https://github.com/itsjafer/jupyterlab-sparkmonitor
JupyterLab extension that enables monitoring launched Apache Spark jobs from within a notebook
https://github.com/itsjafer/jupyterlab-sparkmonitor
apache-spark jupyter jupyter-lab jupyterlab jupyterlab-extension pyspark spark
Last synced: about 1 year ago
JSON representation
JupyterLab extension that enables monitoring launched Apache Spark jobs from within a notebook
- Host: GitHub
- URL: https://github.com/itsjafer/jupyterlab-sparkmonitor
- Owner: itsjafer
- License: apache-2.0
- Created: 2020-03-12T20:59:01.000Z (over 6 years ago)
- Default Branch: master
- Last Pushed: 2022-12-27T15:34:10.000Z (over 3 years ago)
- Last Synced: 2025-03-26T23:06:44.218Z (over 1 year ago)
- Topics: apache-spark, jupyter, jupyter-lab, jupyterlab, jupyterlab-extension, pyspark, spark
- Language: JavaScript
- Homepage: https://krishnan-r.github.io/sparkmonitor/
- Size: 4.08 MB
- Stars: 92
- Watchers: 7
- Forks: 23
- Open Issues: 12
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
- awesome-jupyter-resources - GitHub - 50% open · ⏱️ 01.04.2022): (JupyterLab扩展)
README
# Spark Monitor - An extension for Jupyter Lab
This project was originally written by krishnan-r as a Google Summer of Code project for Jupyter Notebook. [Check his website out here.](https://krishnan-r.github.io/sparkmonitor/)
As a part of my internship as a Software Engineer at Yelp, I created this fork to update the extension to be compatible with JupyterLab - Yelp's choice for sharing and collaborating on notebooks.
## About

+

=

SparkMonitor is an extension for Jupyter Lab that enables the live monitoring of Apache Spark Jobs spawned from a notebook. The extension provides several features to monitor and debug a Spark job from within the notebook interface itself.
