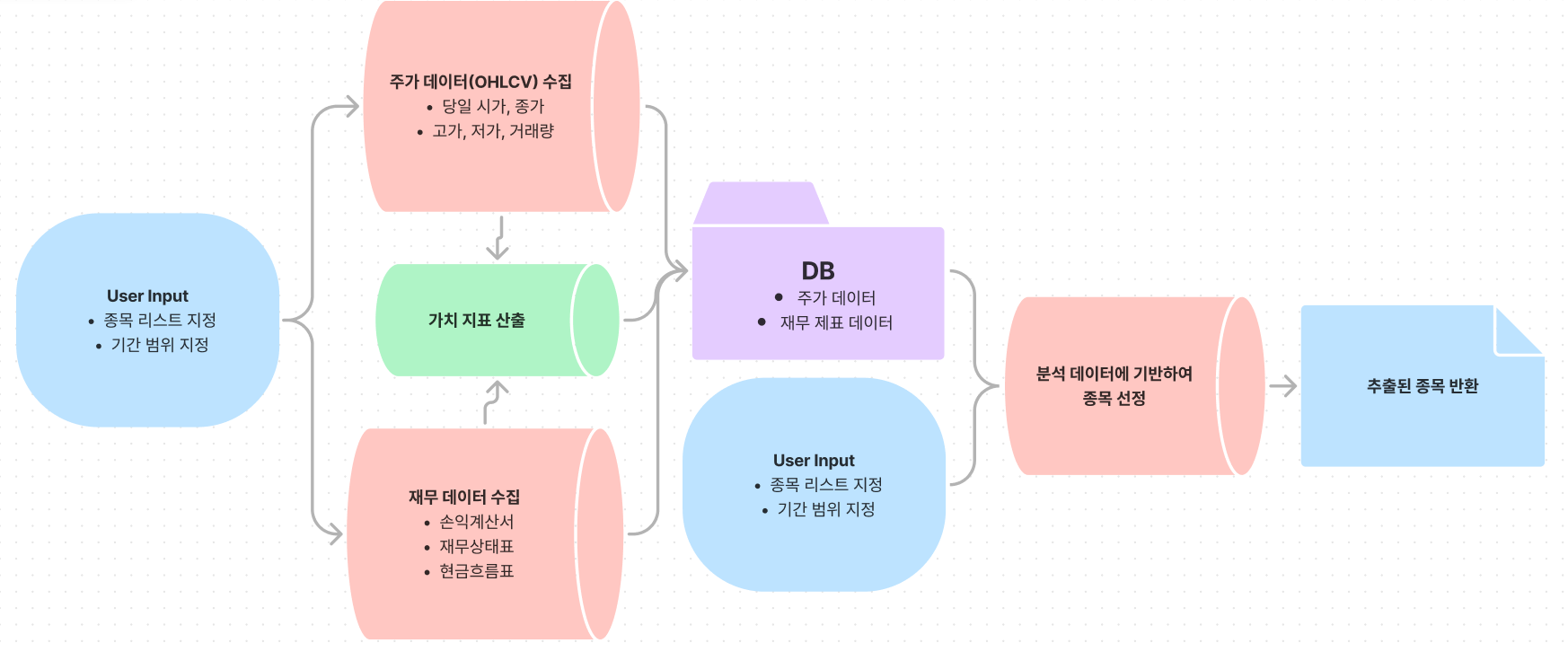
## 데이터베이스 테이블 스키마
### Log Table
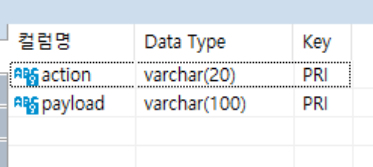
- IMQuanter의 액션 수행 기록
- 해당 액션 수행 기록을 바탕으로 동작 여부 판단.
