https://github.com/jaronoff97/redditscraper
This project scrapes reddit and then generates recommendations for a user
https://github.com/jaronoff97/redditscraper
python r-language reddit scraper
Last synced: about 1 year ago
JSON representation
This project scrapes reddit and then generates recommendations for a user
- Host: GitHub
- URL: https://github.com/jaronoff97/redditscraper
- Owner: jaronoff97
- Created: 2017-08-27T23:01:06.000Z (almost 9 years ago)
- Default Branch: master
- Last Pushed: 2017-08-28T00:51:28.000Z (almost 9 years ago)
- Last Synced: 2025-02-08T16:43:41.261Z (over 1 year ago)
- Topics: python, r-language, reddit, scraper
- Language: Python
- Homepage:
- Size: 437 KB
- Stars: 3
- Watchers: 2
- Forks: 1
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# Reddit scraper
This project scrapes reddit and inserts a user's comment history into a database. This is the report I wrote up:
*Jacob Aronoff*
*Sunday April 23, 2017*
*Data Science 4100*
*Final Project Report*
## Project Goal:
My goal was to recommend new subreddits for a given user based on their publicly available data. After researching recommendation methods, I found that collaborative filtering was the common approach. There are two kinds of collaborative filtering algorithms, item based and user based. Item based filtering determines similarities between items and uses preexisting items to recommend new ones. User based filtering finds the similarity between two users and recommends based on user preferences. I decided that user based filtering would be a better approach because it’s tough to draw a correlation between subreddits based on their users.
## Project Process:
I began my project thinking I was going to use the following stack: Node backend with an express server that connects to a database from google big query and have a react frontend do display results. I looked more into connecting to Google BigQuery and found that the dataset I’ll be working with is 850 GB. I wasn’t sure how possible it was to run this program efficiently, but I tried it out nonetheless. I also tried to have the entire query be on the database side to alleviate the servers load.
Before I could even write code, I had to find a small server that would allow me to connect to GBQ and others. I first tried running a server on heroku, which didn’t work. After that I tried using AWS elastic beanstalk, but that was also a bust. I then made a server on Google Cloud Platform, which worked! Once I was up and running I wrote the basic query code that I was going to need. While my queries worked well, they were very slow and that was just getting data, I couldn’t figure out how to do the collaborative filtering with just SQL. After working on that for a couple more hours, I decided to take a different approach to complete my project.
I decided to move to a dedicated python server on AWS which would house a MySQL database and a scraper. I then made an R script that connected to the database and ran the algorithm for collaborative filtering. This approach worked far better, the only problem was I am analyzing off a smaller data set. Rather than getting the data from the whole database, I would kickoff different scrappers to get only the aggregate data that I needed traversing through different subreddits. After letting the scraper run for a couple of hours, I wrote the code for recommending a new subreddit. The code was made simple using the “recommenderLab” package in R, using the package was cumbersome because there was very little documentation. Once I got the recommender code working, I ran it, and it worked! It can now recommend n subreddits for a given user in the database. And to add a new user to the database, you simply kickoff the python process for the new user. Currently there are 158166 rows in the database. I have two tables in the database, one which keeps track of a user, the other which keeps track of “visit information” i.e. how many comments and posts for a given subreddit and user.
With more time, I would be able to make a frontend to interact with the scraper and the recommendation engine. The frontend would give the backend a username and then check if it’s already in the database, if it is kickoff the recommender for the user, if not scrape the data for that user and kickoff the recommender. The recommender then processes the information and responds with that user’s recommendations.
