https://github.com/intellabs/sar
https://github.com/intellabs/sar
Last synced: 10 months ago
JSON representation
- Host: GitHub
- URL: https://github.com/intellabs/sar
- Owner: IntelLabs
- License: mit
- Created: 2022-04-13T21:00:48.000Z (about 4 years ago)
- Default Branch: main
- Last Pushed: 2024-05-31T19:04:59.000Z (about 2 years ago)
- Last Synced: 2025-05-04T06:33:11.804Z (about 1 year ago)
- Language: Python
- Size: 1.43 MB
- Stars: 36
- Watchers: 7
- Forks: 8
- Open Issues: 3
-
Metadata Files:
- Readme: README.md
- License: LICENSE
- Security: security.md
Awesome Lists containing this project
README
# PROJECT NOT UNDER ACTIVE MANAGEMENT #
This project will no longer be maintained by Intel.
Intel has ceased development and contributions including, but not limited to, maintenance, bug fixes, new releases, or updates, to this project.
Intel no longer accepts patches to this project.
If you have an ongoing need to use this project, are interested in independently developing it, or would like to maintain patches for the open source software community, please create your own fork of this project.
[Documentation](https://sar.readthedocs.io/en/latest/) | [Examples](https://github.com/IntelLabs/SAR/tree/main/examples)
SAR is a pure Python library for distributed training of Graph Neural Networks (GNNs) on large graphs. SAR is built on top of PyTorch and DGL and supports distributed full-batch training as well as distributed sampling-based training. SAR is particularly suited for training GNNs on large graphs as the graph is partitioned across the training machines. In full-batch training, SAR can utilize the [sequential aggregation and rematerialization technique](https://proceedings.mlsys.org/paper_files/paper/2022/hash/1d781258d409a6efc66cd1aa14a1681c-Abstract.html) to guarantees linear memory scaling, i.e, the memory needed to store the GNN activiations in each host is guaranteed to go down linearly with the number of hosts, even for densely connected graphs.
SAR requires minimal changes to existing GNN training code. SAR directly uses the graph partitioning data created by [DGL's partitioning tools](https://docs.dgl.ai/en/0.6.x/generated/dgl.distributed.partition.partition_graph.html) and can thus be used as a drop-in replacement for DGL's distributed sampling-based training. To get started using SAR, check out [SAR's documentation](https://sar.readthedocs.io/en/latest/) and the examples under the `examples/` folder.
## Installing required packages
```shell
pip3 install -r requirements.txt
```
Python3.8 or higher is required. You also need to install [torch CCL](https://github.com/intel/torch-ccl) if you want to use Intel's OneCCL communication backend.
## Full-batch training Performance on ogbn-papers100M
SAR consumes up to 2x less memory when training a 3-layer GraphSage network on ogbn-papers100M (111M nodes, 3.2B edges), and up to 4x less memory when training a 3-layer Graph Attention Network (GAT). SAR achieves near linear scaling for the peak memory requirements per machine. We use a 3-layer GraphSage network with hidden layer size of 256, and a 3-layer GAT network with hidden layer size of 128 and 4 attention heads. We use batch normalization between all layers
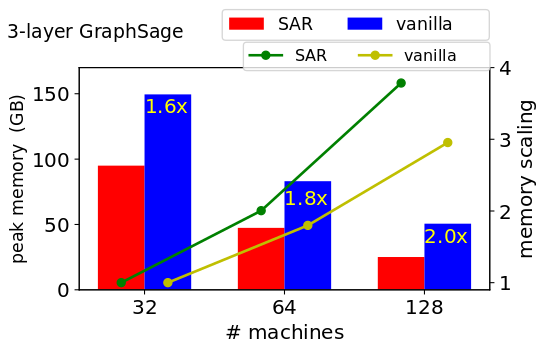
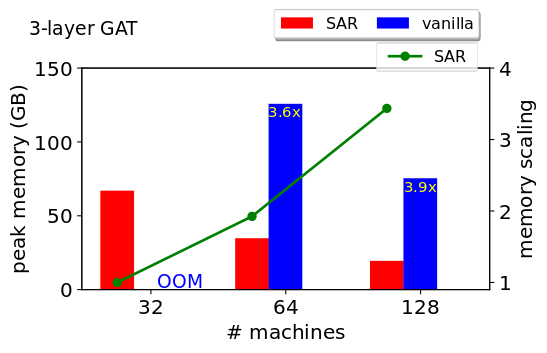
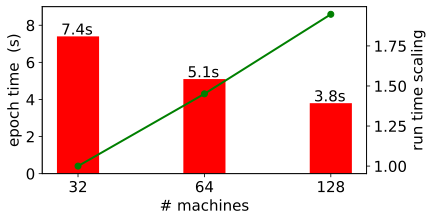
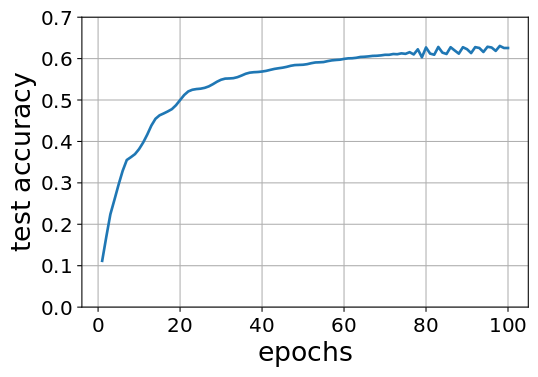
The run-time of SAR improves as we add more machines. At 128 machines, the epoch time is 3.8s. Each machine is a 2-socket machine with 2 Icelake processors (36 cores each). The machines are connected using Infiniband HDR (200 Gbps) links. After 100 epochs, training has converged. We use a 3-layer GraphSage network with hidden layer size of 256 and batch normalization between all layers. The training curve is the same regardless of the number of machines/partition.
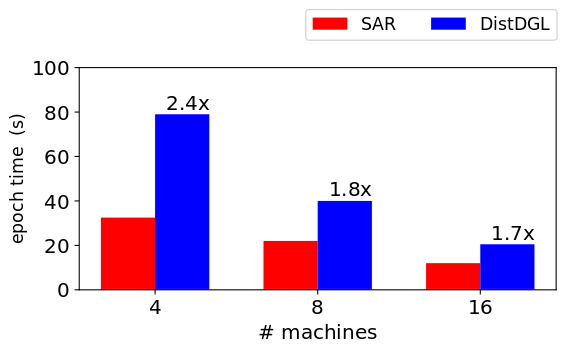
## Sampling-based training Performance on ogbn-papers100M
SAR is considerably faster than DistDGL in sampling-based training on CPUs. Each machine is a 2-socket machine with 2 Icelake processors (36 cores each). The machines are connected using Infiniband HDR (200 Gbps) links. We benchmarked using 3-layer GraphSage network with hidden layer size of 256. We used a batch size of 1000 per machine.
## Cite
If you use SAR in your publication, we would appreciate it if you cite the SAR paper:
```
@article{mostafa2021sequential,
title={Sequential Aggregation and Rematerialization: Distributed Full-batch Training of Graph Neural Networks on Large Graphs},
author={Mostafa, Hesham},
journal={MLSys},
year={2022}
}
```