https://github.com/jbellis/jvector
JVector: the most advanced embedded vector search engine
https://github.com/jbellis/jvector
ann java knn machine-learning search-engine similarity-search vector-search
Last synced: over 1 year ago
JSON representation
JVector: the most advanced embedded vector search engine
- Host: GitHub
- URL: https://github.com/jbellis/jvector
- Owner: jbellis
- License: apache-2.0
- Created: 2023-08-25T01:45:20.000Z (almost 3 years ago)
- Default Branch: main
- Last Pushed: 2025-03-07T01:51:01.000Z (over 1 year ago)
- Last Synced: 2025-03-09T23:26:26.302Z (over 1 year ago)
- Topics: ann, java, knn, machine-learning, search-engine, similarity-search, vector-search
- Language: Java
- Homepage:
- Size: 13.6 MB
- Stars: 1,558
- Watchers: 31
- Forks: 121
- Open Issues: 20
-
Metadata Files:
- Readme: README.md
- License: LICENSE.txt
Awesome Lists containing this project
- awesome-vector-database - jvector
- awesome-vector-databases - jvector - jvector is a high-performance Java-based library and engine for vector search and approximate nearest neighbor indexing. ([Read more](/details/jvector.md)) `ANN` `vector search` `high-performance` (Sdks & Libraries)
- awesome-vector-search - JVector - A pure Java, zero dependency, embedded vector search engine used by some of the advanced distributed databases such as DataStax Astra DB & Apache Cassandra™
README
## Introduction to approximate nearest neighbor search
Exact nearest neighbor search (k-nearest-neighbor or KNN) is prohibitively expensive at higher dimensions, because approaches to segment the search space that work in 2D or 3D like quadtree or k-d tree devolve to linear scans at higher dimensions. This is one aspect of what is called “[the curse of dimensionality](https://en.wikipedia.org/wiki/Curse_of_dimensionality).”
With larger datasets, it is almost always more useful to get an approximate answer in logarithmic time, than the exact answer in linear time. This is abbreviated as ANN (approximate nearest neighbor) search.
There are two broad categories of ANN index:
* Partition-based indexes, like [LSH or IVF](https://www.datastax.com/guides/what-is-a-vector-index) or [SCANN](https://github.com/google-research/google-research/tree/master/scann)
* Graph indexes, like [HNSW](https://arxiv.org/abs/1603.09320) or [DiskANN](https://www.microsoft.com/en-us/research/project/project-akupara-approximate-nearest-neighbor-search-for-large-scale-semantic-search/)
Graph-based indexes tend to be simpler to implement and faster, but more importantly they can be constructed and updated incrementally. This makes them a much better fit for a general-purpose index than partitioning approaches that only work on static datasets that are completely specified up front. That is why all the major commercial vector indexes use graph approaches.
JVector is a graph index in the DiskANN family tree.
## JVector Architecture
JVector is a graph-based index that builds on the DiskANN design with composeable extensions.
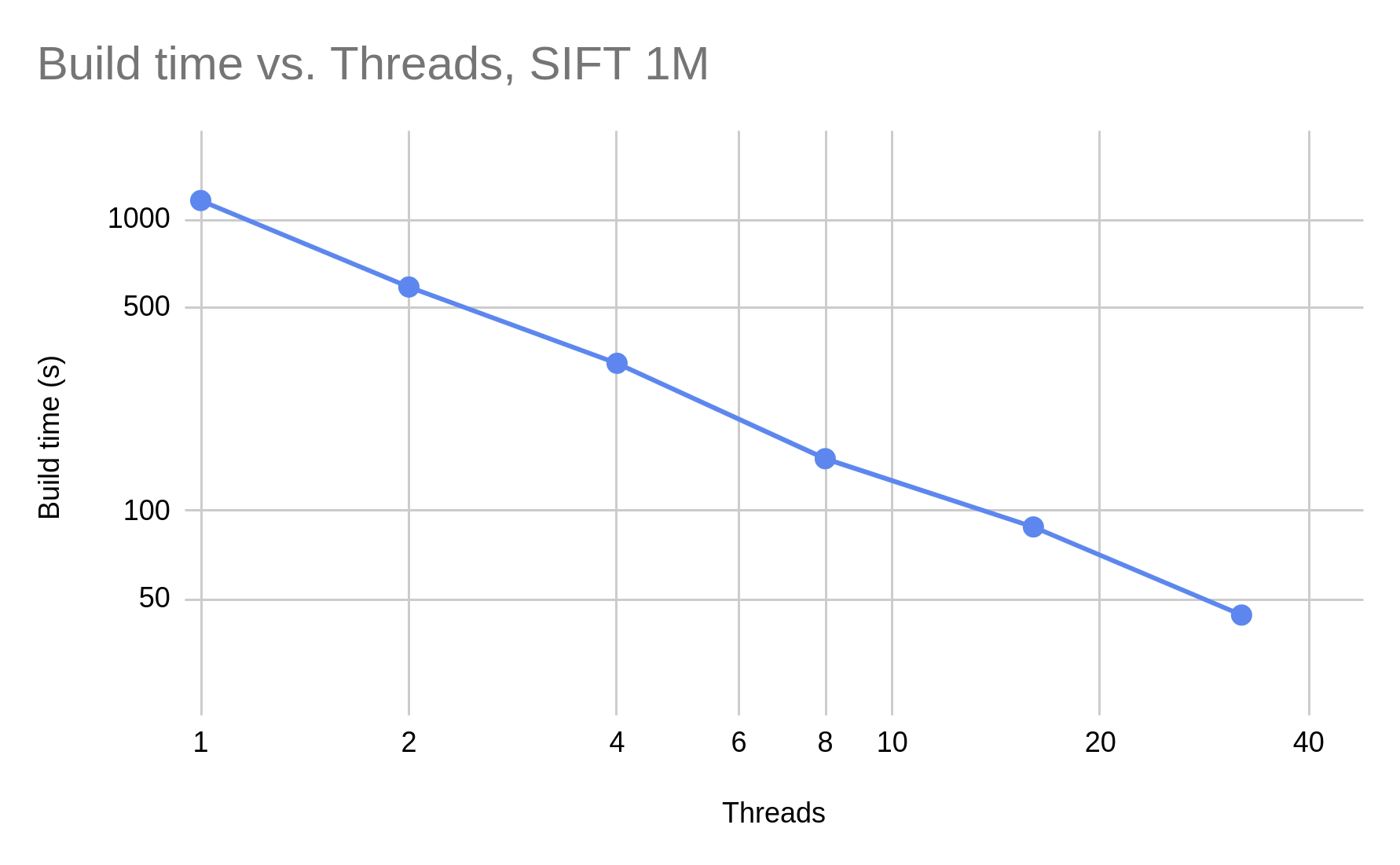
JVector implements a single-layer graph with nonblocking concurrency control, allowing construction to scale linearly with the number of cores:
