https://github.com/isaacalves7/python
🐍 It's a repository of Python programming language and his content.
https://github.com/isaacalves7/python
anaconda bottle cherrypy cpython django fastapi flask jupyter kivy lamp pip pypi pypy pyqt5 pyscaffold python3 r-language sqlite-database zeep
Last synced: about 1 year ago
JSON representation
🐍 It's a repository of Python programming language and his content.
- Host: GitHub
- URL: https://github.com/isaacalves7/python
- Owner: IsaacAlves7
- Created: 2020-08-26T21:27:43.000Z (almost 6 years ago)
- Default Branch: master
- Last Pushed: 2025-04-07T12:30:36.000Z (about 1 year ago)
- Last Synced: 2025-05-08T05:44:53.005Z (about 1 year ago)
- Topics: anaconda, bottle, cherrypy, cpython, django, fastapi, flask, jupyter, kivy, lamp, pip, pypi, pypy, pyqt5, pyscaffold, python3, r-language, sqlite-database, zeep
- Language: Python
- Homepage:
- Size: 1.75 MB
- Stars: 1
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
   
   

# It's a repository of Python language 🐍

> 🐍 **Preparação**: Para este conteúdo, o aluno deverá dispor de um computador com acesso à internet, um web browser com suporte a HTML 5 (Google Chrome, Mozilla Firefox, Microsoft Edge, Safari, Opera etc.), um editor de texto ou IDE (VSCode etc.) e o software Python3, com a versão mais recente, instalado na sua máquina local.

- https://exercism.org/tracks/python
- https://app.datacamp.com/learn
# 🐍 The History of Python language

Dentre as diversas linguagens de programação que existem, **Python** é considerada uma das principais. Por sua simplicidade de aprendizado, ela tem sido utilizada em diversos cursos universitários como a primeira linguagem com que os alunos têm contato ao programar. Atualmente, conta com ampla participação da comunidade, além de ter seu desenvolvimento aberto e gerenciado pela organização sem fins lucrativos Python Software Foundation.
Recentemente, a IEEE Computer Society classificou-a como a linguagem mais indicada para aprender em 2020. Isso se deve à sua eficiência no desenvolvimento de machine learning, inteligência artificial, ciência, gestão e análise de dados.
A linguagem Python surgiu em 1989, criado por Guido Van Rossum, nascido em 1956 em Haarlem, Holanda. O desenvolvimento da linguagem foi como um hobby onde a ideia era dar continuidade a linguagem ABC que era desenvolvida no Centro de Pesquisa Holandês (CWI) chamado Centrum Voor Wiskunde en Informatica, em Amsterdã, na Holanda no ano de 1980.
As circunstâncias em que o Python foi criado são um pouco confusas. De acordo com Guido van Rossum: Em Dezembro de 1989, estava à procura de um projeto de programação de "hobby" que me mantivesse ocupado durante a semana por volta do Natal. O meu escritório (...) estaria fechado, mas eu tinha um computador em casa, e não tinha muito mais nas mãos. Decidi escrever um intérprete para a nova linguagem de escrita em que tinha pensado ultimamente: um descendente do ABC que apelaria aos hackers Unix/C. Escolhi Python como título de trabalho para o projeto, estando de humor ligeiramente irreverente (e sendo um grande fã do Monty Python's Flying Circus). - Guido van Rossum
A origem do nome foi inspirado na comédia televisiva inglesa da BBC chamada "Monty Python and the Flying Circus", na década de 1970. A logo de uma serpente da espécie python foi criado pela O'Reilly Media, uma empresa de mídia conhecida por seus livros técnicos na área de Ciência e Tecnologia. A O'Reilly Media usou a imagem de uma serpente em sua capa do livro "Programming Python" de Mark Lutz, que foi lançado em 1996. A capa apresentava uma serpente enroscada, e essa imagem acabou sendo adotada como um símbolo informal para o Python. Então, embora a inspiração para o nome "Python" venha do programa de televisão "Monty Python's Flying Circus", o logo específico da serpente foi popularizado pela O'Reilly Media por meio de sua capa de livro. A serpente passou a ser amplamente reconhecida como o símbolo do Python na comunidade de desenvolvimento de software e após isso foi aderida pelo fundador.
Uma das características espantosas de Python é o fato de ser realmente o trabalho de uma pessoa. Normalmente, novas linguagens de programação são desenvolvidas e publicadas por grandes empresas que empregam muitos profissionais, e devido às regras de direitos de autor, é muito difícil nomear qualquer uma das pessoas envolvidas no projeto. O Python é uma exceção e, portanto, é claro que Guido van Rossum não desenvolveu e evoluiu ele próprio todos os componentes de Python.
A rapidez com que o Python se espalhou pelo mundo é o resultado do trabalho contínuo de milhares (muitas vezes anônimos) de programadores, testadores, utilizadores (muitos deles não são especialistas em IT) e entusiastas, mas deve dizer-se que a primeira ideia (a semente da qual o Python brotou) chegou a uma cabeça - a de Guido.
Em 1999, Guido van Rossum definiu os seus objetivos para o Python, cujo foi influenciada por ABC que era uma linguagem pensada para iniciantes devido a sua facilidade de aprendizado e utilização, são eles:
- Uma **linguagem fácil e intuitiva**, tão poderosa como a dos principais concorrentes;
- Código aberto, **open source**, para que todos possam contribuir;
- Código que seja tão **compreensível e inteligível** como o idioma inglês simples;
- **Adequado a tarefas diárias**, e produtiva, permitindo tempos de desenvolvimento curtos.
> Cerca de 20 anos mais tarde, é evidente que todas estas intenções foram cumpridas. Algumas fontes dizem que o Python é a linguagem de programação mais popular no mundo, enquanto outras afirmam que é a terceira ou a quinta.
Seja como for, continua a ocupar uma posição elevada no top dez do PYPL PopularitY of Programming Language e no TIOBE Programming Community Index.
O Python não é uma linguagem jovem. É **madura** e **confiável**. Não é uma *one-hit wonder*. É uma estrela brilhante no firmamento da programação, e o tempo gasto a aprender Python é um investimento muito bom.
Como é que os programadores, jovens e velhos, experientes e novatos, querem utilizá-lo? Como aconteceu que grandes empresas adotassem o Python e implementassem os seus principais produtos utilizando-o?
Há muitas razões - já enumerámos algumas delas, mas vamos enumerá-las novamente de uma forma mais prática:
- **é fácil de aprender** - o tempo necessário para aprender Python é menor do que para muitas outras linguagens; isto significa que é possível iniciar a programação em si mais rapidamente;
- **é fácil de ensinar** - a carga de trabalho de ensino é menor do que a necessária para outras linguagens; isto significa que o professor pode colocar mais ênfase em técnicas de programação gerais (independentes da linguagem), não desperdiçando energia em truques exóticos, estranhas exceções e regras incompreensíveis;
- é **fácil de usar** para escrever novo software - é muitas vezes possível escrever código mais rapidamente quando se usa Python;
- é **fácil de compreender** - é também frequentemente mais fácil e rápido de compreender o código de outra pessoa se for escrito em Python;
- é **fácil de obter, instalar e implementar** - o Python é gratuito, aberto e multiplataforma; nem todas as linguagens se podem gabar disso.
> O Python é uma linguagem de programação com extenso uso, com uma grande comunidade de contribuintes e com extensa disponibilidade de artigos, informações e bibliotecas.
É claro que o Python também tem os seus inconvenientes (ninguém é perfeito hehe):
- **não tem um super-poder da velocidade** - o Python não oferece um desempenho excecional;
- em alguns casos pode ser resistente a algumas técnicas de teste mais simples - isto pode significar que **depurar (debuggar) o código Python pode ser mais difícil do que com outras linguagens**; felizmente, cometer erros é sempre mais difícil em Python.
Apesar da popularidade crescente de Python, ainda existem alguns nichos onde o Python está ausente, ou raramente é visto:
- **programação de baixo nível** (por vezes chamada programação "close to metal"): se quiser implementar um condutor ou motor gráfico extremamente eficaz, não utilizaria Python;
- **aplicações para dispositivos móveis**: existe pouca área de atuação para o Python nessa área, fortalecendo assim algumas das linguagens concorrentes.
Deve também ser afirmado que o Python não é a única solução do seu gênero disponível no mercado do TI. Tem muitos seguidores, mas há muitos que preferem outras linguagens e nem sequer consideram o Python para os seus projetos.
No início dos anos 1990 e desde então tem aumentado sua participação no mundo da programação. Permite uma programação fácil e clara para escalas pequenas e grandes, além de enfatizar a legibilidade eficiente do código, notadamente usando espaços em branco significativos.
Dentre as diversas linguagens de programação que existem, **Python** é considerada uma das principais. Por sua simplicidade de aprendizado, ela tem sido utilizada em diversos cursos universitários como a primeira linguagem com que os alunos têm contato ao programar. Atualmente, conta com ampla participação da comunidade, além de ter seu desenvolvimento aberto e gerenciado pela organização sem fins lucrativos Python Software Foundation.
Recentemente, a _IEEE Computer Society_ classificou-a como a linguagem mais indicada para aprender em 2020. Isso se deve à sua eficiência no desenvolvimento de **machine learning**, **inteligência artificial**, **ciência**, **gestão** e **análise de dados**.
**Python** é uma linguagem de programação de alto nível, que permite ao programador utilizar instruções de forma intuitiva, tornando seu aprendizado mais simples do que o aprendizado de uma linguagem de baixo nível.
Nas linguagens de baixo nível, o programador precisa se expressar de forma muito mais próxima do que o dispositivo “entende”, levando naturalmente a um distanciamento da linguagem utilizada para comunicação entre duas pessoas.
A classificação das linguagens em paradigmas permite que entendamos qual é o melhor deles para solucionar determinado problema e, a partir daí, escolher a linguagem de programação (pertencente a esse paradigma) mais adequada, conforme características e especificidades do contexto em que se aplica o problema.
A linguagem Python foi escolhida como instrumento para o desenvolvimento desta disciplina, pois além de ser multiparadigma (possibilita escrever programas em diferentes paradigmas) e de uso geral, vem se destacando e sendo cada vez mais utilizada entre os novos desenvolvedores por vários motivos:
- Facilidade de aprendizado;
- Boa legibilidade de código;
- Boa facilidade de escrita;
- Produtividade e confiabilidade.
- Possui, ainda, comunidade de desenvolvedores crescente e vasta biblioteca, repleta de funções, aplicada a diversas áreas da ciência, assim como o crescente números de frameworks desenvolvidos para a linguagem.
O Python é uma linguagem de programação dinâmica de alta produtividade amplamente usada em aplicativos de ciência, engenharia e análise de dados.
Há uma série de fatores que influenciam a popularidade do Python, incluindo sua sintaxe limpa e expressiva, estruturas de dados padrão, biblioteca padrão abrangente, "baterias incluídas", documentação excelente, amplo ecossistema de bibliotecas e ferramentas, disponibilidade de suporte profissional e uma grande e aberta comunidade.
> Talvez o mais importante, porém, seja a alta produtividade que uma linguagem interpretada e digitada dinamicamente como o Python permite. Python é ágil e flexível, o que o torna uma ótima linguagem para prototipagem rápida, mas também para construir sistemas completos.
A linguagem **Python** é uma linguagem de programação, com características interessantes:
- É **interpretada** e **compilada**, ou seja, o interpretador Python executa o código fonte diretamente, traduzindo cada trecho para instruções de máquina;
- É de **alto nível**, ou seja, o interpretador se vira com detalhes técnicos do computador. Assim, desenvolver um código mais simples do que em linguagem de baixo nível, nas quais o programador deve se preocupar com detalhes da máquina;
- É de propósito geral, ou seja, podemos usar Python para desenvolver programas em diversas áreas. Ao contrário de linguagens de domínio específico, que são especializados e atendem somente a uma aplicação específica;
- Tem **tipos dinâmicos**, ou seja, o interpretador faz a magia de descobrir o que é cada variável;
- É **multiparadigma**, apesar de suportar perfeitamente o paradigma de programação estruturada, Python também suporta programação orientada a objetos, tem características do paradigma funcional, com o amplo uso de bibliotecas, assim como permite recursividade e uso de funções anônimas.
- É **interativa**, permite que os usuários interajam com o interpretador Python diretamente para escrever os programas, utilizando o prompt interativo. Esse prompt fornece mensagens detalhadas para qualquer tipo de erro ou para qualquer comando específico em execução, suporta testes interativos e depuração de trechos de código.
- É **híbrida** quanto ao método de implementação. Python usa uma abordagem mista para explorar as vantagens do interpretador e do compilador. Assim como Java, utiliza o conceito de máquina virtual (PVM - Python Virtual Machine), permitindo a geração de um código intermediário, mais fácil de ser interpretado, mas que não é vinculado definitivamente a nenhum sistema operacional.
- É **portável**, tem a capacidade de rodar em uma grande variedade de plataformas de hardware com a mesma interface. Ele roda perfeitamente em quase todos os sistemas operacionais, como **Windows**, **Linux**, **UNIX**, e **macOS**, sem nenhuma alteração.
- É **extensível**, permite que os programadores adicionem ou criem módulos e pacotes de baixo nível / alto nível ao interpretador Python. Esses módulos e pacotes de ferramentas permitem que os desenvolvedores tenham possibilidades amplas de colaboração, contribuindo para a popularidade da linguagem.
- **Suporta bancos de dados**, por ser uma linguagem de programação de uso geral, Python suporta os principais sistemas de bancos de dados. Permite escrever código com integração com **MySQL**, **PostgreSQL**, **SQLite**, **ElephantSQL**, **MongoDB**, entre outros.
- **Suporta interface com usuário**, permite escrever código de tal maneira que uma interface do usuário para um aplicativo possa ser facilmente criada, importando bibliotecas como Tkinter, Flexx, CEF Python, Dabo, Pyforms ou PyGUI wxPython, PyQT, Kivy.
- Pode ser usado como **linguagem de script**. Permite fácil acesso a outros programas, podendo ser compilado para **bytecode** a fim de criar aplicativos grandes.
- Permite **desenvolvimento de aplicações Web**. Devido à escalabilidade já citada, Python oferece uma variedade de opções para o desenvolvimento de aplicativos Web. A biblioteca padrão do Python incorpora muitos protocolos para o desenvolvimento da web, como **HTML**, **XML**, **JSON**, **processamento de e-mail**, além de fornecer base para **FTP**, **IMAP** e outros **protocolos da Internet**.
- Permite criação de **aplicações comerciais**. É desenvolvido sob uma licença de código aberto aprovada pela **OSI**, tornando-o livremente utilizável e distribuível, mesmo para uso comercial.
> **Atenção**: Mas a maior força do Python também pode ser sua maior fraqueza: sua flexibilidade e sintaxe de alto nível sem tipo podem resultar em baixo desempenho para programas com uso intensivo de dados e computação. Por esse motivo, os programadores Python preocupados com a eficiência geralmente reescrevem seus loops mais internos em C e chamam as funções C compiladas do Python.
Existem vários projetos que visam tornar essa otimização mais fácil, como o **Cython**, mas geralmente exigem o aprendizado de uma nova sintaxe. Idealmente, os programadores Python gostariam de tornar seu código Python existente mais rápido sem usar outra linguagem de programação e, naturalmente, muitos gostariam de usar aceleradores para obter um desempenho ainda maior de seu código.
Resumindo as características do Python:
- Orientada a objetos com uma semântica dinâmica;
- Possui licença compatível com Software livre;
- Linguagem de altíssimo nível (VHLL);
- Tipagem dinâmica e forte;
- Aumenta a produtividade do desenvolvedor;
- A implementação padrão e oficial de referência do Python que é mantida pela PSF (Python Software Foundation) e é escrita em linguagem C, e por isso, é também conhecida como CPython;
- Multiplataforma e multiparadigma (POO, funcional e procedural);
- Batteries Included: é uma biblioteca padrão rica e versátil que está imediatamente disponível, sem que o usuário baixe pacotes separados. Isso dá à linguagem Python uma vantagem inicial em muitos projetos.;
- Organizada;
- Comunidade gigante e ativa;
- Curva de aprendizado baixa;
- Muitas Bibliotecas.
Por essas e várias outras características, o Python se torna uma linguagem simples, bela, legível e amigável. É uma linguagem muito utilizada por diversas empresas como Wikipédia, Microsoft, Google, Yahoo!, CERN, NASA, Facebook, AMAZON, Instagram, Spotify, Bitorrent Inc, Django e Dropbox.
 
