https://github.com/isaacmg/big_data_learning
big data
https://github.com/isaacmg/big_data_learning
backend big-data data-engineering pipeline
Last synced: 5 months ago
JSON representation
big data
- Host: GitHub
- URL: https://github.com/isaacmg/big_data_learning
- Owner: isaacmg
- Created: 2017-01-30T00:52:17.000Z (over 9 years ago)
- Default Branch: master
- Last Pushed: 2018-11-08T04:44:05.000Z (over 7 years ago)
- Last Synced: 2025-06-23T10:52:58.153Z (about 1 year ago)
- Topics: backend, big-data, data-engineering, pipeline
- Homepage:
- Size: 17.6 KB
- Stars: 3
- Watchers: 2
- Forks: 1
- Open Issues: 0
-
Metadata Files:
- Readme: readme.md
Awesome Lists containing this project
README
# Big Data Guide
Hey everyone this is a repository where I discus Big Data technologies. It originally a rose out of my notes that I took while learning about various things. For the most part I will be focusing on Open Source Technologies and Big Data Systems design although I will briefly describe some other things. If you see anything incorrect or anything that should be added feel free to fork and make a pull request.
**Disclaimer**
This is an informal repository created in my free time. Although I try to as accurate as possible I'm not perfect. As such it is highly reccomended that you check official documentation before attempting anything. Neither myself nor any contributors can be held responsible for incorrect or wrong information.
## Table of Contents
* [Introduction and History](#intro)
* [Origins of Big Data](#orgins)
* [The Birth of Hadoop](#hadoopbirth)
* [Principals](#principals)
* [Cluster Computing Systems](#cluster)
* [HDFS](#hdfs)
* [MapReduce](#MapReduce)
* [Spark](#spark)
* [Flink](#flink)
* [Databases](#databases)
* [Neo4j](#Neo4j)
* [MongoDB](#MongoDB)
* [Cassandra](#CassandraDB)
* [Redis](#Redis)
* [HBase](#HBase)
* [SQL](#SQL)
* [Hardware](#hardware)
* [Business and Big Data](#business)
* [Job titles](#jobs)
* [Resources](#resources)
* [Conferences](#conf)
* [Blogs](#blogs)
* [Books](#books)
* [Courses](#courses)
*
## Introduction and a brief history
### The Origins of Big Data
The term Big Data most likely originated sometime in the 1990s (you can see one of the earliest PDFs on the subject [here](http://static.usenix.org/event/usenix99/invited_talks/mashey.pdf)). The term emerged in response to the growing size of data sets and the need for non-traditional methods of processing them.
### The Birth of Hadoop
Hadoop originates from the Google File System paper which was published in 2003 and the subsequent follow up paper "MapReduce: Simplified Data Processing on Large Clusters" published in December 2004. In 2006 the Hadoop subproject was created on the Apache Foundation website. The project was named after Doug Cutting, an engineer at Yahoo, son's toy elephant.