- action: 행동에 대한 식별자
- payload: 행동에 대한 자세한 내용
### Price Table
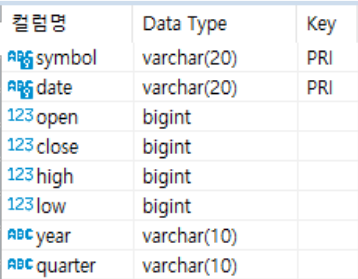
- 종목별 주가 데이터 관리 테이블
### Statement Table
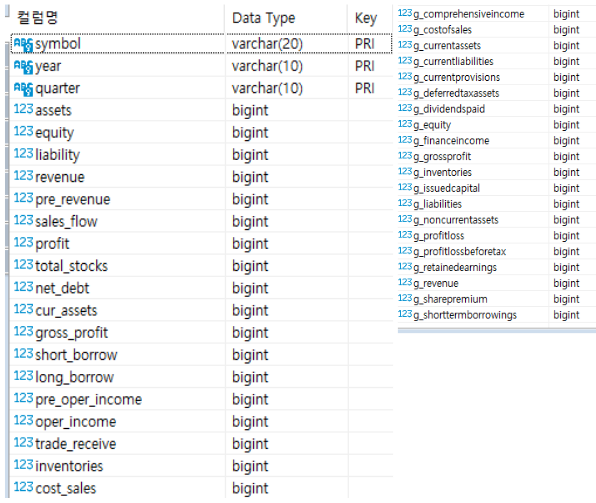
- 각 종목의 재무제표 데이터 관리 테이블
- 각 칼럼 정보는 이전 페이지 참조
- 팩터 수집에 필요한 데이터 외에도 그외 부가적인 데이터를 추가 수집 가능(g_\*).
### Factor Table
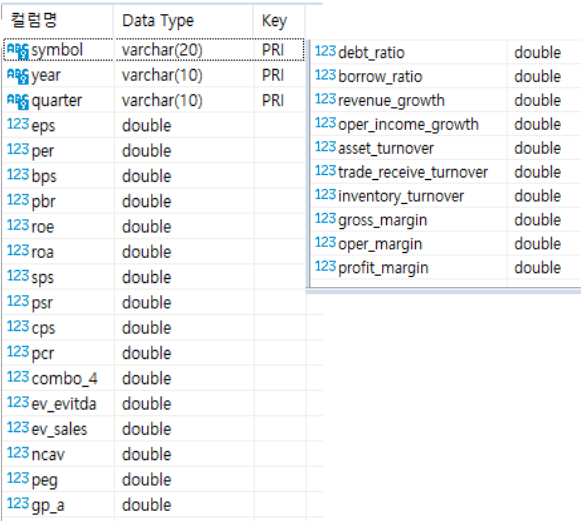
- 각 종목의 가치 지표 데이터 관리 테이블
- 각 칼럼 정보는 이전 페이지 참조
# 기능 동작 명세
## 종목 정보 수집 및 분석
```python
def collect(
self,
start_date: str,
end_date: Optional[str] = None,
targets: Optional[List[str]] = None,
symbols: Optional[List[str]] = None,
dry: bool = False):
"""
# 해당 종목들에 대하여, 수집할 데이터를 추출하여 DB에 저장
:param start_date: 수집 시작 날짜
:param end_date: 수집 마지막 날짜
:param targets: 수집할 데이터 타입 (price, statement, factor)
:param symbols: 수집할 종목코드 리스트
:param dry: 테스트 실행 여부 (종목을 극소수로만 호출)
:return: None
"""
```
- collect() 메소드를 통해, 종목 정보의 수집 및 분석을 동시에 진행
- start_date(시작 날짜)를 제외한 나머지 인자는 모두 Optional argument로 취급.