O Python tem dois concorrentes diretos, com propriedades e predisposições comparáveis. Estes são:
- **Perl** - uma linguagem de scripting originalmente de autoria de Larry Wall;
- **Ruby** - uma linguagem de scripting originalmente escrita por Yukihiro Matsumoto.
A primeira é mais tradicional, mais conservadora do que Python, e assemelha-se a algumas das boas e antigas linguagens derivadas da clássica linguagem de programação C.
Em contraste, esta última é mais inovadora e mais cheia de ideias frescas do que Python. O próprio Python encontra-se algures entre estas duas criações.
A Internet está cheia de fóruns com infinitas discussões sobre a superioridade de um destes três sobre os outros, caso pretenda saber mais sobre cada um deles.
Vemo-lo todos os dias e em quase todo o lado. É utilizado extensivamente para implementar **serviços complexos da Internet** como motores de busca, armazenamento em nuvem e ferramentas, redes sociais, etc. Sempre que utiliza qualquer um destes serviços, está na realidade muito próximo de Python, embora não o conheça.
Muitas ferramentas em desenvolvimento são implementadas em Python. Cada vez mais aplicações de uso diário estão a ser escritas em Python. Muitos cientistas abandonaram ferramentas proprietárias dispendiosas e mudaram para o Python. Muitos testadores de projetos de TI começaram a utilizar o Python para realizar procedimentos de teste repetíveis. A lista é longa:

- IA - Inteligência Artificial
- Machine Learning
- Deep Learning
- IoT - Internet das Coisas
- Big Data
- Data Analysis
- Data Science
- Computação 3D
- Biotecnologia
- Bioinformática
- Web Development (Back-end)
- Cybersecurity
- Game Development
- Mobile Development
- Desktop Development
- DevSecOps
- QA - Quality Assurance
- Automação de Sistemas
- Cloud Computing
- Estudos científicos como: Engenharia, Geologia, Astronomia, Física, Química, Matemática e etc
Certificações em Python:

- https://pythoninstitute.org/pcep
- https://pythoninstitute.org/pcap
- https://pythoninstitute.org/
Ao começar sua jornada como programador, é importante perceber que existem algumas práticas que não são obrigatórias, mas podem ajudar muito no seu aprendizado. Além disso, podem permitir que você corrija mais rapidamente erros que podem surgir no futuro e tornam seu código mais fácil de ser compreendido por outro programador, favorecendo o trabalho em equipe. Vamos conhecer algumas delas:
- Uma prática muito importante é utilizar comentários no seu programa, explicando o que aquele trecho resolve.
- Uma característica marcante da comunidade de desenvolvedores Python é manter uma lista de propostas de melhorias, chamadas **PEP** (Python Enhancement Proposals). Dentre as PEPs, destaca-se a **PEP8**, que estabelece um guia de estilo de programação.
Existem dois tipos principais de Python, chamados **Python 2** e **Python 3**. O Python 2 é uma versão mais antiga do Python original. Desde então o seu desenvolvimento tem sido intencionalmente parado, embora isso não signifique que não hajam atualizações. Pelo contrário, as atualizações são emitidas regularmente, mas não se destinam a modificar a linguagem de forma significativa. Preferem corrigir quaisquer bugs recém-descobertos e falhas de segurança. O caminho de desenvolvimento de Python 2 já chegou a um beco sem saída, mas o Python 2 em si ainda está muito vivo, presente principalmente em sistemas operacionais Linux e macOS.
Em 2008, é lançada a versão 3.0, que resolveu muitos problemas de design da linguagem e melhorou a performance. Algumas mudanças foram muito profundas dessa forma a versão 3.x não é retrocompatível.
O Python 3 é a versão mais recente (para ser mais preciso, a atual versão) da linguagem. Está a percorrer o seu próprio caminho de evolução, criando os seus próprios padrões e hábitos. Atualmente, estamos na versão 3.10.8 do Python.
Estas duas versões do Python não são compatíveis uma com a outra. Os **scripts** (Arquivos de texto que contém instruções que constituem um programa de Python) de Python 2 não serão executados num ambiente Python 3 e vice-versa, portanto, se quiser que o antigo código Python 2 seja executado por um interpretador Python 3, a única solução possível é reescrevê-lo, não do zero, claro, pois grandes partes do código podem permanecer intocadas, mas terá de rever todo o código para encontrar todas as incompatibilidades possíveis. Infelizmente, este processo não pode ser totalmente automatizado.
É demasiado difícil, demasiado demorado, demasiado caro e demasiado arriscado migrar uma velha aplicação Python 2 para uma nova plataforma. É possível que a reescrita do código lhe introduza novos bugs. É mais fácil e mais sensato deixar estes sistemas em paz e melhorar o intérprete existente, em vez de tentar trabalhar dentro do source code já em funcionamento.
O Python 3 não é apenas uma versão melhor do Python 2 - é uma linguagem completamente diferente, embora seja muito semelhante à sua predecessora. Quando se olha para eles à distância, parecem ser os mesmos, mas quando se olha de perto, no entanto, notam-se muitas diferenças.
Se estiver a modificar uma antiga solução Python existente, então é altamente provável que tenha sido codificada em Python 2. Esta é a razão pela qual o Python 2 ainda está a ser utilizado. Há demasiadas aplicações Python 2 existentes para o descartar completamente.
> **Nota**: Se vai iniciar um novo projeto Python, deve usar Python 3.
É importante lembrar que pode haver diferenças menores ou maiores entre as versões posteriores do Python 3 (por exemplo, Python 3.6 introduziu chaves de dicionário ordenadas por defeito sob a implementação do CPython) - a boa notícia, porém, é que todas as versões mais recentes de Python 3 são retrocompatíveis com as versões anteriores de Python 3. Sempre que for significativo e importante, tentaremos realçar essas diferenças.
> Todas as amostras de código que irá encontrar aqui foram testadas com Python 3.4, Python 3.6, Python 3.7, e Python 3.8.
## [Python] RAD - Rapid Applications Development
O **RAD - Rapid Applications Development** trata-se de uma abordagem interativa com o objetivo de produzir o desenvolvimento de software de alta qualidade e trabalho com foco na entrega de aplicações em um período muito inferior ao ciclo de desenvolvimento tradicional de software. Para atingir essa meta, ela trabalha com o ciclo curto baseado em iterações e incrementos que no final de cada ciclo é feito a entrega de um protótipo do usuário que desse modo pode interagir com a aplicação funcional e, assim, fazer críticas e sugestões (feedbacks) que serão úteis para os desenvolvedores aperfeiçoarem a implementação do sistema.
A RAD se diferencia em relação as metodologias tradicionais de desenvolvimento sob vários aspectos, o primeiro sendo sobre o processo de desenvolvimento de software que na RAD segue o modelo iterativo e incremental, na metodologia tradicional de desenvolvimento de software ele seguiria o fluxo linear de desenvolvimento, segunda estrutura seria da estrutura da equipe que na RAD as equipes são pequenas e possuem múltiplas habilidades, no método tradicional tem grandes equipes com funções e habilidades bem definidas, em relação a produtividade, na RAD a produtividade é alta devido aos processos iterativos com os usuários finais, já no desenvolvimento tradicional a produtividade é baixa devido a abordagem linear e rígida, na parte de documentação na RAD é mínima viável, já na prática tradicional a documentação é detalhada e rigorosa com cada estágio de desenvolvimento, em relação ao tempo estimativo de custo, na RAD os projetos são de curta duração e baixo custo de manutenção, na metodologia tradicional o ciclo de vida é longo e com chance de aumento extra com os custos de retrabalho e manutenção. Em relação com a interação do usuário final, na RAD essa interação é ampla e ela ocorre no final de cada iteração, no desenvolvimento tradicional o envolvimento do usuário é somente no início do processo e no final quando ocorre a entrega do sistema. Em relação aos elementos predefinidos na Rad ela trabalha fortemente com essa questão utilizando aplicativos, layouts e modelos que já vem prontos ou pelo menos uma parte pronta, já no desenvolvimento tradicional é necessário desenvolver esses componentes específicos para o projeto com baixa reusabilidade.
Então, o projeto é desenvolvido em etapas e com a inclusão de novas funcionalidades e o resultado da aplicação da RAD é um software com menor custo, menos erros e menor tempo de desenvolvimento. A colaboração entre usuários e desenvolvedores ao longo do projeto é uma característica fundamental da RAD. O projeto é desenvolvido com interações e incrementos de funcionalidades. A operação dessa metodologia pode ocorrer em fases, ou de modo intensivo.
> A RAD pode ser considerada um tipo de técnica ágil. (NAZ & KHAN, 2015).
O desenvolvimento de software tem como objetivo atender as demandas da sociedade, cada vez mais complexas e com abrangência em diversas áreas. Logo nos primórdios da indústria de software, aplicavam-se metodologias que seguiam etapas que não eram revistas e, no final dos projetos, muitas vezes, desenvolvedores e clientes ficavam frustrados com o resultado obtido. Nesse sentido, a necessidade de criar formas mais eficazes de desenvolver sistemas levou à criação da metodologia rápida de desenvolvimento de software, mais conhecida pela sigla em inglês: RAD (Rapid Application Development). Baseia-se na entrega de protótipos para os clientes, a fim de que possam ter uma noção mais clara do progresso do desenvolvimento do software e que também possam colaborar com comentários que permitam aos desenvolvedores fazer alterações para atender as expectativas do cliente.
O desenvolvimento rápido de aplicações RAD (Rapid Application Development) é uma metodologia de desenvolvimento de software com foco na entrega em um período muito inferior ao do ciclo de desenvolvimento tradicional de software. Não se trata de uma entrega final, mas, sim, de um **protótipo do software**. Para que isso seja possível, é feito um planejamento mínimo para obter um protótipo rápido.
> Um protótipo de software é um modelo funcional que equivale funcionalmente a um componente do produto. Ou seja, simula apenas alguns aspectos do produto e é útil para o entendimento e a evolução do sistema final. Na metodologia RAD, existe uma concentração no desenvolvimento dos principais módulos funcionais do sistema. Essa versão inicial, que, apesar de limitada, já é funcional, é chamada de protótipo.
Na metodologia RAD, existe uma concentração no desenvolvimento dos principais módulos funcionais do sistema. Essa versão inicial, que, apesar de limitada, já é funcional, é chamada de **protótipo**:
- É muito útil para a compreensão do sistema
- Serve de demonstração para os clientes
- É mais flexível para mudanças
- Quando está mais evoluído, pode ser integrado ao produto completo para uma entrega mais rápida da versão final
A RAD também pode ser aplicada para aperfeiçoar o treinamento prático de estudantes de computação, auxiliando-os em seus futuros empregos. Isso porque os estudantes podem aplicar o conhecimento adquirido nas aulas para desenvolver sistemas em etapas, conforme é proposto pela RAD. Como será mostrado mais adiante, o fator humano é um importante requisito para a aplicação dessa metodologia, então a sua aplicação para treinar recursos humanos pode acelerar a curva de aprendizado dentro de um curto período.
Os projetos RAD seguem o **modelo iterativo e incremental**. As equipes de desenvolvimento são pequenas, compostas por desenvolvedores, analistas de negócio e representantes de clientes. Um dos aspectos mais importantes deste modelo é garantir que os protótipos desenvolvidos sejam reutilizáveis para o projeto do sistema, ou seja, a ideia não é criar unidades descartáveis. Isso não contradiz o fato de o protótipo ser flexível.
> O desenvolvimento iterativo promove progressos sucessivos, em que o produto é refinado por etapas. No modelo incremental, o software é entregue em pedaços, que são chamados de incrementos. A ideia é que o software seja criado em ciclos curtos, com introdução de funcionalidades, coleta de feedback e revisão.
> O RAD foca no desenvolvimento rápido por meio de iterações frequentes e feedback contínuo.
O modelo RAD foi introduzido pelo consultor de tecnologia e autor James Martin em 1991 (MARTIN, 1991). Surgiu como o reconhecimento da necessidade de atender o competitivo mercado de software, que tem uma demanda contínua por novas aplicações. Uma característica que foi explorada para a formalização da RAD foi a flexibilidade do desenvolvimento de software para projetar modelos de desenvolvimento. Trata-se de uma combinação de sessões JAD, desenvolvimento de protótipos, equipes SWAT, entregas com prazo de entrega e ferramentas CASE.
Portanto, o RAD:
- É muito prática em diversos ambientes modernos de desenvolvimento.
- Apresenta uma abordagem útil para criar aplicações de comércio eletrônico e aplicativos de dispositivos móveis.
- Possui uma velocidade de entrega que pode determinar o posicionamento de uma empresa em um ambiente de mercado muito competitivo.
Portanto, trata-se de uma metodologia importante a ser empregada para que as empresas lancem suas aplicações antes de seus concorrentes.
Observe no fluxo como iniciar um projeto RAD:
1. Uma das formas de iniciar o projeto RAD é através da aplicação da metodologia Joint Application Development (JAD).
> A **Joint Application Development (JAD)** é uma metodologia de desenvolvimento que tem como objetivo melhorar o entendimento do sistema ainda no início do projeto onde a principal característica da metodologia JAD são as oficinas de trabalho, em que desenvolvedores e usuários interagem e colaboram para o entendimento dos requisitos do sistema.
2. Trata-se de uma metodologia na qual usuários e analistas projetam o sistema juntos, sob uma liderança em oficinas de trabalho.
3. A ideia é potencializar o resultado do desenvolvimento através de dinâmicas de grupo.
4. Ou seja, definir os objetivos e as aplicações do sistema, desde a geração de telas até a geração de relatórios.
Tem como princípios: dinâmica de grupo; recursos audiovisuais; processo organizado e racional; a escolha do local; documentação com a abordagem WYSIWIG – “O que você vê é o que você obtém”.