#### Further Links/References
[Hadoop on Wikipedia](https://en.wikipedia.org/wiki/Apache_Hadoop)
[History of Hadoop](https://medium.com/@markobonaci/the-history-of-hadoop-68984a11704#.69ryjh27u)
[Archived mailing list request for Hadoop](https://issues.apache.org/jira/browse/INFRA-700)
[CNBC Article on Hadoop's name](http://www.cnbc.com/id/100769719)
### Hadoop
Almost all modern big data systems in some way involve some aspect of Hadoop (or improvement of Hadoop). As such it seems most fitting to begin our discussion of big data here. The basic idea of Hadoop is to break large datasets up into small pieces and distribute them over large multi-node clusters for processing that runs concurrently. A very good repository that explains Hadoop in great detail is [Hadoop Internals](http://ercoppa.github.io/HadoopInternals/). However, I will attempt to go over its core parts.
#### MapReduce
MapReduce is the processing part of Hadoop. Although newer systems like Spark and Flink have (for the most part) made MR itself obsolete, it is essential to understanding how they work as well. Here is a basic diagram detailing the MapReduce process:
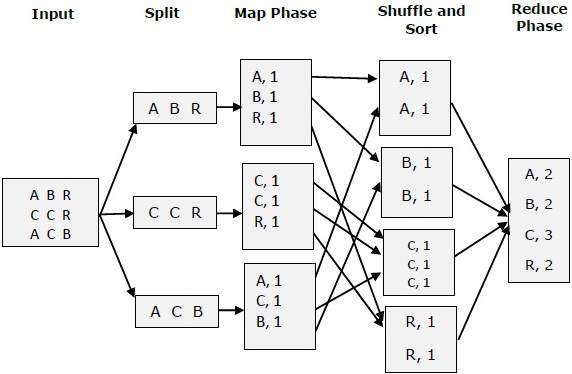
#### HDFS
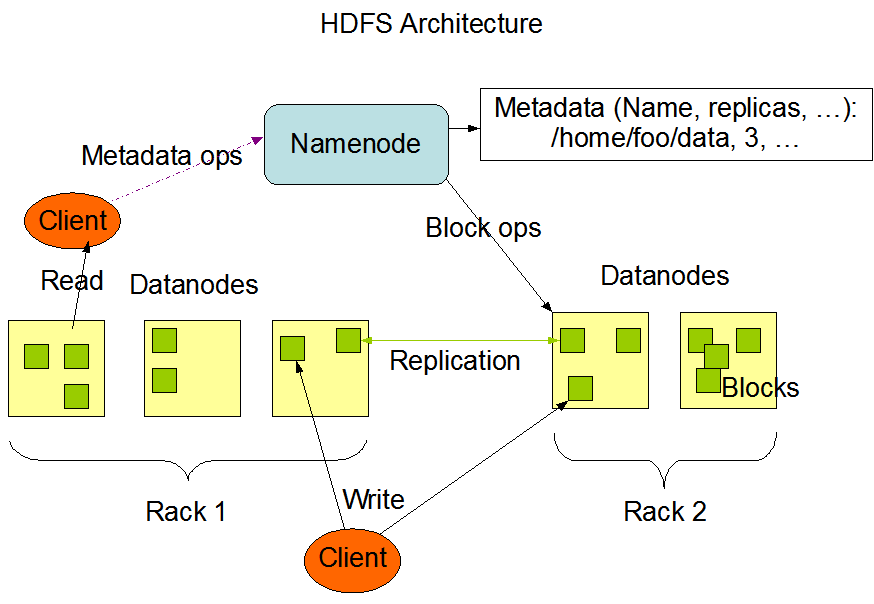
"The Hadoop Distributed File System (HDFS) is a distributed file system designed to run on commodity hardware. It has many similarities with existing distributed file systems. However, the differences from other distributed file systems are significant. HDFS is highly fault-tolerant and is designed to be deployed on low-cost hardware. HDFS provides high throughput access to application data and is suitable for applications that have large data sets. HDFS relaxes a few POSIX requirements to enable streaming access to file system data. HDFS was originally built as infrastructure for the Apache Nutch web search engine project." - Apache Website Hadoop website
As the description states HDFS is bascially the distributed storage system of Hadoop. Unlike MR HDFS is still fairly relevant as neither Flink nor Spark replace HDFS and many companies still use it either for temporary storage or as a permanent data lake configuration.
[See data lake](#datalake)
#### YARN
Apache Yarn is Hadoop's job manager.
### The Data Pipeline
Various use cases will differ however, most big data pipelines will have similar common features. For the most part they will follow the following form:
1. Data Collection
2. Ingestion from a data source (this may also been called the extraction phase)
2. Transformation/Computation
3. (Not always but most of the time) storing data
4. Serving the data to the user
### Lambda Architecture