- 각 기본 값은 아래와 같음
- end_date: 오늘 날짜(2022-XX-XX)
- targets: all (모든 대상 수집을 의미)
- symbol: all (모든 종목 수집을 의미)
- dry: False (True일 경우, 테스트 모드 실행)
## 종목 정보 추출
```python
def get(
self,
filter: Optional[Query] = None,
sort: Optional[List[tuple]] = None,
verbose: bool = False):
"""
# 수집된 종목 정보들을 바탕으로, 적절한 조건에 따라 종목 추출 수행
:param filter: 종목 추출 조건
:param sort: 종목 추출시 정렬 조건
:param verbose: 출력 범위 여부
:return: 종목 코드 리스트 or 세부 종목 정보 리스트
"""
```
- get() 메소드를 통해 입력받은 조건에 맞는 종목 리스트를 호출
- filter 인자에 들어가게 되는 Query란, IMQuatner의 종목 추출 기능을 객체 지향적으로 구현하기 위한 자체 필터 객체를 뜻함.
- verbose가 True일 경우, 종목 코드 리스트 외에도, 조회를 위해 실행된 Raw SQL 및 각 종목들의 세부 정보 데이터를 함께 반환.
## 동작 예시
### 정보 정보 수집 및 분석
```python
from imquanter import Quanter
# Quanter Manager 객체 호출 및 DB 연동
quanter = Quanter(db_uri=DB_URI, dart_key=DART_KEY)
# 종목 정보 수집 및 분석 수행
# dry=True 테스트 모드 진행시 (삼성전자, 엘지전자만 호출)
quanter.collect(
start_date='2020-01-01',
dry=True
)
"""