A RAD foi a precursora do gerenciamento ágil de projetos. As características de prototipagem rápida e ciclos de liberação e iterações mais curtos fortaleceram o posicionamento da RAD como um método eficaz no desenvolvimento de software, tornando-se cada vez mais popular entre as empresas ágeis que procuram métodos que acompanhem o crescimento de suas necessidades comerciais e de clientes. Trata-se de uma metodologia orientada pelo feedback do usuário, e não por um planejamento detalhado e caro.
Os métodos tradicionais de desenvolvimento de software, como, por exemplo, a metodologia de desenvolvimento **cascata** (waterfall), seguem modelos rígidos de processo. Isso significa que, nesses modelos tradicionais, os clientes são pressionados a estabelecer os requisitos antes do início do projeto. A iteração ao longo do projeto é baixa, o que complica o processo de mudança para novos requisitos e ajustes de viabilidade.
A metodologia RAD combina diversas técnicas para acelerar o desenvolvimento de aplicações de software. Outra forma pela qual a RAD é conhecida é como “Construção Rápida de Aplicações”, do inglês Rapid Application Building (RAB). Um dos principais elementos da RAD é o desenvolvimento de protótipos para chegar ao sistema final. Trata-se de um modelo adaptativo, uma vez que o desenvolvimento é feito em iterações em que mudanças podem ser realizadas a partir dos comentários do usuário. A ênfase está na criação rápida de um protótipo, em vez de um planejamento detalhado.
A metodologia RAD possui quatro elementos fundamentais:
- USO DE FERRAMENTAS PARA DAR SUPORTE AO DESENVOLVIMENTO: O uso de ferramentas CASE facilita a automação no desenvolvimento de sistemas. Isso é obtido através de recursos como geração de código e verificação automática de erros de consistência. As ferramentas CASE, portanto, são usadas para gerar protótipos, dando, assim, suporte ao desenvolvimento iterativo, possibilitando que os usuários finais acompanhem a evolução do sistema à medida que ele está sendo construído.
- METODOLOGIA BEM DEFINIDA: É seguido um processo formal de desenvolvimento com atividades em etapas e entregas intermediárias. As tarefas são organizadas de modo a não negligenciar nenhum dos aspectos pré-acordados, e as técnicas são documentadas para garantir que uma tarefa seja executada da maneira correta.
- PESSOAS: Deve haver treinamento das pessoas tanto na metodologia de trabalho como no uso das ferramentas. As tarefas devem ser distribuídas por pequenas equipes, que devem trabalhar bem juntas.
- GESTÃO: O gerenciamento do projeto deve ser feito com rapidez. Isso é obtido através de oficinas de Planejamento de Requisitos e Design de Sistema para extrair rapidamente os requisitos dos usuários. Além disso, deve ser feita alocação de tempo fixo (**Timebox**) para entregar iterativamente o sistema para os usuários.
> Timebox é o tempo máximo estabelecido para atingir as metas, tomar uma decisão ou executar um conjunto de tarefas.
Além disso, existem dois tipos de projetos RAD:
- **Intensivo**: No tipo de projeto intensivo, uma equipe de desenvolvedores e usuários trabalham por um curto período (algumas semanas) e, ao final desse tempo, espera-se que produza um produto que seja utilizável.
- **Faseado**: Um projeto em fases é aquele distribuído por um longo período. Esses projetos são normalmente iniciados por um workshop JAD. As fases subsequentes do projeto são geralmente organizadas em termos de entrega e demonstração de protótipos incrementais. O objetivo é refinar continuamente o protótipo, tornando-o algo que seja entregue no final do timebox.
Como visto até aqui, está claro que a criação rápida de protótipo é a base da RAD. Nas situações em que os projetos são orientados por requisitos de interface do usuário, o desenvolvimento de protótipo é uma escolha muito adequada, pois é normal que o usuário crie a ideia de como a interface do sistema deve ficar ao longo do desenvolvimento do projeto. O desenvolvimento rápido de protótipos tem como pré-requisito o uso de ferramentas com suporte a componentes gráficos. No mercado, desde a década de 1990, existiam diversas ferramentas para esse fim, em que os programadores simplesmente podem selecionar um componente gráfico e arrastá-lo para um formulário. Desse modo, as interações com os usuários finais são mais produtivas, pois, constantemente, recebem um software operacional.
Constantemente, os programadores são pressionados a entregar as aplicações em prazos curtos e, muitas vezes, sabe-se com antecedência que o projeto terá de passar por modificações ao longo do desenvolvimento. Essas situações são exemplos em que o desenvolvimento rápido é bastante útil, pois ele está embasado exatamente na entrega rápida de protótipos que incorporam os comentários e as solicitações dos usuários a cada entrega. Para ser eficaz, no entanto, a RAD tem alguns requisitos que não são triviais. Alguns requisitos relacionados aos recursos humanos são os seguintes:
- Equipe de desenvolvedores qualificada e motivada.
- Usuários comprometidos com a participação ativa ao longo do projeto.
- Comprometimento para atingir o resultado satisfatório.
O desenvolvimento baseado na entrega de protótipos funcionais busca dar a oportunidade para que o usuário possa interagir com o projeto antes de receber o sistema final. Dessa forma, poderá fazer comentários e solicitações que guiarão os desenvolvedores na confecção do produto que atenda às suas expectativas sob o ponto de vista de funcionalidades, recursos, interatividade do sistema (experiência do usuário), relatórios, gráficos, entre outros.
O RAD é baseado em alguns princípios básicos, que são (FITZGERALD, 1998):
- ENVOLVIMENTO ATIVO DOS USUÁRIOS: A metodologia RAD reconhece que o envolvimento do usuário é necessário para reduzir problemas caros de obtenção de requisitos. Além disso, os usuários podem rejeitar completamente os sistemas, se não estiverem suficientemente envolvidos no desenvolvimento. No centro da abordagem da RAD, estão as oficinas de design de aplicativos conjuntos (JAD) e planejamento de requisitos conjuntos.
- EQUIPES PEQUENAS COM PODER DE DECISÃO: As vantagens da elaboração de equipes pequenas estão na redução de ruídos de comunicação e na minimização de atrasos devido à burocracia que a hierarquia de uma metodologia tradicional impõe. Em relação aos ruídos de comunicação, os canais que tratam dessa área aumentam proporcionalmente ao tamanho da equipe, portanto equipes pequenas evitam a distorção e o conflito na comunicação. A respeito da redução do tempo, empoderar a equipe aumenta as chances de cumprir os prazos por causa da responsabilidade de tomada de decisão. As equipes têm o poder de tomar decisões sobre o design (embora as mudanças sejam reversíveis).
- ENTREGA FREQUENTE DE PRODUTOS: Diferentemente das metodologias de desenvolvimento tradicionais, em que os projetos podem levar muito tempo para serem concluídos, a RAD procura reduzir o tempo de desenvolvimento. Portanto, prazos mais curtos para o desenvolvimento são uma característica importante. Em vez de se concentrar no processo, a RAD tem como premissa a entrega de produtos que satisfazem os requisitos funcionais.
- DESENVOLVIMENTO INCREMENTAL E ITERATIVO: Outro princípio fundamental do RAD é que os sistemas evoluem de forma incremental em cada iteração. A cada nova iteração, surgem novos requisitos que são incorporados ao sistema. Desse modo, os sistemas evoluem através da prototipagem iterativa. Existe um entendimento no RAD que a especificação de requisitos é um processo não determinístico e que evolui à medida que desenvolvedores e usuários interagem com o protótipo do sistema.
- ABORDAGEM TOP-DOWN: Uma vez que, na metodologia RAD, os requisitos não precisam ser completamente definidos logo no início do projeto, eles são especificados em um nível apropriado ao conhecimento disponível no momento. Estes são então elaborados através de prototipagem incremental. Os sistemas são elaborados e confeccionados à medida que o conhecimento cresce. Além disso, como se trata de uma abordagem de “cima para baixo” caracterizada por um curto período, todas as decisões são consideradas reversíveis rapidamente.
- UTILIZAÇÃO DE FERRAMENTAS DE AUTOMAÇÃO (CASE): Trata-se de usar programas que facilitem a automação de processos, criação de diagramas, realização de testes e quaisquer tarefas que facilitem as entregas dentro dos prazos pré-estabelecidos e, obviamente, com qualidade. Além disso, essas ferramentas facilitam a reutilização de componentes que podem ser usados ao longo do projeto.
O ponto fundamental na metodologia RAD é que se trata de uma abordagem colaborativa entre todas as partes interessadas, que são: patrocinadores, desenvolvedores e usuários ao longo da vida de um projeto.
A RAD precisa ser suportada por ferramentas que auxiliem no desenvolvimento das aplicações rapidamente. Entre as categorias de ferramentas que dão suporte à RAD para desenvolver projetos de software estão:
- Integração de dados
- Ambientes de desenvolvimento
- Ferramentas de coleta de requisitos
- Ferramentas de modelagem de dados
- Ferramentas de geração de código
Desde que a RAD foi formalizada, foram desenvolvidas muitas técnicas para a sua utilização. Cada uma das técnicas tem suas particularidades, mas mantém a essência da RAD. No quadro a seguir, conheça algumas dessas técnicas (Naz; Khan, 2015):
TÉCNICA
PARTICULARIDADE
Modelo CBD
O método que descreve como componentes antigos podem ser reutilizados com os novos.
RepoGuard
É um framework para integração de ferramentas de desenvolvimento com repositórios de código-fonte.
Adição dinâmica ágil
Técnicas usadas para integração do ágil para tornar o projeto mais adaptável.
Método baseado em camadas para desenvolvimento rápido de software
Baseado em camadas que segue o XP.
Análise de projeto de sistema baseado em simulação
Desenvolvimento de ferramentas ágeis baseadas em simulação.
Uso de Ajax no RAD
Prototipagem rápida em aplicativos e ferramentas da Web.
Desenvolvimento de aplicativos multiusuário em ambiente distribuído rapidamente.
Middleware de comunicação.
Programação extrema
Adição de reutilização ao XP.
> **XP**: Extreme Programming (XP) consiste em uma metodologia de desenvolvimento de software que tem como objetivo maximizar a qualidade do software e responder mais rapidamente às mudanças nos requisitos do cliente.
A ideia do uso das técnicas de RAD é de otimizar os resultados obtidos dentro do tempo estimado, que, pela natureza da RAD, é curto. Essencialmente, um software é construído para atender a alguma demanda, ou seja, existe uma razão para que seja confeccionado. Portanto, a interação com os usuários (através das métricas e insights) auxilia o entendimento dos desenvolvedores para construir, agregar e incorporar esse entendimento em um protótipo através de técnicas e ferramentas **que acelerem a entrega e reduzam os desvios de compreensão**. A concordância sobre o propósito do sistema e a sua evolução é muito importante para o sucesso do projeto. Tanto desenvolvedores como clientes devem estar envolvidos em interações formais que fortaleçam o comprometimento de todos.
A pressão por soluções de software confiáveis e em curtos prazos favoreceu a criação da metodologia de desenvolvimento rápido de software (RAD). A ideia de entregar protótipos em um ciclo de desenvolvimento incremental e iterativo permite que o usuário possa ter rapidamente uma visão clara de como o sistema está progredindo e se existe alguma questão relacionada aos requisitos que precisa ser aperfeiçoada. Portanto, a colaboração entre desenvolvedores e usuários suporta o desenvolvimento de especificações mais precisas e validadas.
A metodologia RAD é caracterizada pelo desenvolvimento do projeto através de etapas iterativas e incrementais, onde um protótipo é entregue ao final de cada ciclo. A proposta é que haja redução nas atividades relacionadas ao planejamento em detrimento do processo de desenvolvimento através de um processo que se caracteriza por incrementos de funcionalidades a cada nova iteração. Desse modo, a expectativa é que as equipes produzam mais em menos tempo, maximizando a satisfação do cliente, uma vez que ele é envolvido no processo. Isso ocorre porque a RAD é estruturada para que as partes interessadas interajam e possam detectar a necessidade de alterações do projeto em tempo real, sem a necessidade de completar longos ciclos de desenvolvimento, e os desenvolvedores possam realizar as implementações rapidamente ao longo das iterações.
Vamos explorar em detalhes as quatro fases essenciais da Metodologia RAD (Rapid Application Development). Você aprenderá como essa abordagem ágil transformou o desenvolvimento de software, acelerando a criação de aplicações e promovendo a colaboração eficaz entre equipes de projeto.
## [Python] Python aka CPython