Lambda Architecture is having both a batch processing layer for your data and a realtime layer for your data. The realtime layer sacrifices accuracy for the sake of speed while the batch layer is perfectly accurate but slow. Periodically the batch layer updates the realtime layer. The goal of this model is to preserve overall data accurcay without scarificing speed.
For more on Lambda Architecture see [Lambada Architecture](http://lambda-architecture.net)
### Real World Architectures
In practice it is usually much more complicated than this. You are often extracting data from multiple sources and combining it into one, you have several machine learning models which you train offline and need deploy etc.
[IBM Series on Big Data](http://www.ibm.com/developerworks/library/bd-archpatterns3/index.html?ca=drs-)
### Selected Examples:

**Reccomendation engine**:
Simple example:
1. Users watch various movies and rate them.
2. Rating data is stored in a database and watch/click data is generated in realtime in log files.
3. Data sources are combined and fed into a pretrained reccomendation engine.
4. Recommendations are stored and pushed back to the user.
Real world examples:
◦ [Spotify Movie Reccomendations with Spark](http://www.slideshare.net/MrChrisJohnson/collaborative-filtering-with-spark)
◦ [Comcast TV recommendations](https://spark-summit.org/2015-east/wp-content/uploads/2015/03/SSE15-18-Neumann-Alla.pdf)
◦ [Netflix Movie reccomendations with Spark and GraphX](http://www.slideshare.net/SessionsEvents ehtsham-elahi-senior-research-engineer-personalization-science-and-engineering-group-at-netflix-at-mlconf-sea-50115?next_slideshow=1) (mainly machine learning focused, but still interesting)
◦ [Caserta Movie Reccomendations](http://www.slideshare.net/CasertaConcepts/analytics-week-recommendations-on-spark)
◦ [Reccomendations at scale with Flink](http://data-artisans.com/computing-recommendations-at-extreme-scale-with-apache-flink/)
**Monitoring**
[Monitoring Traffic Data](https://www.mapr.com/blog/monitoring-real-time-uber-data-using-spark-machine-learning-streaming-and-kafka-api-part-1)
## Distributed Computing
### Clasic MapReduce
### Spark
#### Overview
Spark is a newer cluster computing platform orginally started in 2009 and later added as an Apache Open Source Project in 2013. Spark was built specifically as an attempt to provide flexibility in contrast to the rigid structure of the MapReduce framework. Spark relies on Resilent Distrbuted Datasets (RDDs) as it main data structure. According to the offical Spark website "RDDs are fault-tolerant, parallel data structures that let users explicitly persist intermediate results in memory, control their partitioning to optimize data placement, and manipulate them using a rich set of operators." The RDD data structure provides significant speed advantages over MR in Hadoop due to its configuration. The following images show a breakdown of MR in Hadoop vs Spark.


[YouTube video describing differences of Spark vs Hadoop](https://www.youtube.com/watch?v=KzFe4T0PwQ8)
#### SQL and Dataframes
"Spark SQL is a Spark module for structured data processing. Unlike the basic Spark RDD API, the interfaces provided by Spark SQL provide Spark with more information about the structure of both the data and the computation being performed. Internally, Spark SQL uses this extra information to perform extra optimizations. There are several ways to interact with Spark SQL including SQL and the Dataset API. When computing a result the same execution engine is used, independent of which API/language you are using to express the computation. This unification means that developers can easily switch back and forth between different APIs based on which provides the most natural way to express a given transformation."
#### MLLIB
#### Streaming
#### GraphX
#### PySpark
Find Spark is very useful for finding PySpark on your installation if you run in to problems. You can get it here https://github.com/minrk/findspark.
### Flink
#### Flink vs Spark
A lot of people have debated whether they should use Spark or Flink. Here are a few articles and slideshows that discus the differences:
[Infoworld Flink vs Spark](http://www.infoworld.com/article/2919602/hadoop/flink-hadoops-new-contender-for-mapreduce-spark.html)
[Stack Overflow answer](http://stackoverflow.com/questions/28082581/what-is-the-difference-between-apache-spark-and-apache-flink)
[Capital One slideshow on the topic](http://www.slideshare.net/sbaltagi/flink-vs-spark)
#### Installing Flink
[How to install Flink on Windows ](https://ci.apache.org/projects/flink/flink-docs-release-0.8/local_setup.html)
## Databases
### NoSQL
#### Neo4j

Neo4j is a graph database that can be used for either storage for analytical purposes or serving as the primary database for a website. As a graph database it is best suited for applications that have natural graph structures such as social networks or any other type of network. The database is composed of nodes and relationships between nodes. Neo4j has its own query language known as CQL or Cypher Query Language not to be confused with CQL Cassandra query language.
**Relevant Links**
[Neo4j official website](https://neo4j.com)
[Building a simple reccomendation engine with Neo4j](https://medium.com/@paddlesoft/building-a-recommendation-engine-with-neo4j-part-1-simple-graph-based-approaches-16c3cea32ff#.f7243ljkt)
[Integrating Neo4j with Spark Graph X](http://www.kennybastani.com/2014/11/using-apache-spark-and-neo4j-for-big.html)
[Managing genetic ancestry at scale with Neo4j and Kafka](http://stampedecon.com/big-data-conference-2015/sessions/managing-genetic-ancestry-at-scale-with-neo4j-and-kafka/)
["PoptoJS a JS library to build a graph search with Neo4j](http://www.popotojs.com)
[Neo4j Kafka](https://www.linkedin.com/pulse/neo4j-real-time-graph-analytics-update-1m-nodes-90-moore-ph-d-)
** Relevant Links **
[MongoDB offical website](https://www.mongodb.com)
Cassandra is a large scale distibuted database built for web and mobile applications (in contrast to HBase). While Cassandra integrates well with Hadoop it has a reputation of being incredibly difficult to use.
**Relevant Link**
[Official site](http://cassandra.apache.org)
[Netflix Cassandra Pipeline](http://techblog.netflix.com/2012/02/aegisthus-bulk-data-pipeline-out-of.html)
[Cassandra Summit Netflix and Reccomendations + others in playlist](https://www.youtube.com/watch?v=SxU0CJJ2nVE&list=PLm-EPIkBI3YoiA-02vufoEj4CgYvIQgIk&index=3)
[Getting started with Cassandra](https://www.codementor.io/sheena/installing-cassandra-spark-linux-debian-ubuntu-14-du107vbhx)
#### Redis

