https://github.com/ivan-sincek/chad
Search Google Dorks like Chad. / Broken link hijacking tool.
https://github.com/ivan-sincek/chad
broken-link-takeover bug-bounty crawler ethical-hacking google google-dorking google-dorks offensive-security penetration-testing playwright python red-team-engagement scraper search-engine security social-media social-media-takeover threat-hunting threat-intelligence web-penetration-testing
Last synced: 4 months ago
JSON representation
Search Google Dorks like Chad. / Broken link hijacking tool.
- Host: GitHub
- URL: https://github.com/ivan-sincek/chad
- Owner: ivan-sincek
- License: mit
- Created: 2022-09-02T20:41:22.000Z (almost 4 years ago)
- Default Branch: main
- Last Pushed: 2025-09-21T16:22:17.000Z (10 months ago)
- Last Synced: 2025-09-21T18:25:37.495Z (10 months ago)
- Topics: broken-link-takeover, bug-bounty, crawler, ethical-hacking, google, google-dorking, google-dorks, offensive-security, penetration-testing, playwright, python, red-team-engagement, scraper, search-engine, security, social-media, social-media-takeover, threat-hunting, threat-intelligence, web-penetration-testing
- Language: Python
- Homepage:
- Size: 1.01 MB
- Stars: 30
- Watchers: 1
- Forks: 5
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
- awesome-hacking-lists - ivan-sincek/chad - Search Google Dorks like Chad. / Broken link hijacking tool. (Python)
README
# Chad
Search Google Dorks like Chad. Based on [ivan-sincek/nagooglesearch](https://github.com/ivan-sincek/nagooglesearch).
Google frequently changes cookies, so you will need to specify your own using the `-b` option if the default ones stop working and you keep getting no results. Example cookies can be found [here](https://github.com/ivan-sincek/nagooglesearch/blob/main/src/nagooglesearch/nagooglesearch.py#L169). Note that Google frequently changes cookie names, adds new ones, and removes old ones.
Tested on Kali Linux v2024.2 (64-bit).
Made for educational purposes. I hope it will help!
Future plans:
* Chad Extractor:
* check if Playwright's Chromium headless browser is installed or not,
* add option to stop on rate limiting,
* find a way to bypass the auth. wall for `linkedin-user`.
## Table of Contents
* [How to Install](#how-to-install)
* [Install Playwright and Chromium](#install-playwright-and-chromium)
* [Standard Install](#standard-install)
* [Build and Install From the Source](#build-and-install-from-the-source)
* [Shortest Possible](#shortest-possible)
* [File Download](#file-download)
* [Chad Extractor](#chad-extractor)
* [Broken Link Hijacking](#broken-link-hijacking)
* [Single Site](#single-site)
* [Multiple Sites](#multiple-sites)
* [Analyzing the Report](#analyzing-the-report)
* [Rate Limiting](#rate-limiting)
* [Usage](#usage)
* [Images](#images)
## How to Install
### Install Playwright and Chromium
```bash
pip3 install --upgrade playwright
playwright install chromium
```
Make sure each time you upgrade your Playwright dependency to re-install Chromium; otherwise, you might get an error using the headless browser in Chad Extractor.
### Standard Install
```bash
pip3 install --upgrade google-chad
```
### Build and Install From the Source
```bash
git clone https://github.com/ivan-sincek/chad && cd chad
python3 -m pip install --upgrade build
python3 -m build
python3 -m pip install dist/google_chad-7.5-py3-none-any.whl
```
## Shortest Possible
```bash
chad -q 'intitle:"index of /" intext:"parent directory"'
```
Google frequently changes cookies, so you may need to specify your own using the `-b` option if the default ones no longer work - if you keep getting no results.
Default cookies can be found at [here](https://github.com/ivan-sincek/nagooglesearch/blob/main/src/nagooglesearch/nagooglesearch.py#L169).
## File Download
Did you say Metagoofil?!
```bash
mkdir downloads
chad -q "ext:pdf OR ext:docx OR ext:xlsx OR ext:pptx" -s *.example.com -tr 200 -dir downloads
```
Chad's file download feature is based on Python Requests dependency.
