https://github.com/jacobsteves/crawlperl
A web crawler made with Perl. Great for grabbing or searching for data off the web, or ensuring that your own site files are secure and hidden.
https://github.com/jacobsteves/crawlperl
crawler perl scripting web-crawler
Last synced: about 1 year ago
JSON representation
A web crawler made with Perl. Great for grabbing or searching for data off the web, or ensuring that your own site files are secure and hidden.
- Host: GitHub
- URL: https://github.com/jacobsteves/crawlperl
- Owner: jacobsteves
- License: mit
- Created: 2017-05-27T16:21:17.000Z (about 9 years ago)
- Default Branch: master
- Last Pushed: 2020-09-10T12:47:20.000Z (almost 6 years ago)
- Last Synced: 2025-03-27T19:08:21.597Z (about 1 year ago)
- Topics: crawler, perl, scripting, web-crawler
- Language: Perl
- Size: 51.8 KB
- Stars: 6
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
[]()
CrawlPerl simulates a firefox browser, travelling to certain websites and downloading the files. Links within the files get travelled to and downloaded. This tool is perfect if you want to ensure the security of your data. If links are not embedded properly or information is not hidden sufficiently, then anyone could just use a tool like this and grab all of your data.
## Getting Started
Head into terminal and run the command:
```
perl CrawlPerl.pl -u [-r ] [-options]
```
with your specified root_url, start_url, and options.
Note:
```
perl CrawlPerl.pl -u
```
also works perfectly. Only add [-options] if you have more to specify. For more information, check out the [help table below](#help-table).
When calling a url, make sure to use a file name as a url suffix like this: `http://url.com/index.html`.
If you do not, then the crawler may have trouble finding the correct directory.
### Demo
[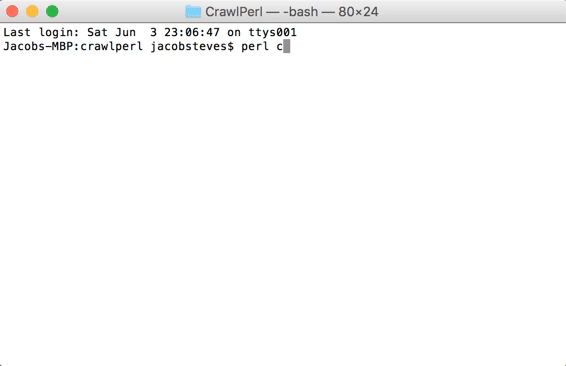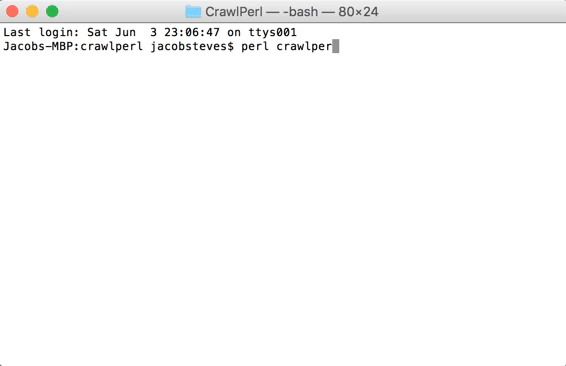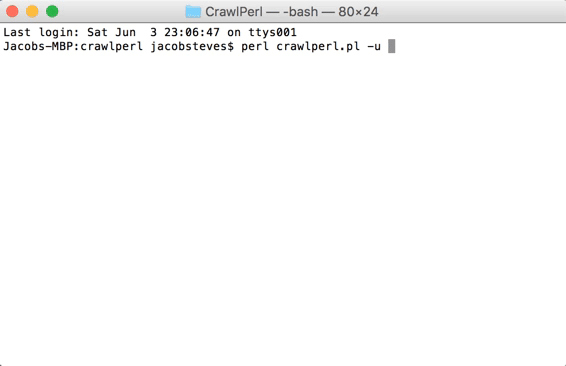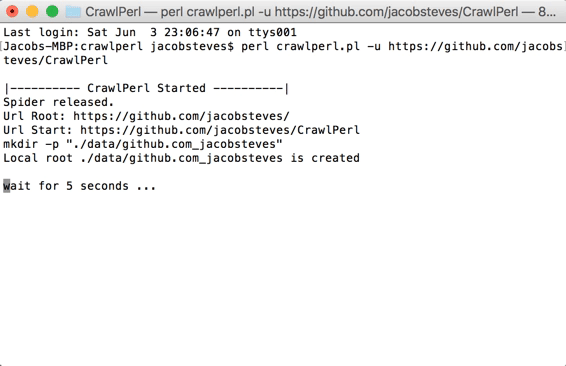](https://gyazo.com/f8c7787ab45a5cdd6a4687a4510baae6)
## Details
When the function is called initially, it creates a local folder ./Data/ within
the same directory that will store all crawled data. For each crawled site, a
subdirectory within ./Data/ is created with the name derived from url_root.