위 collect 메소드는 아래의 메소드와 일치합니다.
quanter.collect(
symbols='all', # 모든 종목 수집
targets=['price', 'financial_statement'], # 주가, 재무제표 및 팩터 함께 수집
start_date='2020-01-01',
end_date=NOW_DATE, # 마지막 날짜를 오늘 날짜로 등록
dry=True
)
"""
```
아래와 같이 타겟 종목에 대한 주가 및 재무제표, 그를 통한 팩터가 수집된 것을 확인할 수 있습니다.
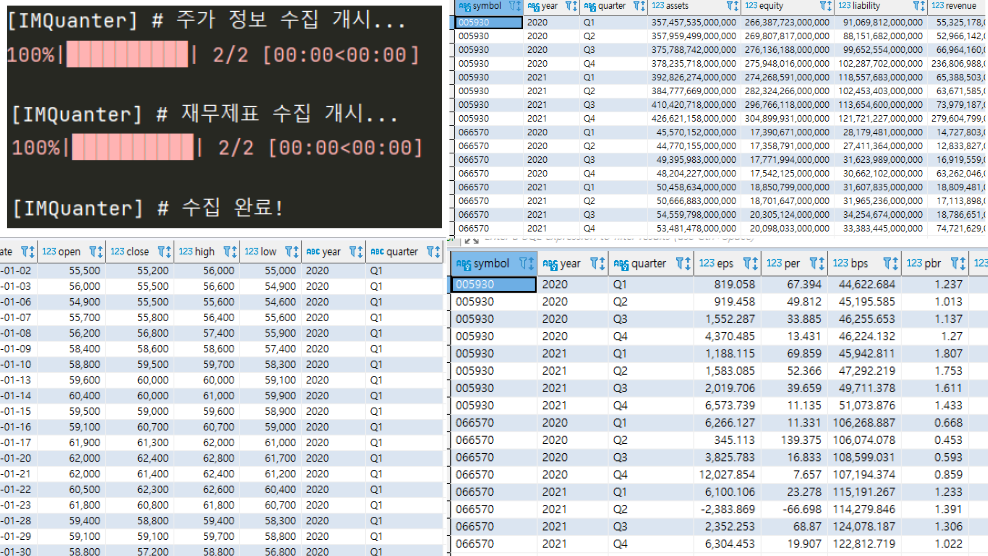
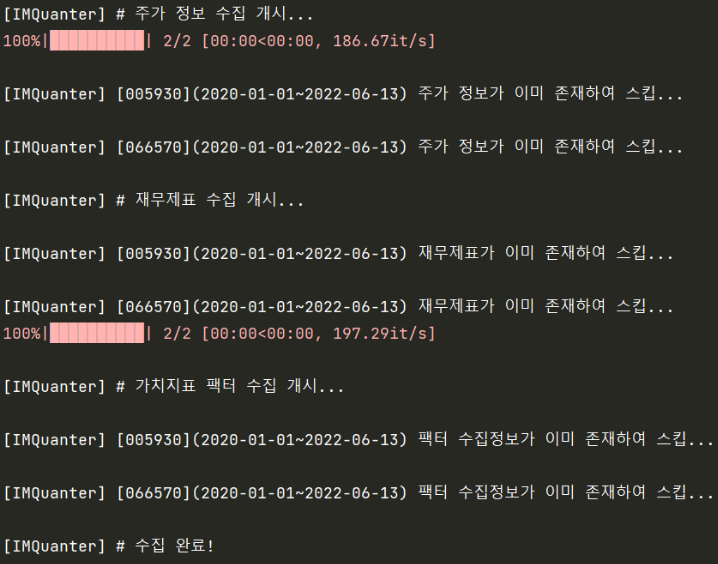
> 이미 과거에 수집한 기록이 있을 경우
모든 수집 기록을 로깅하여 과거에 수집한 기록이 있다고 판단할 경우, 다음과 같은 문구를 출력하며 해당 부분에 대한 수집만 스킵하도록 구현하였음.
### 종목 정보 추출
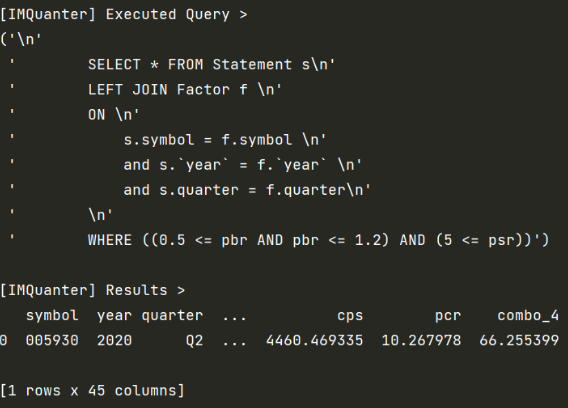
Query 매니저 객체를 통해 입력된 객체에 대한 OR, AND 연산자를 이용해 동적으로 쿼리를 생성 후, 연산을 수행함. 기본적인 퀀트 투자에서 사용되는 여러가지 지표가 이미 구현되어 있으며, 원한다면 직접 객체를 상속받아 커스텀하거나 복수의 조건을 결합하여 새로운 지표를 만들어 낼 수 있음.
```python
# Query Manager 객체 임포트
from imquanter import *
# PBR이 0.5 ~ 1.2 사이이고,
# PSR이 5 이상인 종목 조회.
result = quanter.get(
filter=PBR(0.5, 1.2) & PSR(gte=5),
verbose=True
)
```
`verbose=True`를 통해 좀 더 자세한 실행 결과를 조회할 수 있음.