---
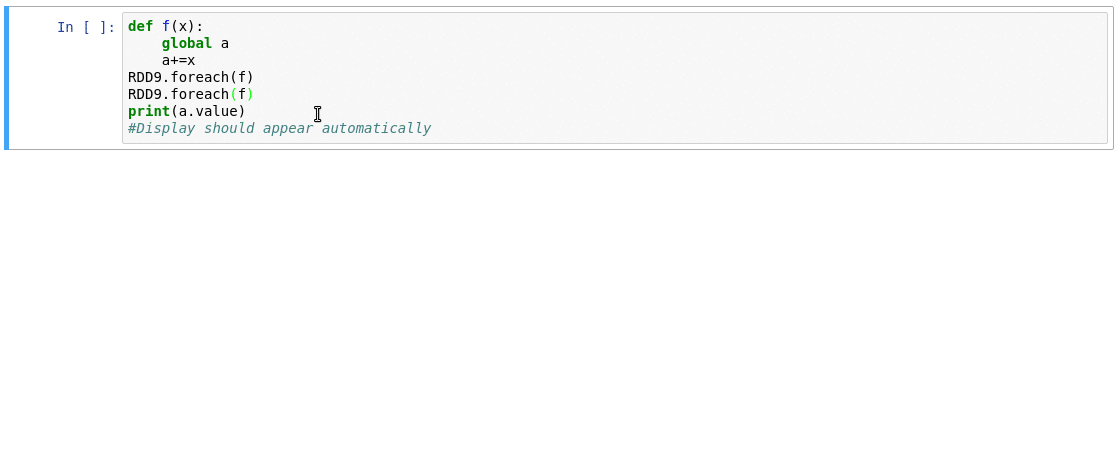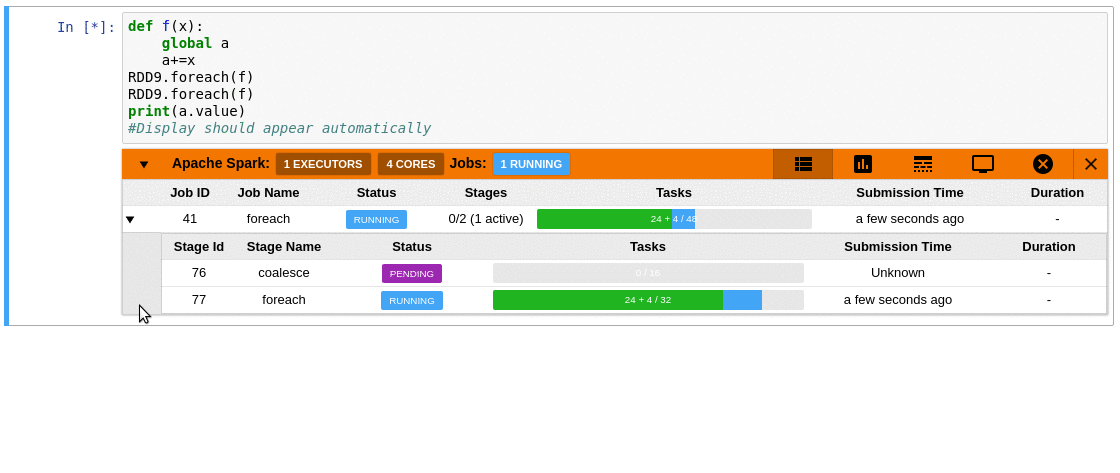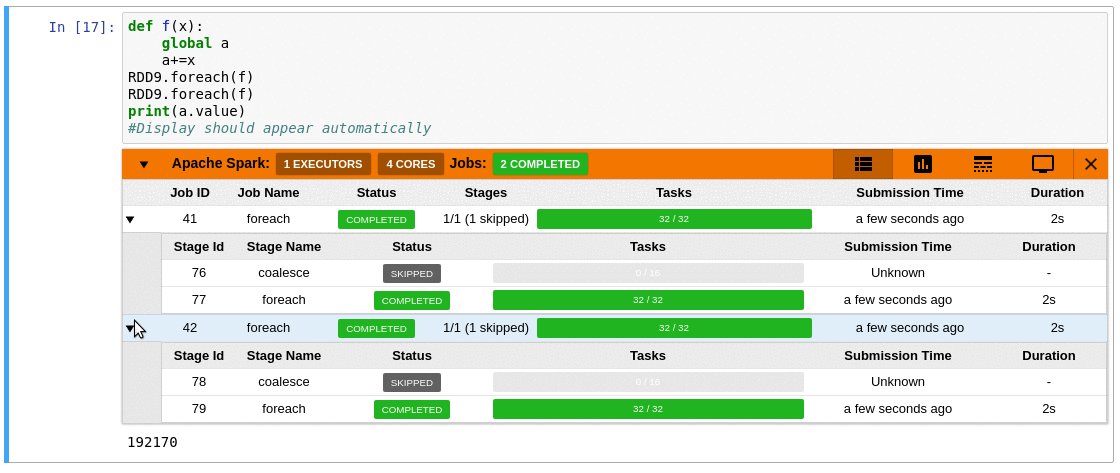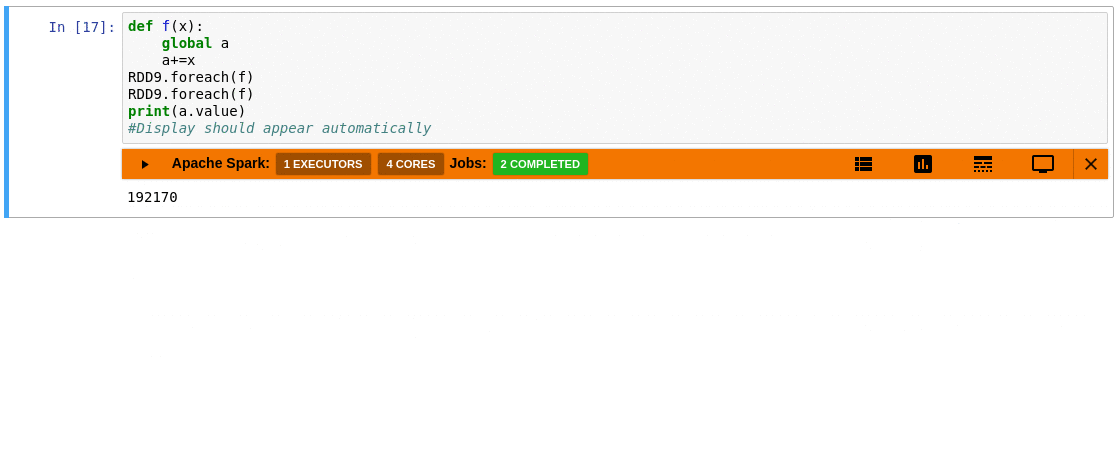
### Requirements
- At least JupyterLab 3
- pyspark 3.X.X or newer (For compatibility with older pyspark versions, use jupyterlab-sparkmonitor 3.X)
## Features
- Automatically displays a live monitoring tool below cells that run Spark jobs in a Jupyter notebook
- A table of jobs and stages with progressbars
- A timeline which shows jobs, stages, and tasks
- A graph showing number of active tasks & executor cores vs time
- A notebook server extension that proxies the Spark UI and displays it in an iframe popup for more details
- For a detailed list of features see the use case [notebooks](https://krishnan-r.github.io/sparkmonitor/#common-use-cases-and-tests)
- Support for multiple SparkSessions (default port is 4040)
- [How it Works](https://krishnan-r.github.io/sparkmonitor/how.html)





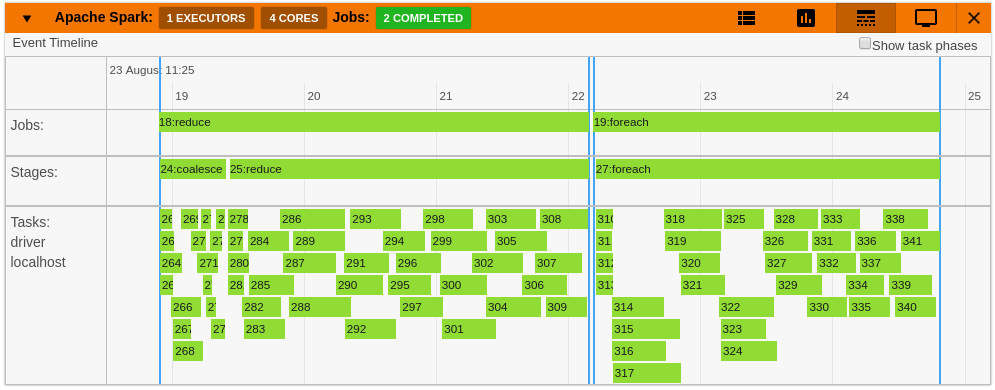
## Quick Start
### To do a quick test of the extension
This docker image has pyspark and several other related packages installed alongside the sparkmonitor extension.
```bash
docker run -it -p 8888:8888 itsjafer/sparkmonitor
```
### Setting up the extension
```bash
pip install jupyterlab-sparkmonitor # install the extension
# set up ipython profile and add our kernel extension to it
ipython profile create --ipython-dir=.ipython
echo "c.InteractiveShellApp.extensions.append('sparkmonitor.kernelextension')" >> .ipython/profile_default/ipython_config.py
# run jupyter lab
IPYTHONDIR=.ipython jupyter lab --watch
```