All crawled data will be within there.
A log file, `crawlperl.log` will be created in the main directory containing the crawl history.
A cookie file, `cookie.txt`, may also be created.
## Help table
Usage: perl CrawlPerl.pl -u <url_start> [-r <url_root>] [-options]
NOTE: <val> represents a value. Example,
-b <verbose>
would be implemented with verbose level 3 like..
-b 3
Options:
-b <verbose>: print more details of crawling.
0 (default value) - print only basic information of urls/links crawled.
0x1 = 1 - print the type/size and file download information.
0x2 = 2 - print the saved file local path.
0x4 = 4 - print the reject/ignore file reason.
--verbose: same as -b
-c <seconds>: wait time in seconds before crawling next html page.
-d: debug, print debug information.
--debug: same as -d
-e <default referer>: default referer when crawling a url, if none exists.
This is used when crawling the first page, when no referer exists yet.
--referer-default: same as -e
-f: use flat local path: only one level under local root.
--flat-localpath: same as -f
-g: allow global crawl outside url_root.
--global-crawl: same as -g
-h: print this help message.
--help: same as -h
-i <0 || 1>: download non-text files outside the url_root. Value is on(1)/off(0). Default is on.
Used when some linked files are stored outside the url_root.
--include-outside-file: same as -i
-l <level number>: max levels to crawl. Default to 0, 0 means inifinite.
--level-crawl: same as -l
-m <mime type>: file MIME type. Only files with given MIME types are downloaded.
text - 0x1 = 1
image - 0x2 = 2
audio - 0x4 = 4
video - 0x8 = 8
For more options, head to https://developer.mozilla.org/en-US/docs/Web/HTTP/Basics_of_HTTP/MIME_types/Complete_list_of_MIME_types.
--mime_type: same as -m
-n <number of links>: the number of links to crawl. 0 means inifinite.
-o <0 || 1 || 2>: overwrite previous download result.
0: do not overwrite; 1: move from Dir to Dir-2; 2: remove.
When not specify -o, is 0; when use -o without a value, default to 1.
--overwrite: same as -o
-r <url_root>: root url.
Only files under this path are downloaded. Except when -o is used.
--url-root: same as -r
-s: only download static pages.
Dynamic pages with parameters like http://test.php?a=b are ignored.
--static-only: same as -s
-u <url_start>: start url.
This is where a crawling task starts from.
--url_start: same as -u
-v: show version information.
--version: same as -v
-V: verbose.
--verbose: same as -V
-w <seconds>: wait time (seconds) before getting next url. Difference of this
with -c is: on each html page, there can be several urls. -c is
for each html page, -w is for each url.
--wait: same as -w
Other Options:
--min-size: min file size to download, in bytes.
--max-size: max file size to download, in bytes. 0 means infinite.
--number-crawl: same as -t
The two crucial options are:
-r or --url-root : url_root is needed, if not provided, use longest path of url_start.
-u or --url-start: url_start, if not provided, use url_root as default.
-r, -u, or both must be provided for the spider to be released.
If an url contains special characters, like space or '&', then
it may need to be enclosed in double quotes.
To see perldoc document, type: perldoc $0
Examples:
perl CrawlPerl.pl -h
perl CrawlPerl.pl -r http://test.com
perl CrawlPerl.pl -u http://test.com/index.html
perl CrawlPerl.pl -r http://test.com -u http://test.com/about.html
perl CrawlPerl.pl --url-root http://test.com
perl CrawlPerl.pl --url-root http://test.com --url-start http://test.com/
perl CrawlPerl.pl --url-root http://test.com -n 1 -m 2 -f --min-size 15000
Remember to be specific when specifing crawlers.
http://test.com may not work, while http://test.com/index.html may work.
Happy Crawling.