## Chad Extractor
Chad Extractor is a powerful tool based on [Scrapy's](https://scrapy.org) web crawler and [Playwright's](https://playwright.dev/python) Chromium headless browser, designed to efficiently scrape web content; unlike Python Requests dependency, which cannot render JavaScript encoded HTML and is easily blocked by anti-bot solutions.
Primarily, Chad Extractor is designed to extract and validate data from Chad results files. However, it can also be used to extract and validate data from plaintext files by using the `-pt` option.
If the `-pt` option is used, plaintext files will be treated like server responses, and the extraction logic will be applied, followed by validation. This is also useful if you want to re-test previous Chad Extractor's reports, e.g., by using `-res report.json -pt -o retest.json`.
## Broken Link Hijacking
Prepare the Google Dorks as [social_media_dorks.txt](https://github.com/ivan-sincek/chad/blob/main/src/dorks/social_media_dorks.txt) file:
```fundamental
intext:"t.me/"
intext:"discord.com/invite/" OR intext:"discord.gg/invite/"
intext:"youtube.com/c/" OR intext:"youtube.com/channel/"
intext:"twitter.com/" OR intext:"x.com/"
intext:"facebook.com/"
intext:"instagram.com/"
intext:"tiktok.com/"
intext:"linkedin.com/in/" OR intext:"linkedin.com/company/"
```
Prepare the template as [social_media_template.json](https://github.com/ivan-sincek/chad/blob/main/src/templates/social_media_template.json) file:
```json
{
"telegram": {
"extract": "t\\.me\\/(?:(?!(?:share)(?:(?:\\/|\\?|\\\\|\"|\\<)*$|(?:\\/|\\?|\\\\|\\\"|\\<)[\\s\\S]))[\\w\\d\\.\\_\\-\\+\\@]+)(?"
},
"discord": {
"extract": "discord\\.(?:com|gg)\\/invite\\/[\\w\\d\\.\\_\\-\\+\\@]+(?",
"validate_cookies": {
"SOCS": "CAESEwgDEgk2OTk3ODk2MzcaAmVuIAEaBgiAn5S6Bg"
}
},
"twitter": {
"extract": "(?<=(?Table 1 - Template Attributes
### Single Site
```bash
chad -q social_media_dorks.txt -s *.example.com -tr 200 -pr 100 -o results.json
chad-extractor -t social_media_template.json -res results.json -o report.json
```
### Multiple Sites
Prepare the domains / subdomains as `sites.txt` file, the same way you would use them with the `site:` option in Google:
```fundamental
*.example.com
*.example.com -www
```
Run:
```bash
mkdir chad_results
IFS=$'\n'; count=0; for site in $(cat sites.txt); do count=$((count+1)); echo "#${count} | ${site}"; chad -q social_media_dorks.txt -s "${site}" -tr 200 -pr 100 -o "chad_results/results_${count}.json"; done
chad-extractor -t social_media_template.json -res chad_results -o report.json -v
```
### Analyzing the Report
Manually verify if the broken social media URLs in `results[summary][validated]` are vulnerable to takeover:
```json
{
"started_at":"2023-12-23 03:30:10",
"ended_at":"2023-12-23 04:20:00",
"summary":{
"validated":[
"https://t.me/does_not_exist" // might be vulnerable to takeover
],
"extracted":[
"https://discord.com/invite/exists",
"https://t.me/does_not_exist",
"https://t.me/exists"
]
},
"failed":{
"validation":[],
"extraction":[]
},
"full":[
{
"url":"https://example.com/about",
"results":{
"telegram":[
"https://t.me/does_not_exist",
"https://t.me/exists"
],
"discord":[
"https://discord.com/invite/exists"
]
}
}
]
}
```
### Rate Limiting
Google's cooling-off period can range from a few hours to a whole day.
To avoid hitting Google's rate limits with Chad, increase the minimum and maximum sleep between Google queries and/or pages; or use free or paid proxies. However, free proxies are often blocked and unstable.