# 설계 및 차별성
## 객체 지향 및 의존성 분리
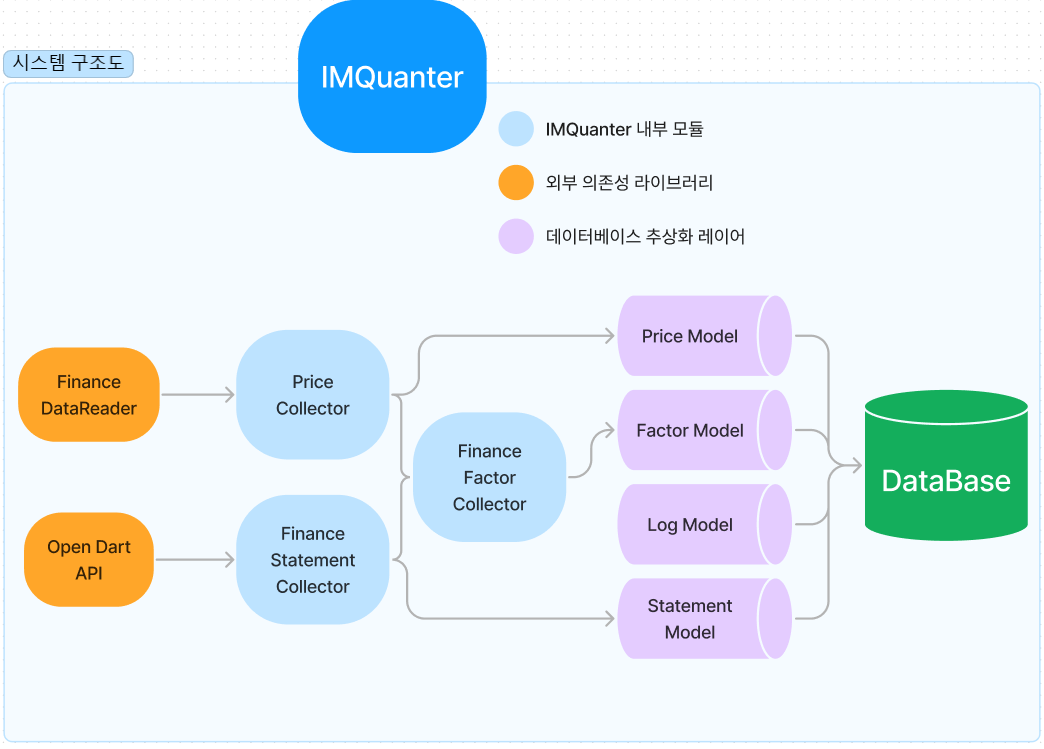
- 프로그램의 확장성, 다형성을 위해 해당 모듈의 모든 부분을 Class 기반으로 구현
- 각 생성된 객체는 모두 상호간의 의존성을 최소화하여, 유닛 테스트를 비롯한 단위 실행을 수월하도록 함
- 실제 DBMS와 어플리케이션 간의 의존성을 최소화하기 위해 추상화 레이어를 구축.
## 오브젝트 기반 쿼리
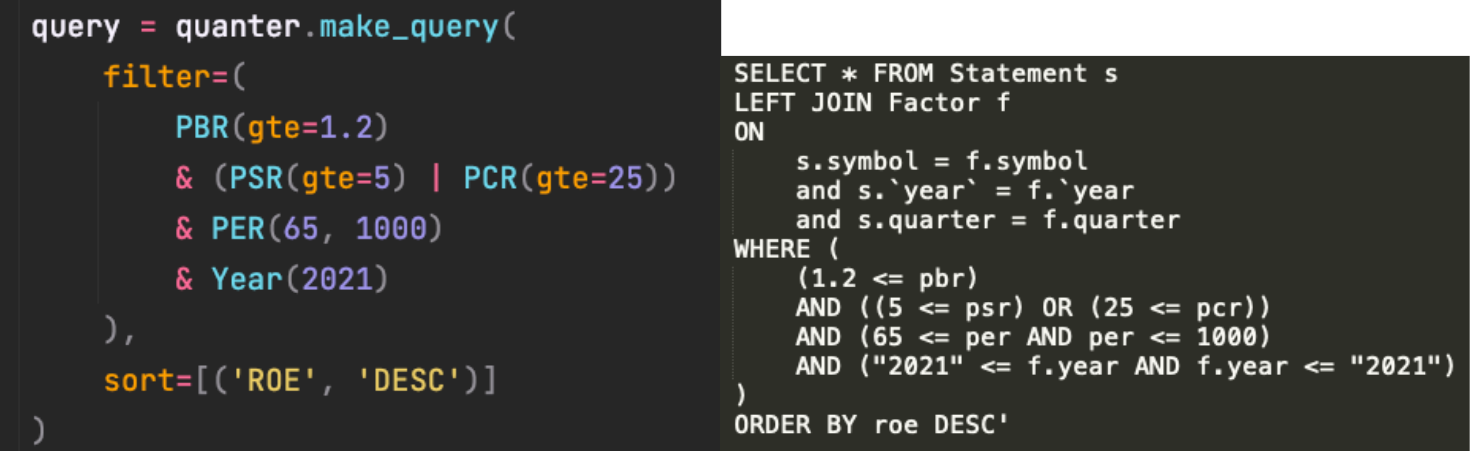
- 사용자가 쉽게 종목을 필터링할 수 있도록 객체 기반한 쿼리 인터페이스를 제공