Além do Python 2 e Python 3, existe mais de uma versão de cada uma. Em primeiro lugar, existem os Pythons que são mantidos pelas pessoas reunidas em torno da PSF (Python Software Foundation), uma comunidade que visa desenvolver, melhorar, expandir e popularizar o Python e o seu ambiente. O presidente da PSF é o próprio Guido von Rossum, e por esta razão, estes Pythons são chamados de canônicos. São também considerados **Pythons de referência**, pois qualquer outra implementação da linguagem deve seguir todas as normas estabelecidas pelo PSF.
Guido van Rossum utilizou a linguagem de programação C para implementar a primeira versão da sua linguagem, e esta decisão ainda está em vigor. Todos os Pythons provenientes do PSF são escritos na linguagem C. Há muitas razões para esta abordagem e ela tem muitas consequências. Uma delas (provavelmente a mais importante) é que graças a ela, o Python pode ser facilmente portado e migrado para todas as plataformas com a capacidade de compilar e executar programas em linguagem C (praticamente todas as plataformas têm esta característica, o que abre muitas oportunidades de expansão para Python).

É por isso que a implementação da PSF é frequentemente referida como **CPython**. Este é o Python mais influente entre todos os Pythons do mundo.
O CPython é uma **implementação** da linguagem Python, um pacote com um compilador e um interpretador Python (Máquina Virtual Python - PVM), além de outras ferramentas para programar em Python.
## [Python] Cython

Outro membro da família Python é o **Cython** que é uma das várias soluções possíveis para a mais dolorosa das características de Python - **a falta de eficiência**. Grandes e complexos cálculos matemáticos podem ser facilmente codificados em Python (muito mais facilmente do que em C ou qualquer outra linguagem tradicional), mas a execução do código resultante pode ser extremamente demorada.
Como são conciliadas estas duas contradições? Uma solução é escrever as suas ideias matemáticas usando Python, e quando estiver absolutamente seguro de que o seu código está correto e produz resultados válidos, pode traduzi-lo para C. Certamente, o C correrá muito mais rápido do que Python puro.
É isto que o Cython pretende fazer - traduzir automaticamente o código Python (limpo e claro, mas não demasiado rápido) em código C (complicado e falador, mas ágil).
## [Python] Jython

Outra versão do Python é chamada **Jython**, o “J” é para “Java”. Imagine um Python escrito em Java em vez de C. Isto é útil, por exemplo, se desenvolver sistemas grandes e complexos escritos inteiramente em Java, e quiser acrescentar alguma flexibilidade Python a eles. O CPython tradicional pode ser difícil de integrar em tal ambiente, já que C e Java vivem em mundos completamente diferentes e não partilham muitas ideias comuns.
Jython pode comunicar com a infra-estrutura Java existente de forma mais eficaz. É por isso que alguns projetos o consideram utilizável e necessário.
> **Nota**: A atual implementação do Jython segue as normas do Python 2. Até ao momento, não há Jython em conformidade com Python 3.
> **Curiosidade**: Curioso saber que o código Python pode ser traduzido em Bytecode Java usando a implementação **Jython** para rodar aplicações Java e na JVM - Java Virtual Machine.
## [Python] PyPy e RPython

Dê uma vista de olhos ao logotipo acima. É um rébus. Consegue resolvê-lo? É um logótipo do **PyPy** - *um Python dentro de um Python*. Por outras palavras, representa um ambiente Python escrito em linguagem Python, chamado **RPython** (Restricted Python). Na verdade, é um subconjunto de Python.
O source code de PyPy não é executado na forma de interpretação, mas sim traduzido para a linguagem de programação C e depois executado separadamente.
Isto é útil porque se quiser testar qualquer nova funcionalidade que possa ser (mas não tem de ser) introduzida na implementação do Python convencional, é mais fácil verificá-la com o PyPy do que com o CPython. É por isto que o PyPy é antes uma ferramenta para pessoas que desenvolvem Python, do que para o resto dos utilizadores.
Isto não torna o PyPy menos importante ou menos sério do que o CPython, é claro.
Além disso, o PyPy é compatível com a linguagem do Python 3.
Existem muitos mais Pythons diferentes no mundo. Encontrá-los-á se procurar, vamos nos concentrar no CPython.
## [Python] Sistema de implementação do Python
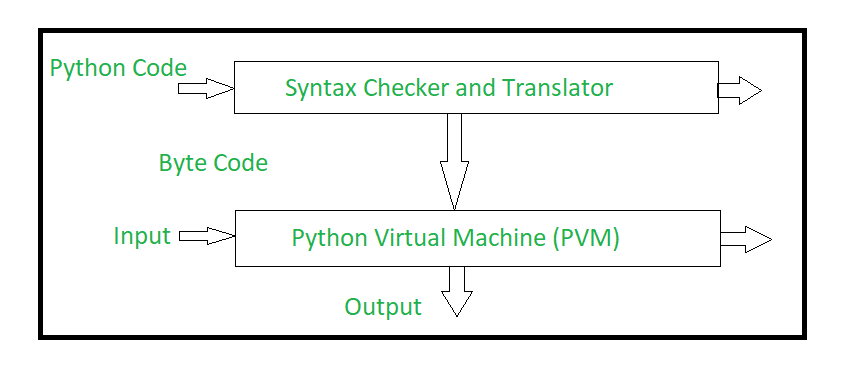
**Python** usa um sistema híbrido, uma combinação de interpretador e tradutor (compilador). O **compilador** converte o código-fonte Python em um código intermediário, que roda numa máquina virtual, a **PVM** (Python Virtual Machine).
O Python é uma linguagem interpretada. Isto significa que herda todas as vantagens e desvantagens descritas. Naturalmente, acrescenta algumas das suas características únicas a ambos os conjuntos.
Se quiser programar em Python, precisará do intérprete Python. Não será capaz de executar o seu código sem ele. Felizmente, o Python é gratuito. Esta é uma das suas vantagens mais importantes.
Devido a razões históricas, as linguagens concebidas para serem utilizadas na forma de interpretação são muitas vezes chamadas linguagens de scripting, enquanto os source programs codificados que as utilizam são chamados scripts.
O **virtualenv** do Python é utilizado para isolar a versão do Python e das bibliotecas usadas em um determinado sistema. Caso você não utilize o virtualenv, todas as bibliotecas necessárias para seu sistema seriam instaladas no ambiente do sistema operacional. Existe outra forma de fazer isso com o **Pipenv**.
## [Python] Instalação, utilitários e módulos

Existem várias maneiras de obter a sua própria cópia do Python 3, dependendo do sistema operativo que utilize.
Utilizadores de **Linux** provavelmente já têm o Python instalado - este é o cenário mais provável, já que a infraestrutura do Python é intensamente utilizada por muitos componentes do sistema operativo Linux.
Por exemplo, alguns distribuidores podem acoplar as suas ferramentas específicas ao sistema e muitas destas ferramentas, como gestores de pacotes, são frequentemente escritas em Python. Algumas partes de ambientes gráficos disponíveis no mundo Linux também podem utilizar o Python.
Se for um utilizador Linux, abra o terminal/console e digite:
[](#)
```sh
python3
```
No shell prompt, pressione Enter e aguarde. Se vir algo deste gênero:
Python 3.4.5 (default, Jan 12 2017, 02:28:40)
[GCC 4.2.1 Compatible Clang 3.7.1 (tags/RELEASE_371/final)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>

Se o Python 3 estiver ausente, consulte a sua documentação do Linux para saber como utilizar o seu gestor de pacotes para descarregar e instalar um novo pacote - o que precisa chama-se python3, ou o seu nome começa com isso.
> Todos os utilizadores que não sejam Linux podem descarregar uma cópia em: https://www.python.org/downloads/.
> **Nota**: Por padrão, a versão do Python 2 já se encontra instalado nas máquinas do sistema operacional Linux e macOS.
Como o browser diz ao site onde entrou o sistema operativo que utiliza, o único passo que tem de dar é clicar na versão Python apropriada que deseja.
Neste caso, selecione Python 3. O site oferece sempre a versão mais recente do mesmo. Se for um utilizador do Windows, inicie o arquivo `.exe` descarregado e siga todos os passos.
> **Windows Env**: Caso seja um usuário de Windows, deixe as configurações padrão que o instalador sugere por agora, com uma exceção - veja a caixa de verificação chamada `Add Python 3.x to PATH` e verifique-a. Isto tornará as coisas mais fáceis, pois vai adicionar o caminho do python3 instalado na sua máquina local para as variáveis de ambiente do seu sistema operacional Windows.
Se for um utilizador MacOS, uma versão do Python 2 pode já ter sido pré-instalada no seu computador, mas como vamos trabalhar com o Python 3, ainda assim terá de descarregar e instalar o arquivo `.pkg` relevante a partir do site Python.
Agora que tem o Python 3 instalado, é altura de verificar se funciona, e fazer o primeiro uso do mesmo. Este será um procedimento muito simples, mas deve ser o suficiente para o convencer de que o ambiente Python é completo e funcional.
Se ao usar o Python você sentir que o gerenciador de pacotes não está funcionando corretamente, e apresentar esse log: `Python :Fatal error in launcher: Unable to create process using ""C:\Program Files (x86)(5solution)`, clique no link para aprender como resolver.
Caso se você estiver utilizando uma versão mais antiga e deseja atualizar para uma versão mais atual, veja como no link.
Existem muitas formas de utilizar o Python, especialmente se vier a ser um programador Python. Para começar o seu trabalho, precisa das seguintes ferramentas:
- um **editor** que o irá apoiar na escrita do código (deve ter algumas características especiais, não disponíveis em ferramentas simples); este editor dedicado dar-lhe-á mais do que o equipamento padrão do sistema operativo;
- uma **console** na qual pode rodar o seu código recém-escrito e pará-lo à força quando ficar fora de controle;
- uma ferramenta chamada de **debugger**, capaz de rodar o seu código passo a passo e que lhe permite inspecioná-lo em cada momento da execução.

Apenas como exemplo, na área de Console clique no botão **Python Console**. No prompt interativo `>>>` que se abrirá, digite `x = 5` e pressione a tecla [ENTER] ou [RETURN] do seu teclado. Observe na figura 2 que, na área Árvore de exibição de variáveis, agora fica disponível a informação que a variável `x` é do tipo `int` e tem o valor `5`.
Não se preocupe ainda com o conceito de variável, nem com o seu tipo. Veremos tudo isso com detalhes nos próximos módulos deste tema.
O utilitário `dir` apresenta todos os atributos e métodos disponíveis para determinado tipo de dado. No prompt interativo `>>>`, digite dir(x) e pressione a tecla [ENTER] ou [RETURN] do seu teclado.
No prompt interativo `>>>`, digite `dir(x)` e pressione a tecla [ENTER] ou [RETURN] do seu teclado.

O utilitário `help` apresenta a documentação relativa a determinado tipo de dado. Caso você tenha alguma dúvida sobre o que é possível fazer com determinado tipo, os utilitários `dir` e `help` podem ser úteis.
Para além dos seus muitos componentes úteis, a instalação padrão de Python 3 contém uma aplicação muito simples mas extremamente útil chamada "IDLE".
Com o **IDLE - Integrated Development and Learning Environment** iniciado. Isto é o que deve ver:

IDLE é uma boa escolha para iniciantes em Python. É um ambiente de desenvolvimento fácil de aprender e usar, e fornece as ferramentas básicas necessárias para começar a programar em Python. O IDLE é um ambiente de desenvolvimento integrado (IDE) para a linguagem de programação Python. Ele é incluído na distribuição padrão do Python e está disponível para Windows, macOS e Linux. IDLE é um ambiente de desenvolvimento simples e fácil de usar. Ele fornece as ferramentas básicas necessárias para escrever, depurar e executar código Python. As principais características do IDLE incluem:
- Um editor de texto com recursos básicos, como autocompletar e realce de sintaxe.
- Um shell Python interativo que permite executar código Python linha por linha.
- Um depurador (debugger) que permite depurar código Python passo a passo.
- Um gerenciador de projetos que permite organizar arquivos Python.