To download a list of free proxies, run:
```bash
curl -s 'https://proxylist.geonode.com/api/proxy-list?limit=50&page=1&sort_by=lastChecked&sort_type=desc' -H 'Referer: https://proxylist.geonode.com/' | jq -r '.data[] | "\(.protocols[])://\(.ip):\(.port)"' > proxies.txt
```
**If you are using proxies, you might want to increase the request timeout, as responses will need longer time to arrive.**
Additionally, to avoid hitting rate limits on platforms like [Instagram's](https://www.instagram.com) while using Chad Extractor, consider decreasing the number of concurrent requests per domain and increasing the sleep and wait times.
## Usage
```fundamental
Chad v7.5 ( github.com/ivan-sincek/chad )
Usage: chad -q queries [-s site ] [-x proxies ] [-o out ]
Example: chad -q queries.txt [-s *.example.com] [-x proxies.txt] [-o results.json]
DESCRIPTION
Search Google Dorks like Chad
QUERIES
File containing Google Dorks or a single query to use
-q, --queries = queries.txt | intext:password | "ext:tar OR ext:zip" | etc.
SITE
Domain[s] to search
-s, --site = example.com | sub.example.com | *.example.com | "*.example.com -www" | etc.
TIME
Get results not older than the specified time in months
-t, --time = 6 | 12 | 24 | etc.
TOTAL RESULTS
Total number of unique results
Default: 100
-tr, --total-results = 200 | etc.
PAGE RESULTS
Number of results per page - capped at 100 by Google
Default: randint(70, 100)
-pr, --page-results = 50 | etc.
MINIMUM QUERIES
Minimum sleep time in seconds between Google queries
Default: 75
-min-q, --minimum-queries = 120 | etc.
MAXIMUM QUERIES
Maximum sleep time between Google queries
Default: minimum + 50
-max-q, --maximum-queries = 180 | etc.
MINIMUM PAGES
Minimum sleep time between Google pages
Default: 15
-min-p, --minimum-pages = 30 | etc.
MAXIMUM PAGES
Maximum sleep time between Google pages
Default: minimum + 10
-max-p, --maximum-pages = 60 | etc.
COOKIE
Specify any number of extra HTTP cookies
Google frequently changes cookies, so you may need to specify your own if the default ones no longer work
-b, --cookie = SOCS=3301 | etc.
USER AGENTS
User agents to use
Default: random-all
-a, --user-agents = user_agents.txt | random[-all] | curl/3.30.1 | etc.
PROXIES
File containing web proxies or a single web proxy to use
-x, --proxies = proxies.txt | http://127.0.0.1:8080 | etc.
DIRECTORY
Downloads directory
All downloaded files will be saved in this directory
-dir, --directory = downloads | etc.
THREADS
Number of files to download in parallel
Default: 5
-th, --threads = 20 | etc.
OUT
Output file
-o, --out = results.json | etc.
NO SLEEP ON START
Disable the safety feature to prevent triggering rate limits by accident
-nsos, --no-sleep-on-start
DEBUG
Enable debug output
-dbg, --debug
```
```fundamental
Chad Extractor v7.5 ( github.com/ivan-sincek/chad )
Usage: chad-extractor -t template -res results -o out [-s sleep] [-rs random-sleep]
Example: chad-extractor -t template.json -res chad_results -o report.json [-s 1.5 ] [-rs ]
DESCRIPTION
Extract and validate data from Chad results or plaintext files
TEMPLATE
File containing extraction and validation details
-t, --template = template.json | etc.
RESULTS
Directory containing Chad results or plaintext files, or a single file
If a directory is specified, files ending with '.report.json' will be ignored
-res, --results = chad_results | results.json | urls.txt | etc.
PLAINTEXT
Treat all the results as plaintext files / server responses
-pt, --plaintext
EXCLUDES
File containing regular expressions or a single regular expression to exclude content from the page
Applies only for extraction
-e, --excludes = regexes.txt | "
.+?<\/div>" | etc.
PLAYWRIGHT
Use Playwright's headless browser
Applies only for extraction
-p, --playwright
PLAYWRIGHT WAIT
Wait time in seconds before fetching the page content
Applies only for extraction
-pw, --playwright-wait = 0.5 | 2 | 4 | etc.
CONCURRENT REQUESTS
Number of concurrent requests
Default: 15
-cr, --concurrent-requests = 30 | 45 | etc.