With the extension installed, a SparkConf object called `conf` will be usable from your notebooks. You can use it as follows:
```python
from pyspark import SparkContext
# start the spark context using the SparkConf the extension inserted
sc=SparkContext.getOrCreate(conf=conf) #Start the spark context
# Monitor should spawn under the cell with 4 jobs
sc.parallelize(range(0,100)).count()
sc.parallelize(range(0,100)).count()
sc.parallelize(range(0,100)).count()
sc.parallelize(range(0,100)).count()
```
If you already have your own spark configuration, you will need to set `spark.extraListeners` to `sparkmonitor.listener.JupyterSparkMonitorListener` and `spark.driver.extraClassPath` to the path to the sparkmonitor python package `path/to/package/sparkmonitor/listener.jar`
```python
from pyspark.sql import SparkSession
spark = SparkSession.builder\
.config('spark.extraListeners', 'sparkmonitor.listener.JupyterSparkMonitorListener')\
.config('spark.driver.extraClassPath', 'venv/lib/python3.7/site-packages/sparkmonitor/listener.jar')\
.getOrCreate()
# should spawn 4 jobs in a monitor bnelow the cell
spark.sparkContext.parallelize(range(0,100)).count()
spark.sparkContext.parallelize(range(0,100)).count()
spark.sparkContext.parallelize(range(0,100)).count()
spark.sparkContext.parallelize(range(0,100)).count()
```
## Changelog
* 1.0 - Initial Release
* 2.0 - Migration to JupyterLab 2, Multiple Spark Sessions, and displaying monitors beneath the correct cell more accurately
* 3.0 - Migrate to JupyterLab 3 as prebuilt extension
* 4.0 - pyspark 3.X Compatibility; no longer compatible with PySpark 2.X or under
## Development
If you'd like to develop the extension:
```bash
make all # Clean the directory, build the extension, and run it locally
```