https://github.com/iml1111/machine-translation
Neural Machine Translation with Transformer
https://github.com/iml1111/machine-translation
machine-translation nlp pytorch seq2seq transformer
Last synced: 7 months ago
JSON representation
Neural Machine Translation with Transformer
- Host: GitHub
- URL: https://github.com/iml1111/machine-translation
- Owner: iml1111
- License: mit
- Created: 2021-01-24T11:24:06.000Z (over 4 years ago)
- Default Branch: main
- Last Pushed: 2021-01-25T13:31:25.000Z (over 4 years ago)
- Last Synced: 2025-02-03T15:55:47.812Z (8 months ago)
- Topics: machine-translation, nlp, pytorch, seq2seq, transformer
- Language: Python
- Homepage:
- Size: 84 KB
- Stars: 3
- Watchers: 2
- Forks: 1
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# machine-translation
해당 repo는 제가 기계 번역기를 구현하기 위해 공부한 학습 및 추론 코드를 정리한 곳입니다.
해당 기계 번역기는 Sequence-to-Sequence, Transformer로 구현되어 있습니다.
## Dependency
자세한 사항은 [requirements.txt](https://github.com/iml1111/machine-translation/blob/main/requirements.txt)를 참고해주세요.
- Python 3.6 이상
- PyTorch 1.6 이상
- TorchText 0.5 이상
- PyTorch Ignite
# Sequence to Sequence
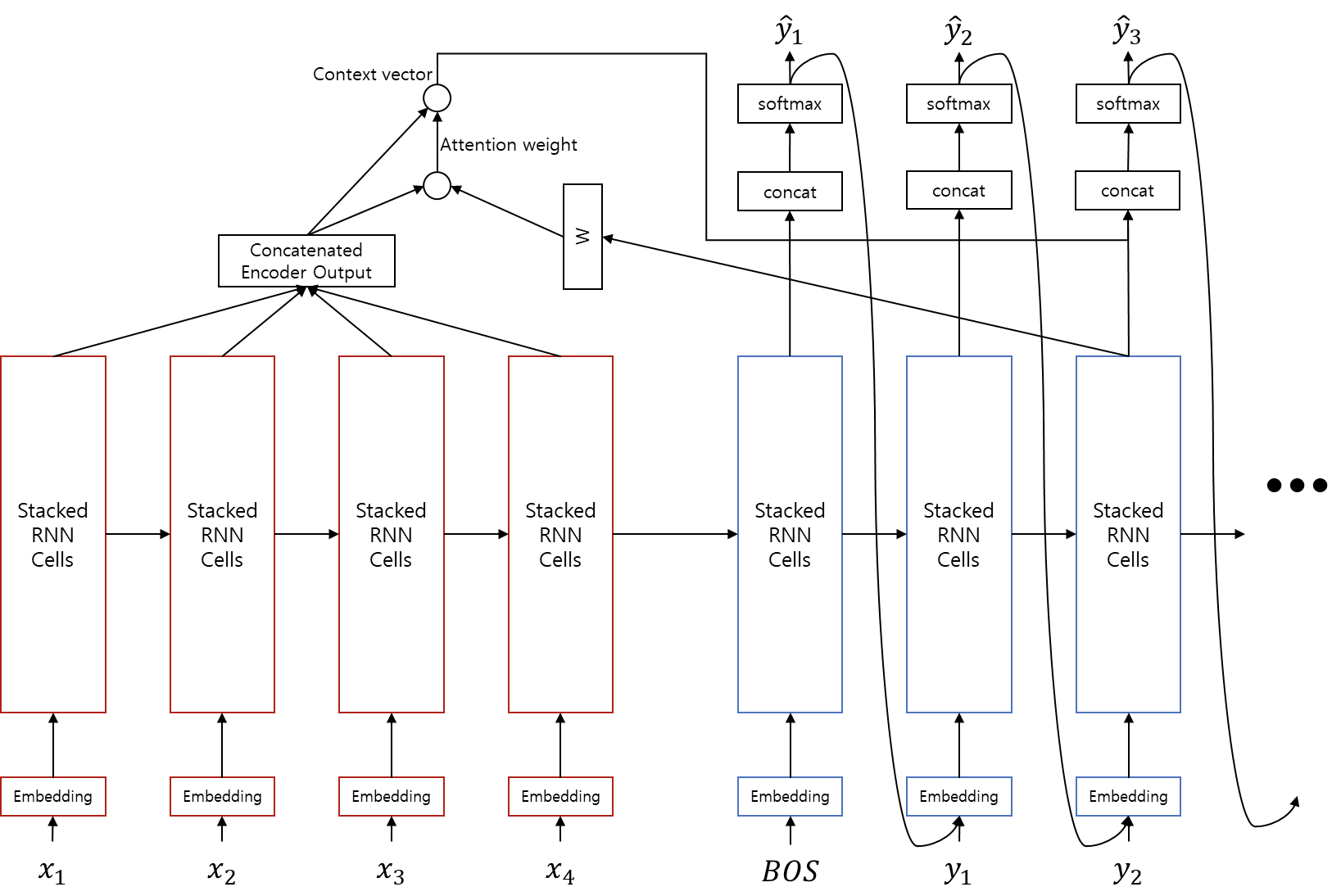
LSTM 및 Attention을 기반으로 한, **Seq2Seq Model**입니다.
**Lose Function으로는 NLLLoss**를 사용하며, **Optimizer로는 Adam**을 사용합니다. 아래와 같은 파라미터가 주어졌을 때, 모델은 다음과 같은 형태로 구성됩니다.
### Hyperparameter Example
```python
{
'batch_size': 256,
'dropout': 0.2,
'gpu_id': 0,
'hidden_size': 768,
'init_epoch': 1,
'iteration_per_update': 1,
'lang': 'enko',
'lr': 0.001,
'max_grad_norm': 100000000.0,
'max_length': 100,
'model_fn': './models/model.pth',