[Official Site](https://redis.io)
[Scaling Redis cluster for Genome Analysis](https://www.youtube.com/watch?v=g69-3He_IYs)
[When and Why you should use Redis](https://www.youtube.com/watch?v=CoQcNgfPYPc)
HBase is a column oriented DB that run on top of HDFS. In contrast to Cassandra HBase it is mainly made for analytical purposes and is not a full production database system. It often comes in many Hadoop distributions as default.
** Relevant Sites **
[Official Site](https://hbase.apache.org)
[IBM Article on HBase](https://www-01.ibm.com/software/data/infosphere/hadoop/hbase/)
### SQL Databases
Love them or hate them SQL databases are around to stay. Almost all organizations use them to store data in some capacity or another. Therefore it's very important to learn how to integrate them into our big data architectures.
## Messaging/Real time streaming data
### Flume
### Kafka
## Workflow Software
### Nifi
### Airflow
Attention if you install Airflow with pip you will have to find the base directory pip installed it to. In my case it was \usr\local\lib\python2.7\dist-packages\airflow
## Languages
### Python
### Scala
### Java
### R
## Creating, training, deploying, and managing, machine learning models
As there are already many excellent repositories dedicated to ML algorithms. Here I will be discussing how ML models are integrated into big data architecture.
### Getting training data
For purposes of training/analysis you are usually going to have a secondary pipeline seperate from your production/client serving pipeline. This will be the pipeline that data scientists and business intelligence people utilize for getting data either for training or analysis.

### Deploying to production
### Monitoring performance
### PipelineIO
## Data Visualization
[Realtime time visualization with D3JS and Kafka](http://www.slideshare.net/BenLaird/real-time-data-viz-with-spark-streaming-kafka-and-d3js)
[Using Kafka and HBase to power a realtime analytics dashboard](https://www.sigmoid.com/integrating-spark-kafka-hbase-to-power-a-real-time-dashboard/)
## Business and Big Data

### Job Roles
[The Rise of the Data Engineer on Medium](https://medium.freecodecamp.com/the-rise-of-the-data-engineer-91be18f1e603#.7v0hp99i0)+
[Differences between job positions](https://bigdatauniversity.com/blog/data-scientist-vs-data-engineer/)
[Data Analyst vs Scientist](https://www.import.io/post/data-scientists-vs-data-analysts-why-the-distinction-matters/)
## Hardware
### GPUs and Big Data
[Overview]("http://www.nvidia.com/object/data-science-analytics-database.html")
[GPUs and Big Data]("http://www.hpl.hp.com/techreports/2009/HPL-2009-38.pdf")
### Setting up a Hadoop Cluster
[Setting up your own small Hadoop cluster] (http://www.oneillscrossing.com/home-built-hadoop-analytics-cluster/#Hardware_310_per_node)
## More Real World Examples
### Architectures/Backbones
### Reccomendations
### Monitoring
### Machine Learning
### Other
## Resources
### Conferences
[Open Data Science](http://opendatascience.com)
[Flink Forward](http://flink-forward.org)
[Kafka Summit](https://kafka-summit.org)
[Rec Systems](https://recsys.acm.org)
[Spark Summit](https//spark-summit.org)
### Interesting Blogs
The following are some interesting engineering blogs that often have posts regarding big data technologies.
[PaddleSoft](http://medium.com/@paddlesoft)
[Lyft](https://eng.lyft.com)
[Netflix](http://http://techblog.netflix.com)
[Uber](http://https://eng.uber.com)
[Yelp](https://engineeringblog.yelp.com)
[eHarmony](http://www.eharmony.com/engineering/)
### Books
### Courses