## Results:
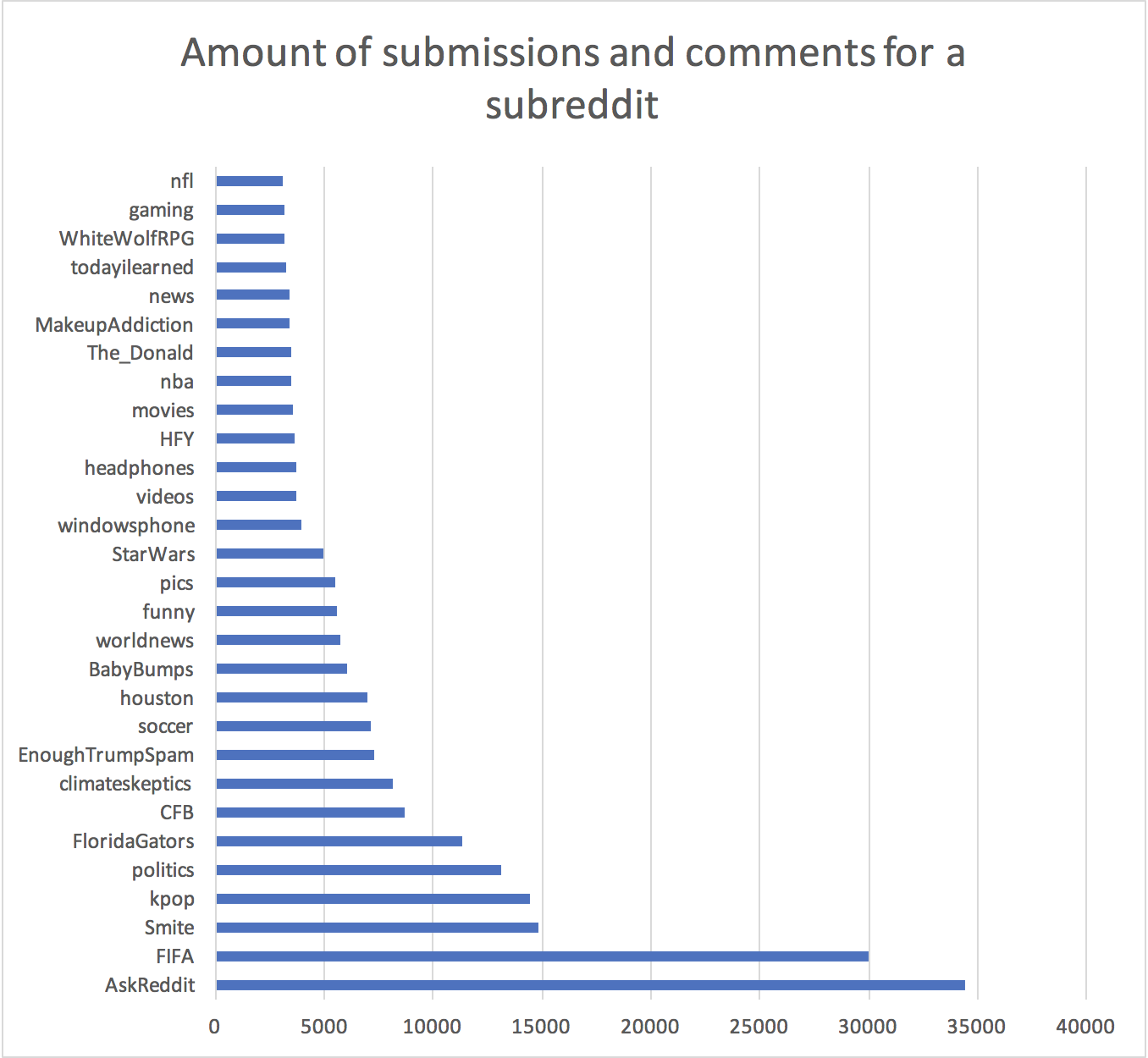
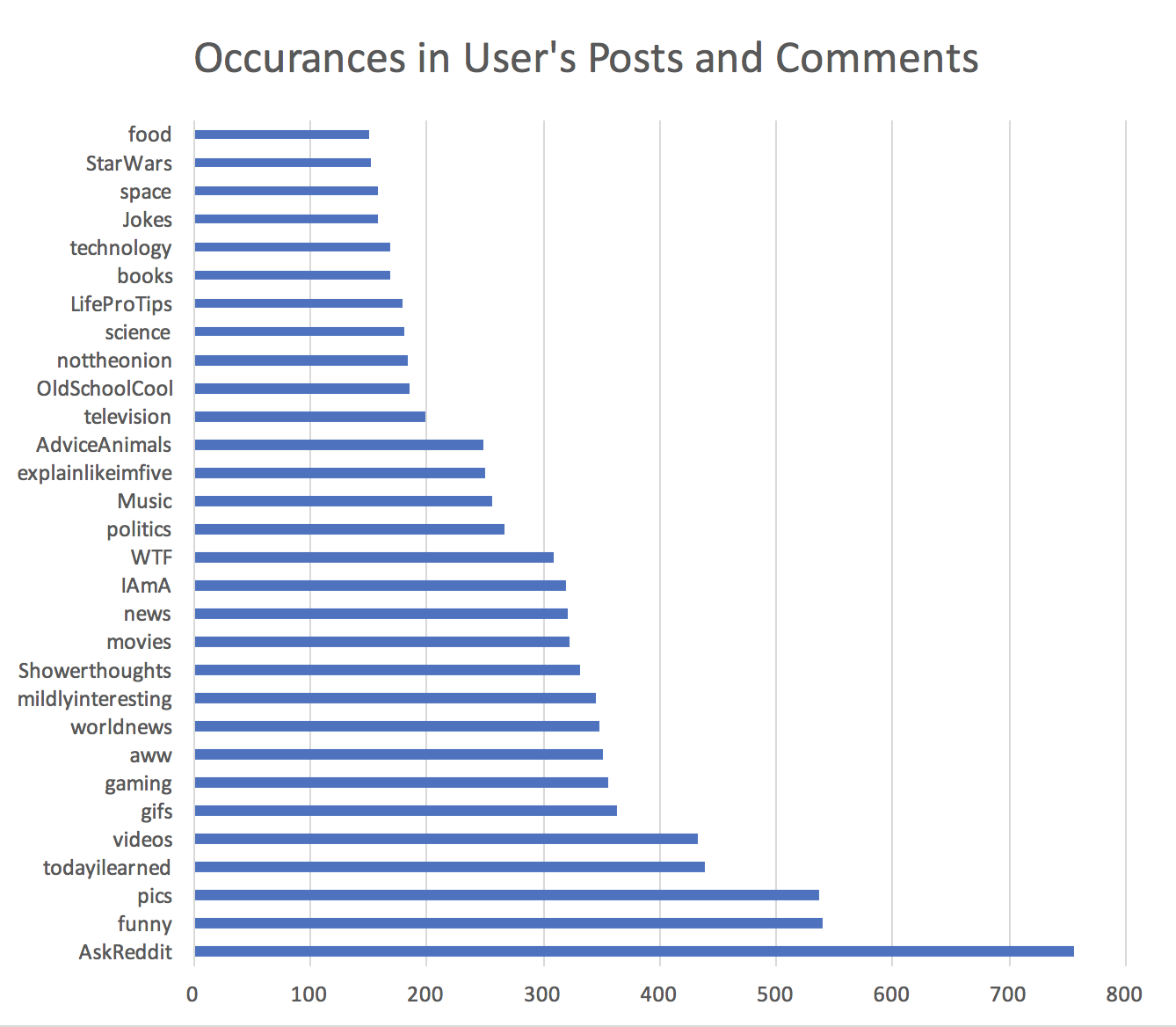
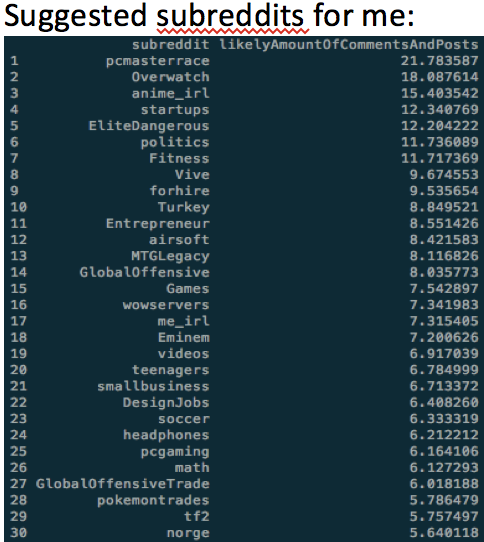
Technically, my algorithm is predicting where else I’m likely to post and/or comment, however, considering I’m making the assumption that one’s amount of posts and/or comments indicates a preference, it’s fair to say that I’m likely to also enjoy “pcmasterrace”
## USAGE
### Scraper
Setup scraper:
`pip install -r requirements.txt`
`touch .env`
fill .env with the following info:
```
RDS_HOSTNAME=_X_X_X_X_X_X_X
RDS_DB_NAME=_X_X_X_X_X_X_X
RDS_PASSWORD=_X_X_X_X_X_X_X
RDS_PORT=_X_X_X_X_X_X_X
RDS_USERNAME=_X_X_X_X_X_X_X
CLIENT_ID=_X_X_X_X_X_X_X
CLIENT_SECRET=_X_X_X_X_X_X_X
```
`export $(cat .env | xargs)`
Change lines 23 and 24 to your initial username
`python scraper.py`
let that run as long as you want, you may need to restart it a couple of times
You can check the progress by running `application.py` and visiting localhost
### Analysis
Setup the database
IN SQL
~~~ SQL
CREATE TABLE `redditUser` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
)
CREATE TABLE `redditVisitInformation` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`redditUser_id` int(11) DEFAULT NULL,
`subreddit` varchar(255) DEFAULT NULL,
`timesCommented` int(11) DEFAULT NULL,
`timesPosted` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `redditUser_id` (`redditUser_id`),
CONSTRAINT `redditvisitinformation_ibfk_1` FOREIGN KEY (`redditUser_id`) REFERENCES `redditUser` (`id`)
)
~~~
In R
install:
* recommenderlab
* RMySQL
Be sure you sourced your environment variables
Call the RScript with your username:
`Rscript project.R `