'n_epochs': 30,
'n_layers': 4,
'off_autocast': False,
'train': './data/corpus.shuf.train.tok.bpe',
'valid': './data/corpus.shuf.valid.tok.bpe',
'verbose': 2,
'word_vec_size': 512
}
```
### Model Architecture Sample
```python
Seq2Seq(
(emb_src): Embedding(24014, 512)
(emb_dec): Embedding(30116, 512)
(encoder): Encoder(
(rnn): LSTM(512, 384, num_layers=4, batch_first=True, dropout=0.2, bidirectional=True)
)
(decoder): Decoder(
(rnn): LSTM(1280, 768, num_layers=4, batch_first=True, dropout=0.2)
)
(attn): Attention(
(linear): Linear(in_features=768, out_features=768, bias=False)
(softmax): Softmax(dim=-1)
)
(concat): Linear(in_features=1536, out_features=768, bias=True)
(tanh): Tanh()
(generator): Generator(
(output): Linear(in_features=768, out_features=30116, bias=True)
(softmax): LogSoftmax(dim=-1)
)
)
NLLLoss()
Adam (
Parameter Group 0
amsgrad: False
betas: (0.9, 0.999)
eps: 1e-08
lr: 0.001
weight_decay: 0
)
```
## Usage
아래와 같은 옵션을 통해 학습을 수행할 수 있습니다. 기본적으로 **--train, --valid** 옵션을 제외하면 default 옵션으로 잘 돌아갑니다.
```
usage: train_seq2seq.py [-h] [--model_fn MODEL_FN] [--train TRAIN]
[--valid VALID] [--lang LANG] [--gpu_id GPU_ID]
[--batch_size BATCH_SIZE] [--n_epochs N_EPOCHS]
[--verbose VERBOSE] [--init_epoch INIT_EPOCH]
[--max_length MAX_LENGTH] [--dropout DROPOUT]
[--word_vec_size WORD_VEC_SIZE]
[--hidden_size HIDDEN_SIZE] [--n_layers N_LAYERS]
[--max_grad_norm MAX_GRAD_NORM]
[--iteration_per_update ITERATION_PER_UPDATE]
[--lr LR] [--off_autocast]
optional arguments:
-h, --help show this help message and exit
--model_fn MODEL_FN 모델을 저장할 파일 이름을 입력해주세요.