O Python tem vários gerenciadores de pacotes que facilitam a instalação, atualização e remoção de pacotes e bibliotecas. Os dois gerenciadores de pacotes mais comuns para Python são:
O `pip` - Package Installer for Python é o gerenciador de pacotes padrão para Python. Ele facilita a instalação e gerenciamento de pacotes a partir do Python Package Index (PyPI), que é o repositório oficial de pacotes Python. Você pode usar o pip para instalar pacotes com o seguinte comando:
```sh
# Python 3.12
python3 -m pip install
# Python 3.8
pip install
```
Para quem usa a IDE Spyder (SPYDER, 2020) ou o Google Colab, é necessário colocar uma exclamação antes do comando “pip”, ou seja:
```sh
!pip install
```
Também é possível instalar a partir de um arquivo `requirements.txt`:
```sh
pip install -r requirements.txt
```
Para mais informações, você pode digitar `pip --help` no terminal.
Também é possível atualizar a versão do pip, caso haja atualização de alguma biblioteca para a versão mais recente do Python, veja abaixo:
```sh
# -m pip install --upgrade pip
C:\Users\isaac\AppData\Local\Microsoft\WindowsApps\PythonSoftwareFoundation.Python.3.12_qbz5n2kfra8p0\python.exe -m pip install --upgrade pip
```
Caso se seguirmos um código utilizando funções que não são nativas da linguagem de programação, vai então, ao executar o Python, aparece a seguinte mensagem de erro:
NameError: name 'sin' is not defined
> O que isso significa? O Python não reconheceu a função seno. Isso acontece porque muitas funcionalidades do Python estão disponíveis em bibliotecas adicionais, chamadas de **módulos**.
A **biblioteca padrão Python** consiste em milhares de **funções**, **métodos** e **classes** relacionados a determinada finalidade e organizados em componentes chamados **módulos**. São **mais de 200 módulos** que dão suporte, entre outras coisas, a:
- Operações matemáticas;
- Interface gráfica com o usuário (GUI);
- Funções matemáticas e geração de números pseudoaleatórios.
Atenção! É importante lembrar dos conceitos de classes e objetos, pois eles são os principais conceitos do paradigma de programação orientada a objeto. As classes são fábricas, que podem gerar instâncias chamadas objetos. Uma classe Pessoa, por exemplo, pode ter como atributos nome e CPF. Ao gerar uma instância de Pessoa, com nome João da Silva e CPF 000.000.000-00, temos um objeto.
> Saiba+ Para melhor compreensão dos conceitos de classe e objeto, pesquise sobre paradigma orientado a objeto (OOP).
Para usar as **funções** e os **métodos** de **um módulo importado**, são necessários dois passos:
- Fazer a importação do módulo desejado com a instrução:
```python
import nome_modulo
```
- Chamar a função desejada, precedida do nome do módulo, com a instrução:
```python
nome_modulo.nome_funcao(paramêtros)
```
Como exemplo, vamos importar o módulo **math** (dedicado a operações matemáticas) e calcular a **raiz quadrada** de 5, por meio da função `sqrt()`. Observe a Figura 30:
>>>import math
>>>math.sqrt(5)
2.23606797749979
A partir desse ponto, serão apresentados os principais aspectos dos seguintes módulos:
- `math` usado para operações matemáticas;
- `random` usado para gerar números pseudoaleatórios;
- `smtplib` usado para permitir envio de e-mails;
- `time` usado para implementar contadores temporais;
- `tkinter` usado para desenvolver interfaces gráficas.
O módulo `math` provê acesso a funções matemáticas de argumentos reais. As funções não podem ser usadas com números complexos.
O módulo `math` tem as funções listadas na Tabela 7, entre outras:
Função
Retorno
sqrt(x)
Raiz quadrada de x
ceil(x)
Menor inteiro maior ou igual a x
floor(x)
Maior inteiro menor ou igual a x
cos(x)
Cosseno de x
sin(x)
Seno de x
log(x,b)
Logaritmo de x na base b
pi
Valor de Pi (3.141592...)
e
Valor de e (2.718281...)
> Saiba+ Para mais informações sobre o módulo math, visite a biblioteca Python.
Vamos ver um exemplo, utilizando o Google Colab, para importar e usar a famosa biblioteca **Math** do Python, que permite utilizar funções matemáticas dentro da linguagem de programação:
A palavra-chave, nessa situação, é `import`, e, logo depois, coloca-se o módulo. Por questão de organização, o ideal é colocar sempre no início do programa.
Quando fazemos isso, temos acesso a todas as funções da biblioteca math, mas devemos informar ao Python de qual biblioteca estamos chamando a função, para isso utilizamos a sintaxe `módulo.função()`. Desse modo, utilizaremos o `math.sin()` e o `math.pi`. Então, nosso programa pode ser escrito da seguinte maneira:
[](https://colab.research.google.com/drive/1LB-mVNz_dy6N7G8iHgYAtzgXplaUuKN1#scrollTo=vByZRBz2gFho)
```python
import math
vo = 300
g = 10
theta = 15
A = (vo**2/g)*math.sin(2*theta*math.pi/180)
print(round(A))
```
Você também pode chamar essa importação limitando a determinada função que você deseja obter, é extremamente recomendado para não pesar a consulta. Em nosso problema inicial, essa forma de “chamar” as funções do módulo sem utilizar o prefixo ficaria:
```python
from math import sin, pi
v0 =300
g=10
theta=15
A= (v0**2/g)*sin(2*theta*pi/180)
print(A)
```
Caso seja necessário utilizar todas as funções da biblioteca, basta usar o comando `from módulo import *`. Veja o exemplo:
```python
>>>from math import *
>>>v0 =300
>>>g=10
>>>theta=15
>>>A= (v0**2/g)*sin(2*theta*pi/180)
>>>print(A)
```
O Python permite também que importemos um módulo e atribuamos a ele um “apelido”, para utilizar como prefixo ao chamar uma função. O comando é `import` módulo as “apelido”. Desse modo, quando utilizar uma função da biblioteca, basta usar o seguinte formato: `apelido.função()`. Por exemplo:
```python
>>>import math as m
>>>v0 =300
>>>g=10
>>>theta=15
>>>A= (v0**2/g)*m.sin(2*theta*m.pi/180)
>>>print(A)
```
Observe que o apelido será `m`; assim, chamamos a função seno com `m.sin()`. De maneira análoga, podemos atribuir “apelidos” para as funções `from módulo import função as apelido`. Por exemplo:
```python
>>>from math import cos as c, sin as s
>>>print(c(0) + s(0))
```

Vamos retornar ao nosso problema do início do conteúdo, ou seja: determinar a posição vertical `y` da bola no tempo `t`. Para construir o gráfico dessa função, utilizaremos o módulo `matplotlib`, usado, em geral, para realizar gráficos em 2D.
O **Matplotlib** é uma biblioteca de software para criação de gráficos e visualizações de dados em geral, feita para e da linguagem de programação Python e sua extensão de matemática **NumPy**.
```python
>>>import numpy as np
>>>import matplotlib.pyplot as plt
>>>v0 = 5 # Velocidade inicial
>>>g = 10 # Aceleração da gravidade
>>>t = np.linspace(0,1,1001) # Tempo
>>>y = v0 * t - 0.5 * g * t ** 2 # Posição vertical
>>>plt.plot(t,y) # plotar o grafico yxt
>>>plt.xlabel('t (s)') # eixo x com t(s)
>>>plt.ylabel('y (m)') # eixo y como y(m)
>>>plt.show() # mostrar a figura
```
Como saída, o Python apresenta o seguinte gráfico:

No programa apresentado, temos que destacar 2 pontos:
1. A função `linspace` retorna um vetor e a construção genérica dele é `linspace(a,b,n)`, onde gera um vetor no intervalo `[a,b]` e com `n` pontos.
2. Quando utilizamos `t` como vetor, a função da altura `y(t)` torna-se também um vetor.
É possível ver qual o caminho do diretório de instalação do python, através da biblioteca `sys`. Veja abaixo:
```python
import sys
sys.executable
# Output: Python installation PATH
```
Mas e se eu quiser utilizar as várias versões da linguagem python ou diferentes bibliotecas instaladas para usar na minha aplicação? Para isso existe o `pipenv` que faz o gerenciamento de pacotes como o `pip` faz e também o ambiente virtual de desenvolvimento, ele basicamente une essas funcionalidades.
```sh
pip install pipenv
```
Para instalar algum pacote nesse ambiente virtual python, basta:
```sh
pipenv install
```
O módulo `random` implementa geradores de números pseudoaleatórios para várias distribuições.
- **Números inteiros**: Para inteiros, existe uma seleção uniforme a partir de um intervalo.
- **Sequências**: Para sequências, existem:
- Uma seleção uniforme de um elemento aleatório;
- Uma função para gerar uma permutação aleatória das posições na lista;
- Uma função para escolher aleatoriamente sem substituição.
A Tabela 8 mostra algumas das principais funções disponíveis para distribuições de valores reais no módulo `random`.
Embora o Python tenha muitas funções internas, como o `print()`, também possui um conjunto de bibliotecas-padrão, que são programas em Python que podem ser incluídos no seu programa. Usaremos o módulo math, pois ele disponibiliza diversas funções matemáticas. Existem certas formas de “chamar” esses módulos no seu programa, a seguir veremos algumas.