## 다양한 쿼리셋과 커스터마이징
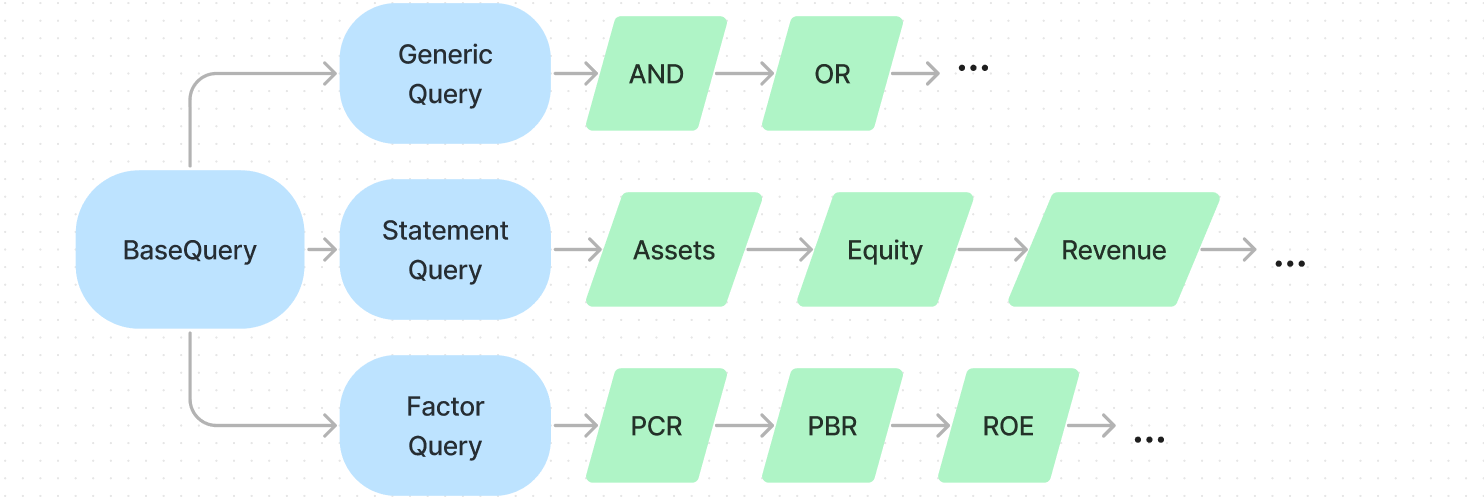
\- **클래스의 다중 상속을 이용해 쿼리셋 구조 체계화**
\- **어떤 쿼리나 조건이라도 받아들일 수 있는 확장성 있는 구조**
## 수집 및 분석 로그를 통한 캐싱
- collect() 메소드에 대하여 price, statement, factor를 분리하여 각 종목별 기간 범위 구간을 수집했음을 기록.
- collect() 메소드가 실제 데이터 수집을 실행하기 직전, Log table에 접속하여 과거에 기록이 있는지 확인.
- **기록만으로 해당 데이터가 Table에 존재함을 파악하므로, 성능상의 오버헤드가 적음**.