--train TRAIN Training set에 사용될 Filepath를 입력해주세요. (뒤의 en,ko를 제외해야
합니다) (ex: train.en --> train)
--valid VALID Validation set에 사용될 Filepath를 입력해주세요. (ex: valid.en
--> valid)
--lang LANG 학습시킬 언어의 쌍을 입력해주세요. (영어를 한국어로 번역할 경우, ex: en + ko -->
enko)
--gpu_id GPU_ID 학습에 사용할 GPU ID를 입력해주세요. -1 for CPU. Default=0
--batch_size BATCH_SIZE
batch size. Default=256
--n_epochs N_EPOCHS 학습할 epochs 수. Default=30
--verbose VERBOSE VERBOSE = 0, 1, 2. Default=2
--init_epoch INIT_EPOCH
시작 epochs 값. Default=1
--max_length MAX_LENGTH
학습시, 한 문장의 최대 토큰 길이. Default=100
--dropout DROPOUT Dropout rate. Default=0.2
--word_vec_size WORD_VEC_SIZE
Word embedding vector 차원수. Default=512
--hidden_size HIDDEN_SIZE
LSTM에 사용될 Hidden size. Default=768
--n_layers N_LAYERS LSTM의 layers 수. Default=4
--max_grad_norm MAX_GRAD_NORM
Gradient Clipping을 위한 max grad norm.
Default=100000000.0
--iteration_per_update ITERATION_PER_UPDATE
Gradient Accumulation을 위한 파라미터 갱신 주기. Default=1
--lr LR learning rate. Default=0.001
--off_autocast Automatic Mixed Precision Turn-off 여부
```
# Transformer
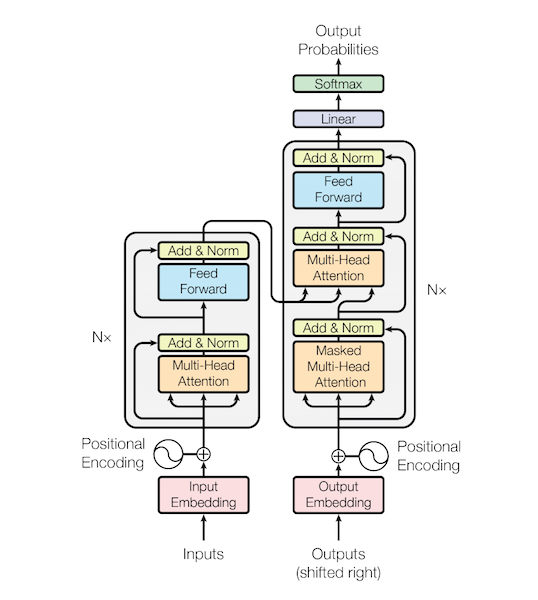
Pre-LN 기반으로 작성된 **Transformer Model**입니다.
**Lose Function으로는 NLLLoss**를 사용하며, **Optimizer로는 Adam**을 사용하며, 이는 위의 Seq2Seq와 일치합니다. (Pre-LN을 사용했기 때문에, Adam으로도 안정적인 학습이 가능합니다)
아래와 같은 파라미터가 주어졌을 때, 모델은 다음과 같은 형태로 구성됩니다.