Outra forma de executar os comandos da linguagem Python é por meio de **notebooks** que são ambientes interativos que permitem criar e compartilhar documentos que misturam código executável, texto explicativo, imagens, gráficos e outros elementos. Existem vários tipos de notebooks para Python que podem ser encontrados na internet, cada um com suas características, vantagens e desvantagens. Eles são muito populares na comunidade de ciência de dados, programação e pesquisa. Os notebooks mais conhecidos são os Jupyter Notebooks e Google Colab, que são documentos que podem conter tanto código (em várias linguagens, incluindo Python, R, Julia, entre outras) quanto elementos de texto formatado, imagens, equações matemáticas e visualizações. Eles são divididos em células, onde cada célula pode conter código para ser executado ou texto explicativo formatado usando Markdown. Isso permite uma exploração interativa de dados e uma maneira eficiente de documentar o código e seus resultados.
Os notebooks oferecem vantagens, como:
- Interatividade: Permite executar pequenos trechos de código de maneira independente em cada célula, visualizando imediatamente os resultados.
- Visualização de dados: É possível gerar gráficos, tabelas e visualizações diretamente no documento, facilitando a análise e compreensão dos dados.
- Documentação intercalada com código: Permite explicar o raciocínio por trás do código e dos resultados, facilitando a compreensão para outras pessoas que interagem com o notebook.
- Compartilhamento e colaboração: Os notebooks podem ser facilmente compartilhados com outras pessoas, permitindo a colaboração em projetos e a reprodução dos passos realizados.
Esses notebooks são utilizados em diversas áreas, incluindo ciência de dados, aprendizado de máquina, pesquisa acadêmica, análise exploratória de dados, entre outras, devido à sua flexibilidade e capacidade de integração de código e documentação.
O **Jupyter Notebook** é um aplicativo da web de código aberto que pode ser usado para construir e compartilhar código ativo, equações, visualizações e documentos de texto. O Jupyter Notebook é mantido pelo pessoal do Projeto Jupyter. Ele suporta mais de 40 linguagens de programação, incluindo Python, R, Julia e Scala. Ele também permite a integração com bibliotecas e frameworks populares de ciência de dados, como numpy, pandas, scikit-learn, tensorflow, etc.
Instalando o Jupyter na sua máquina local: Com essa instalação nós estamos instalando o Jupyter Notebook e o JupyterLab no ambiente global do Python (ou no ambiente virtual ativo, se houver um).
```sh
pip install notebook jupyterlab
```
O Jupyter cria um servidor local, permitindo que você acesse a interface via navegador. Os arquivos `.ipynb` (notebooks) são salvos no sistema de arquivos local, diferentemente de um ambiente volátil, como o Google Colab, onde as alterações podem ser perdidas se não forem salvas explicitamente no Google Drive ou baixadas.
Se você instalar o Jupyter globalmente (fora de um ambiente virtual), ele poderá ser acessado de qualquer diretório no seu sistema. Se instalado dentro de um ambiente virtual, o Jupyter estará restrito a esse ambiente, garantindo que pacotes e versões específicas sejam usados apenas nesse contexto.
Inicializando o Jupyter Notebook:
```sh
jupyter notebook
```
[](https://jupyter.org/try)
Você pode criar um arquivo `.ipynb` ou abrir um na sua máquina local.

O **Google Colab**, ou Colaboratory, é uma plataforma baseada em nuvem fornecida pelo Google que permite escrever, compartilhar e executar códigos Python diretamente no navegador. É especialmente útil para análise de dados, aprendizado de máquina, educação em ciência de dados e para executar notebooks Jupyter. É um serviço de nuvem gratuito que oferece notebooks para Python que podem ser executados no navegador. O Google Colab permite o uso de GPUs e TPUs gratuitamente, o que é muito útil para treinar modelos de aprendizado de máquina complexos. Ele também facilita o compartilhamento e a colaboração de notebooks com outros usuários. Ele é baseado no Jupyter Notebook e tem uma interface semelhante.
Alguns dos principais recursos do Google Colab incluem:
[](https://colab.research.google.com/)
- Ambiente de notebook interativo: Permite escrever e executar código Python em células individuais, facilitando a experimentação e a visualização dos resultados.
- Gratuito com recursos de GPU e TPU: Oferece acesso gratuito a recursos de hardware, como GPUs (Unidades de Processamento Gráfico) e TPUs (Unidades de Processamento Tensorial), o que é especialmente útil para tarefas intensivas de computação, como aprendizado de máquina e treinamento de modelos.
- Integração com o Google Drive: Permite importar conjuntos de dados e salvar resultados diretamente no Google Drive.
- Compartilhamento fácil: Os notebooks podem ser compartilhados com outras pessoas, permitindo colaboração em tempo real.
Essa plataforma é bastante utilizada por cientistas de dados, pesquisadores, desenvolvedores e estudantes devido à sua facilidade de acesso, recursos gratuitos e flexibilidade para executar códigos complexos em um ambiente baseado na nuvem.
O colab já fornece um conjunto de bibliotecas python já instaladas em seus notebooks, porém caso aja uma excessão de biblioteca não instalada, recomendo seguir os passos que a própria plataforma indica, basta clicar no badge acima para aprender sobre os snippets de importação de bibliotecas do colab.
O **Kaggle** é uma plataforma online que hospeda competições de ciência de dados e aprendizado de máquina. Ele também oferece notebooks para Python que podem ser usados para explorar, analisar e modelar dados. O Kaggle permite o acesso a conjuntos de dados públicos e privados, bem como a GPUs e TPUs gratuitas. Ele também tem uma comunidade ativa de cientistas de dados e aprendizes de máquina que compartilham seus notebooks e soluções.

Além do `pip`, nós temos o **Anaconda**, que é uma distribuição do Python focada em ciência de dados, machine learning e análise de dados, oferecendo um ambiente completo com várias bibliotecas e ferramentas pré-instaladas, como **NumPy, Pandas, SciPy, Matplotlib, Jupyter Notebook**, entre outras. Confira no site oficial.
O Anaconda também inclui o `conda`, um gerenciador de pacotes e ambientes virtuais que permite instalar e gerenciar dependências de forma eficiente, especialmente útil para projetos científicos e de inteligência artificial. O conda pode instalar pacotes de diversas fontes, incluindo o PyPI, e também gerenciar ambientes virtuais.
Se quiser instalar pacotes com o conda (ao invés de `pip`), basta usar:
```sh
conda install
```
E para criar ambientes virtuais:
```sh
conda create --name meu_ambiente python=3.9
conda activate meu_ambiente
```
Veja como escrever e executar o seu primeiro programa:
É agora tempo de escrever e executar o seu primeiro programa de Python 3. Será muito simples, por agora.
O primeiro passo é criar um novo source file e preenchê-lo com código. Clique em `File` no menu do IDLE e escolha `New file`.

> Como pode ver, o IDLE abre uma nova janela para si. Pode utilizá-la para escrever e alterar o seu código.
Esta é a **janela do editor**. O seu único objetivo é ser um local de trabalho em que o seu source code é tratado. Não confundir a janela do editor com a janela shell. Desempenham funções diferentes.
A janela do editor está atualmente sem título, mas é uma boa prática começar a trabalhar nomeando o source file.
Clique em `File` (na nova janela), depois clique em `Save as...`, selecione uma pasta para o novo ficheiro (o ambiente de trabalho é um bom local para as suas primeiras tentativas de programação) e escolha um nome para o novo ficheiro.

[](#)
> **Nota**: não defina nenhuma extensão para o nome do ficheiro que vai utilizar. O Python precisa que os seus ficheiros tenham a extensão `.py`, por isso deve confiar nas predefinições da janela de diálogo. A utilização da extensão padrão `.py` permite que o sistema operativo abra adequadamente estes ficheiros.
Agora coloque apenas uma linha na sua janela do editor recém-aberta e nomeada. A linha tem este aspeto:
[](#)
```python
print("Hisssssss...")
```
> O comando `print()` , que é uma das diretivas mais fáceis em Python, imprime simplesmente uma linha para o ecrã.
Veja mais de perto as aspas. Estas são as formas mais simples de aspas (neutras, retas, mudas, etc.) tipicamente utilizadas nos source files. Não tente usar aspas tipográficas (curvas, curvilíneas, inteligentes, etc.), utilizadas por processadores de texto avançados, uma vez que o Python não as aceita.

Guarde o ficheiro `File > Save` e execute o programa `Run -> Run Module`.
Se tudo correr bem e não houver erros no código, a janela do console irá mostrar-lhe os efeitos causados pela execução do programa. Neste caso, o programa sibila. Tente executá-lo mais uma vez. E mais uma vez. Agora feche ambas as janelas e regresse ao ambiente de trabalho.

Aprenda como estragar e corrigir o seu código! Agora, reinicie o IDLE. Clique em `File > Open > aponte para o ficheiro que guardou anteriormente e deixe o IDLE lê-lo`.
Tente executá-lo novamente pressionando `F5` quando a janela do editor estiver ativa. Como pode ver, o IDLE é capaz de guardar o seu código e recuperá-lo quando precisar dele novamente.
O IDLE contém um recurso adicional e útil.
1. Primeiro, remova o parêntesis final.
2. Em seguida, insira o parêntesis novamente.
O seu código deve parecer-se com o que está aqui em baixo:
[-fff?style=social&logo=Python&logoColor=3776AB)](#)
Hisssssss...

Cada vez que colocar o parêntesis final no seu programa, o IDLE mostrará a parte do texto limitada com um par de parêntesis correspondentes. Isto ajuda-o a lembrar-se de os colocar em pares.
Retire novamente o parêntesis final. O código torna-se incorreto. Contém agora um erro de sintaxe. O IDLE não deve deixar que o execute.
Tente executar o programa novamente. O IDLE irá lembrá-lo de guardar o ficheiro modificado. Siga as instruções.
Observe cuidadosamente todas as janelas. Uma nova janela – diz que o intérprete encontrou um EOF (end-of-file) embora (na sua opinião) o código deva conter mais algum texto.
A janela do editor mostra claramente onde isto aconteceu.

Corrija o código agora. Deve ficar assim:
[](#)
```python
print("Hisssssss...")
```
Execute-o para ver se “sibila” novamente.
Vamos estragar o código mais uma vez. Remova uma letra da palavra `print`. Execute o código pressionando `F5`. O que acontece agora?

Deve ter notado que a mensagem de erro gerada para o erro anterior é bastante diferente da primeira.

Isto acontece porque a natureza do erro é diferente e o erro é descoberto numa fase diferente de interpretação.
A janela do editor não fornecerá qualquer informação útil sobre o erro, mas as janelas da console poderão.
A mensagem (a vermelho) mostra (nas linhas subsequentes):
- o **traceback** (que é o caminho que o código percorre através de diferentes partes do programa - pode ignorá-lo por agora, uma vez que está vazio num código tão simples);
- a **localização do erro** (o nome do ficheiro contendo o erro, o número da linha e o nome do módulo);
> **Nota**: o número pode ser enganador, uma vez que o Python normalmente mostra o local onde primeiro se notam os efeitos do erro, não necessariamente o erro em si.
- o **conteúdo da linha errada**;
> **Nota**: a janela do editor IDLE não mostra os números das linhas, mas mostra a localização atual do cursor no canto inferior direito; use-a para localizar a linha errada num source code longo;
- o **nome do erro** e uma breve explicação.
> Experimente criar novos ficheiros e executar o seu código. Tente fazer output de uma mensagem diferente para o ecrã, por exemplo `roar!`, `meow`, ou até mesmo talvez um `oink!`. Tente estragar e corrigir o seu código - veja o que acontece.
Ao retirar as aspas do argumento da `string` também é gerado um erro. Veja mais:
[](#)
```python
print(Hisssssss...)
```
[](#)
Traceback (most recent call last):
File "snake.py", line 1, in
print(Hisssssss...)
NameError: name 'Hisssssss...' is not defined
Agora, ao retirar os parênteses da função com o argumento `string` também é gerado um erro. Veja mais:
[](#)
```python
printHisssssss...
```
[](#)
Traceback (most recent call last):
File "snake.py", line 1, in
printHisssssss...
NameError: name 'printHisssssss...' is not defined
Agora, veja o que acontece ao colocar aspas duplas sem parênteses:
[](#)
```python
print"Hisssssss..."
```
[](#)
File "snake.py", line 1
print"Hisssssss..."
^
SyntaxError: invalid syntax
Agora, veja o que acontece ao colocar duas aspas distintas sem parênteses:
[](#)
```python
print'Hisssssss..."
```
[](#)
File "snake.py", line 1
print'Hisssssss..."
^
SyntaxError: EOL while scanning string literal
Agora, veja o que acontece ao colocar duas aspas simples ou duplas sem parênteses e com um sinal de igual:
[](#)
```python
print='Hisssssss...'
```
[](#)
Success (1.82s)
> Ele compila, mas não exibe resultado! Pois ele identificou como uma **variável** armazenando um valor, mas se exibirmos essa variável vai existir um erro de tipo.
## [Python] `Hello, World!`