CONCURRENT REQUESTS PER DOMAIN
Number of concurrent requests per domain
Default: 5
-crd, --concurrent-requests-domain = 10 | 15 | etc.
SLEEP
Sleep time in seconds between two consecutive requests to the same domain
-s, --sleep = 1.5 | 3 | etc.
RANDOM SLEEP
Randomize the sleep time between requests to vary between '0.5 * sleep' and '1.5 * sleep'
-rs, --random-sleep
AUTO THROTTLE
Auto throttle concurrent requests based on the load and latency
Sleep time is still respected
-at, --auto-throttle = 0.5 | 10 | 15 | 45 | etc.
RETRIES
Number of retries per URL
Default: 2
-r, --retries = 0 | 4 | etc.
REQUEST TIMEOUT
Request timeout in seconds
Default: 60
-rt, --request-timeout = 30 | 90 | etc.
USER AGENTS
User agents to use
Default: random-all
-a, --user-agents = user_agents.txt | random[-all] | curl/3.30.1 | etc.
PROXY
Web proxy to use
-x, --proxy = http://127.0.0.1:8080 | etc.
OUT
Output file
-o, --out = report.json | etc.
VERBOSE
Create additional supporting output files that end with '.report.json'
-v, --verbose
DEBUG
Enable debug output
-dbg, --debug
```
## Images
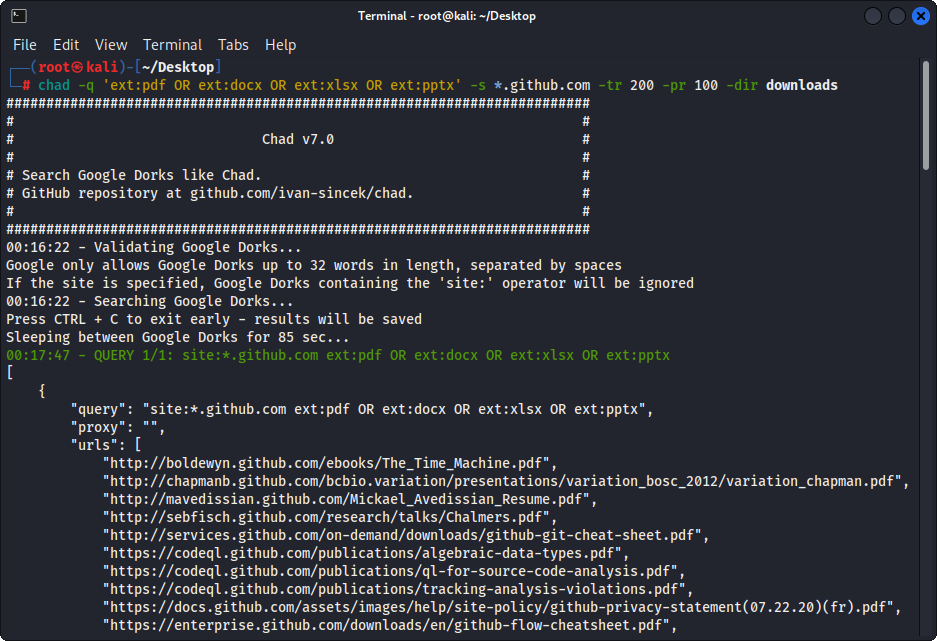
Figure 1 - (Chad) File Download - Single Google Dork
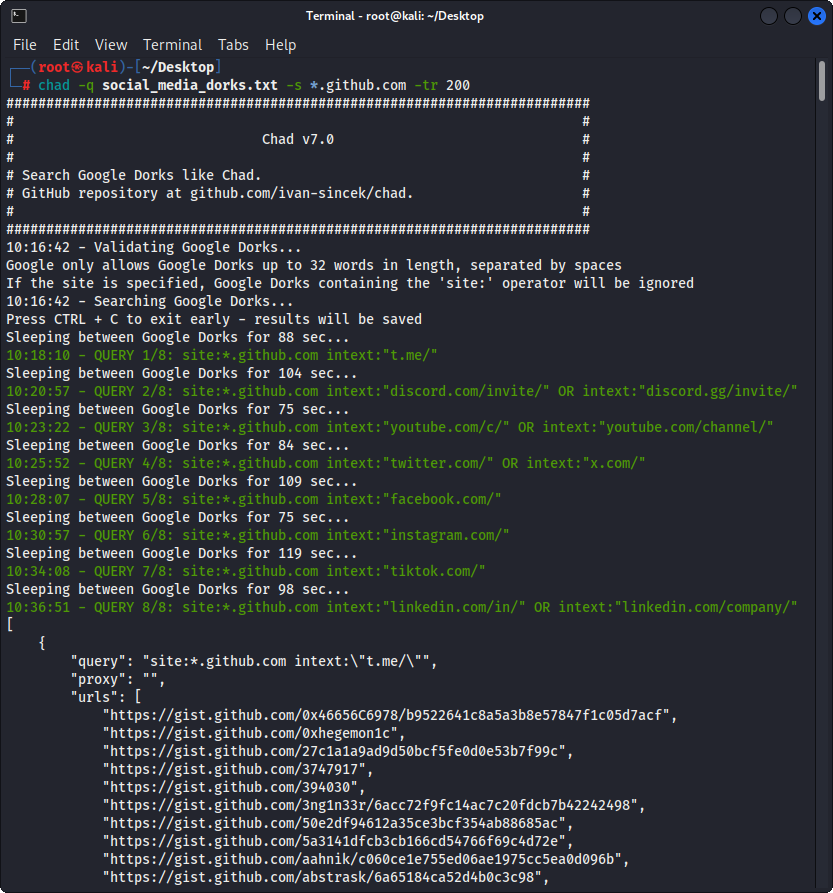
Figure 2 - (Chad) Broken Link Hijacking - Multiple Google Dorks
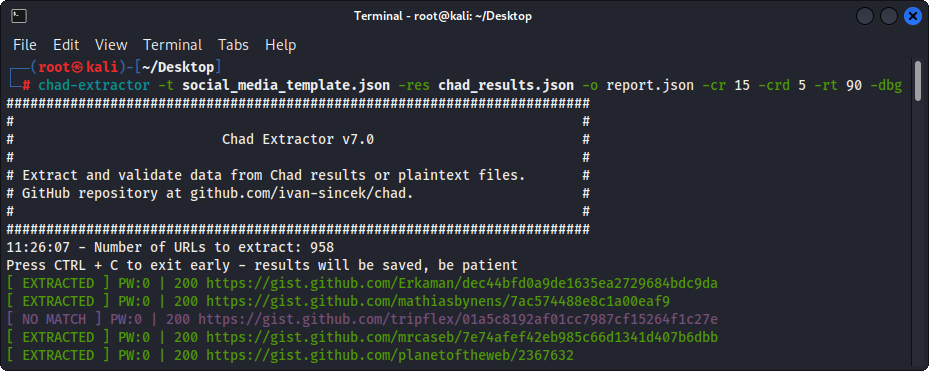
Figure 3 - (Chad Extractor) Extraction
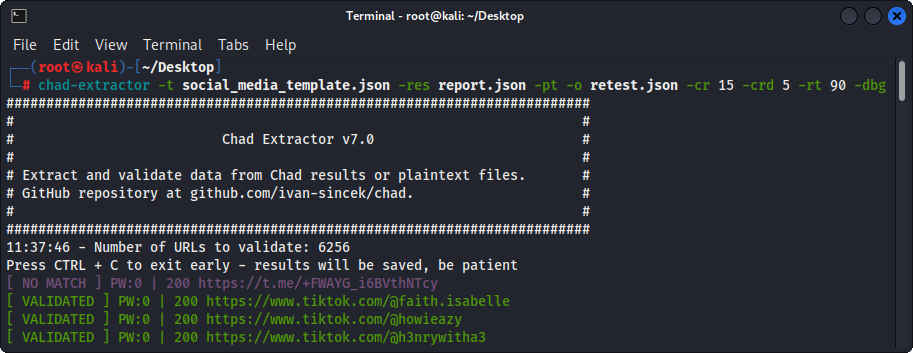
Figure 4 - (Chad Extractor) Validation