### Hyperparameter Example
```python
{
'batch_size': 256,
'dropout': 0.2,
'gpu_id': 0,
'hidden_size': 768,
'init_epoch': 1,
'iteration_per_update': 32,
'lang': 'enko',
'lr': 0.001,
'max_grad_norm': 100000000.0,
'max_length': 100,
'model_fn': './models/model.pth',
'n_epochs': 30,
'n_layers': 1,
'n_splits': 8,
'train': './data/corpus.shuf.train.tok.bpe',
'valid': './data/corpus.shuf.valid.tok.bpe',
'verbose': 2
}
```
### Model Architecture Sample
```python
Transformer(
(emb_enc): Embedding(24014, 768)
(emb_dec): Embedding(30116, 768)
(emb_dropout): Dropout(p=0.2, inplace=False)
(encoder): MySequential(
(0): EncoderBlock( # n_layers 값에 따라 추가 생성됨
(attn): MultiHead(
(Q_linear): Linear(in_features=768, out_features=768, bias=False)
(K_linear): Linear(in_features=768, out_features=768, bias=False)
(V_linear): Linear(in_features=768, out_features=768, bias=False)
(linear): Linear(in_features=768, out_features=768, bias=False)
(attn): Attention(
(softmax): Softmax(dim=-1)
)
)
(attn_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn_dropout): Dropout(p=0.2, inplace=False)
(fc): Sequential(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): ReLU()
(2): Linear(in_features=3072, out_features=768, bias=True)
)
(fc_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(fc_dropout): Dropout(p=0.2, inplace=False)
)
)
(decoder): MySequential(
(0): DecoderBlock( # n_layers 값에 따라 추가 생성됨
(masked_attn): MultiHead(
(Q_linear): Linear(in_features=768, out_features=768, bias=False)
(K_linear): Linear(in_features=768, out_features=768, bias=False)
(V_linear): Linear(in_features=768, out_features=768, bias=False)
(linear): Linear(in_features=768, out_features=768, bias=False)
(attn): Attention(
(softmax): Softmax(dim=-1)
)
)
(masked_attn_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(masked_attn_dropout): Dropout(p=0.2, inplace=False)
(attn): MultiHead(
(Q_linear): Linear(in_features=768, out_features=768, bias=False)
(K_linear): Linear(in_features=768, out_features=768, bias=False)
(V_linear): Linear(in_features=768, out_features=768, bias=False)
(linear): Linear(in_features=768, out_features=768, bias=False)
(attn): Attention(
(softmax): Softmax(dim=-1)
)
)
(attn_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn_dropout): Dropout(p=0.2, inplace=False)
(fc): Sequential(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): ReLU()
(2): Linear(in_features=3072, out_features=768, bias=True)
)
(fc_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(fc_dropout): Dropout(p=0.2, inplace=False)
)
)
(generator): Sequential(
(0): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(1): Linear(in_features=768, out_features=30116, bias=True)
(2): LogSoftmax(dim=-1)
)
)
NLLLoss()
Adam (
Parameter Group 0
amsgrad: False
betas: (0.9, 0.98)
eps: 1e-08
lr: 0.001
weight_decay: 0
)
```
## Usage
아래와 같은 옵션을 통해 학습을 수행할 수 있습니다. 기본적으로 **--train, --valid** 옵션을 제외하면 default 옵션으로 잘 돌아갑니다.
```
usage: train_transformer.py [-h] [--model_fn MODEL_FN] [--train TRAIN]
[--valid VALID] [--lang LANG] [--gpu_id GPU_ID]
[--batch_size BATCH_SIZE] [--n_epochs N_EPOCHS]
[--verbose VERBOSE] [--init_epoch INIT_EPOCH]
[--max_length MAX_LENGTH] [--dropout DROPOUT]
[--hidden_size HIDDEN_SIZE] [--n_layers N_LAYERS]
[--max_grad_norm MAX_GRAD_NORM]
[--iteration_per_update ITERATION_PER_UPDATE]
[--lr LR] [--n_splits N_SPLITS] [--off_autocast]
optional arguments:
-h, --help show this help message and exit
--model_fn MODEL_FN 모델을 저장할 파일 이름을 입력해주세요.
--train TRAIN Training set에 사용될 Filepath (뒤의 en,ko를 제외해야 합니다) (ex:
train.en --> train)
--valid VALID Validation set에 사용될 Filepath (ex: valid.en --> valid)
--lang LANG 학습시킬 언어의 쌍 (영어를 한국어로 번역할 경우, ex: en + ko --> enko)
--gpu_id GPU_ID 학습에 사용할 GPU ID를 입력해주세요. -1 for CPU. Default=0
--batch_size BATCH_SIZE
batch size. Default=128
--n_epochs N_EPOCHS 학습할 epochs 수. Default=30
--verbose VERBOSE VERBOSE = 0, 1, 2. Default=2
--init_epoch INIT_EPOCH
시작 epochs 값. Default=1
--max_length MAX_LENGTH
학습시, 한 문장의 최대 토큰 길이. Default=100
--dropout DROPOUT Dropout rate. Default=0.2
--hidden_size HIDDEN_SIZE
Transformer ENC, DEC에 사용될 Hidden size. Default=768
--n_layers N_LAYERS ENC, DEC의 layers 수 Default=4
--max_grad_norm MAX_GRAD_NORM
Gradient Clipping을 위한 max grad norm.