É tempo de começar a escrever algum código Python real e funcional. Vai ser muito simples por enquanto.
Como vamos mostrar-lhe alguns conceitos e termos fundamentais, estes snippets de código não serão sérios ou complexos.
[](#)
```python
print("Hello, World!")
```
Execute o código na janela do editor à direita. Se tudo correr bem aqui, verá a linha de texto na janela da console.
Em alternativa, lançe o IDLE, crie um novo source file Python, preencha-o com este código, nomeie o ficheiro e guarde-o. Agora execute-o. Se tudo correr bem, verá o texto contido dentro das aspas na janela da console IDLE. O código que executou deve parecer familiar. Viu algo muito semelhante quando o conduzimos através da criação do ambiente IDLE.
Agora vamos passar algum tempo a mostrar e a explicar-lhe o que está realmente a ver, e porque é que se parece com isto.
Como pode ver, o primeiro programa consiste nas seguintes partes:
- a palavra `print`;
- um parêntesis de abertura;
- umas aspas;
- uma linha de texto: `Hello, World!`;
- outras aspas;
- um parêntesis de fecho.
Cada um dos itens acima desempenha um papel muito importante no código.
Veja a linha de código abaixo:
[](#)
```python
print("Hello, World!")
```
A palavra `print` que se pode ver aqui é um **nome de função**. Isso não significa que, onde quer que a palavra apareça, é sempre um nome de função. O significado da palavra vem do contexto em que a palavra foi usada.
Provavelmente já encontrou o termo função muitas vezes antes, durante as aulas de matemática. Provavelmente também pode listar vários nomes de funções matemáticas, como seno ou log.
As funções Python, no entanto, são mais flexíveis e podem conter mais conteúdo do que as suas irmãs matemáticas.
Uma função (neste contexto) é uma parte separada do código do computador capaz de:
- **causar um qualquer efeito** (por exemplo, enviar texto para o terminal, criar um ficheiro, desenhar uma imagem, reproduzir um som, etc.); isto é algo completamente inédito no mundo da matemática;
- **avaliar um valor** (por exemplo, a raiz quadrada de um valor ou o comprimento de um dado texto) e **devolvê-lo como o resultado da função**; é isto que faz as funções Python serem os parentes dos conceitos matemáticos.
Além disso, muitas das funções Python podem fazer as duas coisas acima juntamente.
De onde vêm as funções?
- Podem vir **do próprio Python**; a função `print` é uma deste tipo; tal função é um valor acrescentado recebido juntamente com o Python e o seu ambiente (é **incorporada**); não é necessário fazer nada de especial (por exemplo, perguntar a alguém por qualquer coisa) se quiser fazer uso dela;
- podem ser provenientes de um ou mais dos add-ons de Python chamados **módulos**; alguns dos módulos vêm com Python, outros podem requerer instalação separada - seja qual for o caso, todos eles precisam de estar explicitamente ligados ao seu código (mostrar-lhe-emos como fazê-lo em breve);
- pode **escrevê-los você mesmo**, colocando tantas funções quantas quiser e precisar dentro do seu programa para o tornar mais simples, mais claro e mais elegante.
O nome da função deve ser **significativo** (o nome da função `print` é evidente por si mesmo).
Claro que, se vai fazer uso de qualquer função já existente, não tem influência no seu nome, mas quando começar a escrever as suas próprias funções, deve considerar cuidadosamente a sua escolha de nomes.
Como dissemos antes, uma função pode ter:
- um **efeito**;
- um **resultado**.
Há também uma terceira, muito importante, componente de função - o(s) **argumento(s)**.
As funções matemáticas normalmente aceitam um argumento, por exemplo, `sen(x)` toma um `x`, que é a medida de um ângulo.
As funções de Python, por outro lado, são mais versáteis. Dependendo das necessidades individuais, elas podem aceitar qualquer número de argumentos - tantos quantos forem necessários para desempenhar as suas tarefas.
> **Nota**: qualquer número inclui zero - algumas funções de Python não precisam de qualquer argumento.
[](#)
```python
print("Hello, World!")
```
Apesar do número de argumentos necessários/fornecidos, as funções Python exigem fortemente a presença de **um par de parêntesis** - de abertura e de fecho, respetivamente.
Se quiser entregar um ou mais **argumentos** a uma função, coloque-os **dentro dos parêntesis**. Se for utilizar uma função que não aceita qualquer argumento, ainda assim tem de ter os parêntesis.
> **Nota**: para distinguir palavras comuns de nomes de funções, coloque **um par de parêntesis vazios** após os seus nomes, mesmo que a função correspondente queira um ou mais argumentos. Esta é uma convenção padrão.
A função de que estamos a falar aqui é `print()`. A função `print()` no nosso exemplo tem algum argumento? Claro que sim, mas o que são eles?
O único argumento entregue à função `print()` neste exemplo é uma `string`:
[](#)
```python
print("Hello, World!")
```
Como pode ver, **a string é delimitada com aspas** - de facto, as aspas fazem a string - cortam uma parte do código e atribuem-lhe um significado diferente.
Pode imaginar que as aspas dizem algo como: o texto entre nós não é código. Não se destina a ser executado, e deve tomá-lo como está.
Quase tudo o que colocar dentro das aspas será tomado literalmente, não como código, mas como **dados**. Tente jogar com esta string em particular - modificá-la, introduzir algum conteúdo novo, apagar algum do conteúdo existente.
Há mais do que uma maneira de especificar uma string dentro do código Python, mas por agora, esta é suficiente.
> Até agora, aprendeu sobre duas partes importantes do código: a função e a string. Falámos sobre elas em termos de sintaxe, mas agora é altura de os discutir em termos de semântica.
O nome da função (`print` neste caso) juntamente com os *parêntesis* e o(s) *argumento(s)*, formam a **invocação da função**.
Discutiremos isto com mais profundidade em breve, mas devemos dar-lhe umas luzes de momento.
[](#)
```python
print("Hello, World!")
```
O que acontece quando o Python encontra uma invocação como esta abaixo?
[](#)
```python
function_name(argument)
```
Vamos ver:
- Primeiro, o Python verifica se o nome especificado é **legal** (navega nos seus dados internos a fim de encontrar uma função existente com o mesmo nome; se esta pesquisa falhar, o Python aborta o código);
- segundo, o Python verifica se os requisitos da função para o número de argumentos **lhe permitem invocar** a função desta forma (por exemplo, se uma função específica exigir exatamente dois argumentos, qualquer invocação que apresente apenas um argumento será considerada errada, e abortará a execução do código);
- terceiro, o Python **deixa o seu código por um momento** e salta para a função que pretende invocar; claro, também leva o(s) seu(s) argumento(s) e passa-o(s) para a função;
- quarto, a função **executa o seu código**, causa o efeito desejado (se houver um), avalia o(s) resultado(s) desejado(s) (se existir(em)) e termina a sua tarefa;
- finalmente, o Python **regressa ao seu código** (ao local imediatamente após a invocação) e retoma a sua execução.
Três questões importantes têm de ser respondidas assim que possível:
1. Qual é o efeito que a função `print()` causa?
O efeito é muito útil e muito espetacular. A função:
- toma os seus argumentos (pode aceitar mais do que um argumento e pode também aceitar menos do que um argumento);
- converte-os numa forma legível para o ser humano, se necessário (como pode suspeitar, as strings não requerem esta ação, uma vez que a `string` já é legível);
- e envia os dados resultantes para o dispositivo de output (normalmente o console); por outras palavras, qualquer coisa que coloque na função `print()` aparecerá no ecrã.
Não admira, então, que a partir de agora utilize `print()` muito intensivamente para ver os resultados das suas operações e avaliações.
2. Que argumentos `print()` espera?
Quaisquer. Mostrar-lhe-emos em breve que `print()` é capaz de operar com virtualmente todos os tipos de dados oferecidos pelo Python. Strings, números, carateres, valores lógicos, objetos - qualquer um destes pode ser passado com sucesso para `print()`.
3. Que valor é devolvido pela função `print()` ?
Nenhum. O seu efeito é suficiente.
Já viu um programa de computador que contém uma invocação de função. Uma **invocação de função** é um dos muitos tipos possíveis de **instruções Python**.
É claro que qualquer programa complexo contém geralmente muito mais instruções do que uma. A questão é: como se acoplam mais do que uma instrução no código Python?
[](#)
```python
print("The itsy bitsy spider climbed up the waterspout.")
print("Down came the rain and washed the spider out.")
"""
Output:
The itsy bitsy spider climbed up the waterspout.
Down came the rain and washed the spider out.
"""
```
A sintaxe de Python é bastante específica nesta área. Ao contrário da maioria das linguagens de programação, o Python requer que não haja mais do que uma instrução numa linha.
Uma linha pode estar vazia (ou seja, pode não conter qualquer instrução) mas não deve conter duas, três ou mais instruções. Isto é estritamente proibido.
> **Nota**: o Python faz uma exceção a esta regra - permite que uma instrução se espalhe por mais do que uma linha (o que pode ser útil quando o seu código contém construções complexas).
Para escrever um programa em Python, será essencial utilizar as formas de **saída de dados** (output) para exibir ao usuário mensagens e resultados de operações. Caso você deseje que o usuário informe algum dado para que seu programa processe, será necessário utilizar as formas de entrada de dados.
A função `print()` em Python atua de forma semelhante à `printf()` em **C**. Para um programador iniciante, as maiores diferenças entre elas são:
- Duas chamadas da `print()` em Python são impressas na tela em linhas diferentes, sem a necessidade do uso do caractere `\n` para pular a linha, como ocorre na `printf()` em **C**.
- Uma chamada da `print()` em Python permite a impressão de valores de variáveis sem a indicação do formato, como ocorre na `printf()` em **C**, quando precisamos escrever `%c`, `%d` ou `%f`, por exemplo.
Para escrever seu **Hello, World!** em Python, digite a seguinte linha, exatamente como está escrita:
~~~python
print(“Hello, World!”)
~~~
ou
~~~python
print('Hello, World!')
~~~