https://github.com/jackaduma/las_mandarin_pytorch
Listen, attend and spell Model and a Chinese Mandarin Pretrained model (中文-普通话 ASR模型)
https://github.com/jackaduma/las_mandarin_pytorch
asr chinese-speech-recognition deep-learning deeplearning listen-attend-and-spell mandarin pytorch-implementation speech-recognition speech-to-text
Last synced: about 1 year ago
JSON representation
Listen, attend and spell Model and a Chinese Mandarin Pretrained model (中文-普通话 ASR模型)
- Host: GitHub
- URL: https://github.com/jackaduma/las_mandarin_pytorch
- Owner: jackaduma
- License: mit
- Created: 2020-05-13T11:38:50.000Z (about 6 years ago)
- Default Branch: master
- Last Pushed: 2023-04-28T22:19:39.000Z (about 3 years ago)
- Last Synced: 2023-11-07T18:24:45.984Z (over 2 years ago)
- Topics: asr, chinese-speech-recognition, deep-learning, deeplearning, listen-attend-and-spell, mandarin, pytorch-implementation, speech-recognition, speech-to-text
- Language: Python
- Homepage:
- Size: 448 KB
- Stars: 111
- Watchers: 4
- Forks: 16
- Open Issues: 6
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# **LAS_Mandarin_PyTorch**
[](https://github.com/jackaduma/LAS_Mandarin_PyTorch)
[**中文说明**](./README.zh-CN.md) | [**English**](./README.md)
This code is a PyTorch implementation for paper: [**Listen, Attend and Spell**](https://arxiv.org/abs/1508.01211]), a nice work on End-to-End **ASR**, **Speech Recognition** model.
also provides a **Chinese Mandarin ASR** pretrained model.
- [x] Dataset
- [ ] [LibriSpeech]() for English Speech Recognition
- [x] [AISHELL-Speech](https://openslr.org/33/) for Chinese Mandarin Speech Recognition
- [x] Usage
- [x] generate vocab file
- [x] training
- [x] test
- [ ] infer
- [ ] Demo
------
## **Listen-Attend-Spell**
### **Google Blog Page**
[Improving End-to-End Models For Speech Recognition](https://ai.googleblog.com/2017/12/improving-end-to-end-models-for-speech.html)
The LAS architecture consists of 3 components. The listener encoder component, which is similar to a standard AM, takes the a time-frequency representation of the input speech signal, x, and uses a set of neural network layers to map the input to a higher-level feature representation, henc. The output of the encoder is passed to an attender, which uses henc to learn an alignment between input features x and predicted subword units {yn, … y0}, where each subword is typically a grapheme or wordpiece. Finally, the output of the attention module is passed to the speller (i.e., decoder), similar to an LM, that produces a probability distribution over a set of hypothesized words.
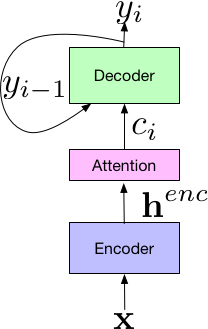
Components of the LAS End-to-End Model.
------
**This repository contains:**
1. [model code](core) which implemented the paper.
2. [generate vocab file](generate_vocab_file.py), you can use to generate your vocab file for [your dataset](dataset).
3. [training scripts](train_asr.py) to train the model.
4. [testing scripts](test_asr.py) to test the model.
------
## **Table of Contents**
- [**LAS\_Mandarin\_PyTorch**](#las_mandarin_pytorch)
- [**Listen-Attend-Spell**](#listen-attend-spell)
- [**Google Blog Page**](#google-blog-page)
- [**Table of Contents**](#table-of-contents)
- [**Requirement**](#requirement)
- [**Usage**](#usage)
- [**preprocess**](#preprocess)
- [**train**](#train)
- [**test**](#test)
- [**Pretrained**](#pretrained)
- [**English**](#english)
- [**Chinese Mandarin**](#chinese-mandarin)
- [**Demo**](#demo)
- [**Star-History**](#star-history)
- [**Reference**](#reference)
- [Donation](#donation)
- [**License**](#license)
------
## **Requirement**
```bash
pip install -r requirements.txt
```
## **Usage**
### **preprocess**
First, we should generate our vocab file from dataset's transcripts file. Please reference code in [generate_vocab_file.py](generate_vocab_file.py). If you want train aishell data, you can use [generate_vocab_file_aishell.py](generate_vocab_file_aishell.py) directly.
```python
python generate_vocab_file_aishell.py --input_file $DATA_DIR/data_aishell/transcript_v0.8.txt --output_file ./aishell_vocab.txt --mode character --vocab_size 5000
```
it will create a vocab file named **aishell_vocab.txt** in your folder.
### **train**
Before training, you need to write your dataset code in package [dataset](dataset).
If you want use my aishell dataset code, you also should take care about the transcripts file path in [data/aishell.py](dataset/aishell.py) line 26:
```python
src_file = "/data/Speech/SLR33/data_aishell/" + "transcript/aishell_transcript_v0.8.txt"
```
When ready.
Let's train:
```bash
python main.py --config ./config/aishell_asr_example_lstm4atthead1.yaml
```
you can write your config file, please reference [config/aishell_asr_example_lstm4atthead1.yaml](config/aishell_asr_example_lstm4atthead1.yaml)
specific variables: corpus's path & vocab_file
### **test**
```bash
python main.py --config ./config/aishell_asr_example_lstm4atthead1.yaml --test
```
------
## **Pretrained**
### **English**
### **Chinese Mandarin**
a pretrained model training on AISHELL-Dataset
download from [Google Drive](https://drive.google.com/file/d/1Lcu6aFdoChvKEHuBs5_efNSk5edVkeyR/view?usp=sharing)
------
## **Demo**
inference:
```bash
python infer.py
```
------
## **Star-History**

------
## **Reference**
1. [**Listen, Attend and Spell**](https://arxiv.org/abs/1508.01211v2), W Chan et al.
2. [Neural Machine Translation of Rare Words with Subword Units](http://www.aclweb.org/anthology/P16-1162), R Sennrich et al.
3. [Attention-Based Models for Speech Recognition](https://arxiv.org/abs/1506.07503), J Chorowski et al.
4. [Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks](https://www.cs.toronto.edu/~graves/icml_2006.pdf), A Graves et al.
5. [Joint CTC-Attention based End-to-End Speech Recognition using Multi-task Learning](https://arxiv.org/abs/1609.06773), S Kim et al.
6. [Advances in Joint CTC-Attention based End-to-End Speech Recognition with a Deep CNN Encoder and RNN-LM](https://arxiv.org/abs/1706.02737), T Hori et al.
------
## Donation
If this project help you reduce time to develop, you can give me a cup of coffee :)
AliPay(支付宝)

WechatPay(微信)

------
## **License**
[MIT](LICENSE) © Kun