Default=100000000.0
--iteration_per_update ITERATION_PER_UPDATE
Gradient Accumulation을 위한 파라미터 갱신 주기. Default=32
--lr LR learning rate. Default=0.001
--n_splits N_SPLITS multi-head attention의 Head 수. Default=8
--off_autocast Automatic Mixed Precision Turn-off 여부
```
# Inference
학습이 완료된 모델은 다음과 같은 방식을 통해 예측을 수행할 수 있습니다. **--model_fn**에서 예측할 모델을 지정한 후, 해당 모델이 Transformer인 경우, **--user_transformer** 옵션도 함께 주어야 합니다.
**beam_size**는 default로 1로 설정되어 있는데, 값을 높여줄 경우, beam search를 수행합니다.
```
>> python translate.py -h
usage: translate.py [-h] --model_fn MODEL_FN [--gpu_id GPU_ID]
[--batch_size BATCH_SIZE] [--max_length MAX_LENGTH]
[--n_best N_BEST] [--beam_size BEAM_SIZE] [--lang LANG]
[--length_penalty LENGTH_PENALTY] [--use_transformer]
optional arguments:
-h, --help show this help message and exit
--model_fn MODEL_FN 불러올 Model Filepath.
--gpu_id GPU_ID 학습에 사용할 GPU ID를 입력해주세요. -1 for CPU. Default=-1
--batch_size BATCH_SIZE
batch size. Default=128
--max_length MAX_LENGTH
예측시, 한 문장의 최대 토큰 길이. Default=255
--n_best N_BEST 예측 결과중, 최대 N개까지 Best 예측 선정. Default=1
--beam_size BEAM_SIZE
Batch beam search size. Default=1
--lang LANG 예측할 언어의 쌍 (영어를 한국어로 번역할 경우, ex: en + ko --> enko)
--length_penalty LENGTH_PENALTY
예측 결과의 길이가 긴 만큼 패널티 부여. Default=1.2
--use_transformer Transformer 모델 사용 여부, False일 경우, Seq2Seq.
```
### example command
```bash
>> head -1 ./data/corpus.shuf.test.tok.bpe.en | python translate.py --beam_size 1 --model_fn ./models/model.pth | python detokenizer.py
```
## Samples
| 원문 | 번역문 | Seq2Seq | Transformer |
| ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
| With the exact cause of the accident in limbo, Boeing faced a massive lawsuit. | 정확한 사고원인이 오리무중인 가운데 보잉은 대규모 소송에 직면했다. | 사고 원인이 밝혀진 가운데 보잉은 대규모 소송에 직면했다. | 사고의 정확한 원인을 알 수 없는 상황에서 보잉사는 거대한 소송에 직면했습니다. |
| Many consumers consider buying food directly from abroad, such as health functional foods and diet foods, at an affordable price to celebrate “Black Friday“ (Nov. 23), a U.S. shopping festival. | 미국 쇼핑 축제인 ‘블랙프라이데이’(11월 23일)를 맞아 저렴한 가격에 건강기능식품과 다이어트식품 등 해외직구로 식품 구매를 고려하는 소비자들이 많다. | 많은 소비자들이 미국 쇼핑 페스티벌인 ‘검은 금요일’(11월 23일)을 맞아 저렴한 가격으로 건강기능식품과 다이어트 식품 등 해외에서 직접 먹는 것을 고려하는 소비자들이 많다. | 미국 쇼핑 페스티벌인 ‘블랙프라이데이(11월 23일)’를 맞아 건강기능식품, 다이어트 식품 등 해외직구를 저렴하게 고려하는 소비자들이 많다. |
| The kindergarten's audit report, which participated in the delayed opening of the class and the results of last year's audit, reveals the reason why they are opposed to the strengthening of publicity such as the introduction of Edupine. | 개학 연기에 동참했고 지난해 감사 결과가 공개된 유치원들의 감사보고서를 보면 이들이 에듀파인 도입 등 공공성 강화에 극구 반대하는 이유가 잘 드러난다. | 개강 연기와 지난해 감사 결과에 참여한 유치원 감사보고서에는 에듀파인 도입 등의 공공성 강화에 반대하는 이유가 드러난다. | 개학 연기와 지난해 감사 결과 등에 참여한 유치원 감사보고서에는 에듀파인 도입 등 공공성 강화에 반대하는 이유가 드러나고 있다. |
| These three players are also in good shape and are able to use a variety of tactical skills and are expected to continue to rise in the future. | 이 세 선수 역시 몸상태 최상이고, 다양한 전술 구사 가능하기에 앞으로의 상승세가 계속 이어질 것으로 예상된다. | 이들 세 명의 선수들도 컨디션이 좋고 다양한 전술적 기량을 활용할 수 있고 앞으로도 계속해서 상승세를 이어갈 것으로 예상된다. | 이들 세 선수 역시 컨디션이 좋은데다 다양한 전술적 기량을 구사할 수 있어 앞으로도 계속 상승세를 탈 것으로 예상된다. |
| Local tax refunds are mainly generated for reasons such as refunds following retroactive legislation revisions or refunds of local income taxes based on national tax adjustments, transfers or closures after pre-payment of auto taxes. | 지방세 환급금은 주로 소급입법 개정에 따른 환급이나 국세경정에 따른 지방소득세 환급, 자동차세 선납부 후 이전 또는 폐차 등 사유로 발생된다. | 지방세 환급금은 자동차세 선납 후 국세 조정, 환승 또는 폐원 등에 따른 지방소득세 조정, 지방소득세 환불에 따른 환불 등의 사유로 주로 발생하고 있다. | 지방세 환급은 주로 소급형 법령 개정에 따른 환급이나 자동차세 사전납부 후 국세 조정, 양도, 폐업에 따른 지방세 환급 등의 이유로 발생한다. |
| Will I slice it again? | 제가 그것을 다시 깎아 칠까요? | 제가 다시 좀 깎아볼까요? | 제가 다시 썰어볼까요? |
| It is a book about a life story told by 22 Korean women in their 20s and 70s, who lived in Japan as a minority Koreans living in Japan, from discrimination villages, | 일본에서 마이너리티로 살아온 재일조선인, 피차별부락, 아이누, 오키나와, 베트남, 필리핀 출신의 20대부터 70대 여성 22명이 자신의 가족사진을 바탕으로 들려주는 인생 이야기를 엮은 책이다. | 20∼70대 한국 여성들이 일본에 살고 있는 차별 마을, 애니, 오키나와, 베트남, 필리핀에서 일본에 살고 있는 소수민족으로 일본에 살고 있는 사람들의 인생 이야기를 담은 책이다. | 일본에 거주하는 소수민족으로 일본에 거주하고 있는 20∼70대 한국인 여성 22명이 차별마을 아이누, 오키나와 베트남 필리핀 등에서 들려주는 삶의 이야기를 담은 책이다. |
| Young-joo kept thinking that Hyun-joo was the first person in Hyun-woo's "Time Line" and hoped Hyun-woo would express himself more confidently. | 영주는 자꾸만 현주가 현우 ‘타임라인’의 첫 번째 사람이라 생각하기에 불안한 마음이 있었고 현우가 조금 더 확신을 주는 표현을 해주길 바랐다. | 영주는 현우가 현우의 ‘시간라인’에서 첫 번째 주인공이라는 생각을 가지며 현우가 자신감 있게 표현할 것이라는 생각을 가지고 있었다. | 영주는 계속해서 현주가 현우의 ‘타임 라인’ 첫 번째 사람이라고 생각하고 있었고, 현우가 좀 더 자신감 있게 자신을 표현해주길 바랐다. |
| If the number of validations increases, the time of block creation becomes longer, but the trust in the transaction increases. | 검증횟수가 많아지면 블록생성 시간이 길어지지만, 거래에 대한 신뢰는 높아진다. | 유효기간이 늘면 블록 생성 시기가 길어지지만 거래에 대한 신뢰가 높아진다. | 유효성이 높아지면 블록 생성 시기는 더 길어지지만 거래에 대한 신뢰는 높아진다. |
# Evaluation
### Used Dataset
실습으로 사용된 Dataset은 AI-HUB에서 지원하는[한국어-영어 번역 말뭉치 AI 데이터](https://aihub.or.kr/aidata/87) 입니다. 총 약 160만 개 정도의 한국어-영어 Fair Set을 지원하며, 누구나 무료로 사용할 수 있습니다.
학습을 수행하기 위해서는 해당 데이터에 대한 전처리 과정이 필요합니다. 전처리 과정에 대한 내용은 [여기](https://github.com/iml1111/machine-translation/blob/main/src/data_preparation/README.md)를 참고해주세요.
| set | lang | #lines | #tokens | #characters |
| ----- | ---- | --------- | ---------- | ----------- |
| train | en | 1,200,000 | 43,700,390 | 367,477,362 |
| | ko | 1,200,000 | 39,066,127 | 344,881,403 |
| valid | en | 200,000 | 7,286,230 | 61,262,147 |
| | ko | 200,000 | 6,516,442 | 57,518,240 |
| test | en | 202,409 | 7,348,536 | 60,516,183 |
| | ko | 202,409 | 6,420,128 | 56,697,502 |
### Test Hyperparameter
| parameter | seq2seq | transformer |
| ---------------------------- | ------- | ----------- |
| batch_size | 320 | 4096 |
| word_vec_size | 512 | - |
| hidden_size | 768 | 768 |
| n_layers | 4 | 4 |
| n_splits (transformer heads) | - | 8 |
| n_epochs | 30 | 30 |
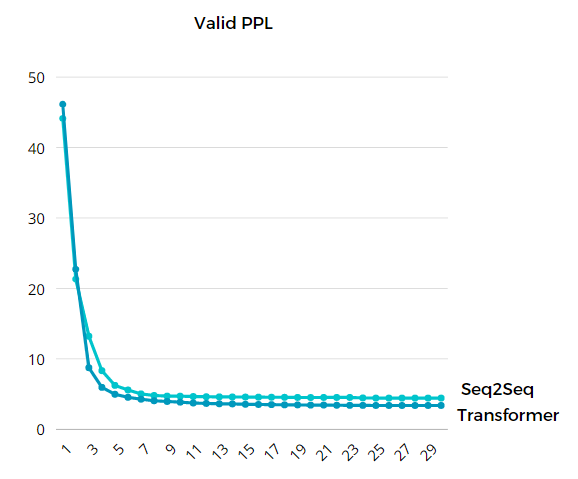
### Loss visualization
| Model | train loss | valid loss | vaild ppl |
| :------------------------------: | :--------: | ---------- | --------- |
| Sequence-to-Sequence (30 epochs) | 1.27 | 1.49 | 4.43 |
| Transformer (30 epochs) | 0.99 | 1.22 | 3.37 |
### BLEU Score Results
| | enko |
| :------------------: | :---: |
| Sequence-to-Sequence | 32.33 |
| Transformer | 34.99 |
# References
- https://github.com/iml1111/pytorch_study
- [LSTM sequence-to-sequence with attention](http://aclweb.org/anthology/D15-1166)
- [Transformer](https://arxiv.org/abs/1706.03762)
- [Pre-Layer Normalized Transformer](https://arxiv.org/abs/2002.04745)
- [Beam search with mini-batch in parallel](https://kh-kim.gitbooks.io/pytorch-natural-language-understanding/content/neural-machine-translation/beam-search.html)
- https://github.com/kh-kim/simple-nmt
- https://github.com/kh-kim/subword-nmt