The graph is represented by an on-disk adjacency list per node, with additional data stored inline to support two-pass searches, with the first pass powered by lossily compressed representations of the vectors kept in memory, and the second by a more accurate representation read from disk. The first pass can be performed with
* Product quantization (PQ), optionally with [anisotropic weighting](https://arxiv.org/abs/1908.10396)
* [Binary quantization](https://huggingface.co/blog/embedding-quantization) (BQ)
* Fused ADC, where PQ codebooks are transposed and written inline with the graph adjacency list
The second pass can be performed with
* Full resolution float32 vectors
* NVQ, which uses a non-uniform technique to quantize vectors with high-accuracy
[This two-pass design reduces memory usage and reduces latency while preserving accuracy](https://thenewstack.io/why-vector-size-matters/).
Additionally, JVector is unique in offering the ability to construct the index itself using two-pass searches, allowing larger-than-memory indexes to be built:

This is important because it allows you to take advantage of logarithmic search within a single index, instead of spilling over to linear-time merging of results from multiple indexes.
## JVector step-by-step
All code samples are from [SiftSmall](https://github.com/jbellis/jvector/blob/main/jvector-examples/src/main/java/io/github/jbellis/jvector/example/SiftSmall.java) in the JVector source repo, which includes the siftsmall dataset as well. Just import the project in your IDE and click Run to try it out!
#### Step 1: Build and query an index in memory
First the code:
```java
public static void siftInMemory(ArrayList> baseVectors) throws IOException {
// infer the dimensionality from the first vector
int originalDimension = baseVectors.get(0).length();
// wrap the raw vectors in a RandomAccessVectorValues
RandomAccessVectorValues ravv = new ListRandomAccessVectorValues(baseVectors, originalDimension);
// score provider using the raw, in-memory vectors
BuildScoreProvider bsp = BuildScoreProvider.randomAccessScoreProvider(ravv, VectorSimilarityFunction.EUCLIDEAN);
try (GraphIndexBuilder builder = new GraphIndexBuilder(bsp,
ravv.dimension(),
16, // graph degree
100, // construction search depth
1.2f, // allow degree overflow during construction by this factor
1.2f)) // relax neighbor diversity requirement by this factor
{
// build the index (in memory)
OnHeapGraphIndex index = builder.build(ravv);
// search for a random vector
VectorFloat> q = randomVector(originalDimension);
SearchResult sr = GraphSearcher.search(q,
10, // number of results
ravv, // vectors we're searching, used for scoring
VectorSimilarityFunction.EUCLIDEAN, // how to score
index,
Bits.ALL); // valid ordinals to consider
for (SearchResult.NodeScore ns : sr.getNodes()) {
System.out.println(ns);
}
}
}
```
Commentary:
* All indexes assume that you have a source of vectors that has a consistent, fixed dimension (number of float32 components).
* Vector sources are usually represented as a subclass of [RandomAccessVectorValues](https://javadoc.io/doc/io.github.jbellis/jvector/latest/io/github/jbellis/jvector/graph/RandomAccessVectorValues.html), which offers a simple API around getVector / getVectorInto. Do be aware of isValueShared() in a multithreaded context; as a rule of thumb, in-memory RAVV will not use shared values and from-disk RAVV will (as an optimization to avoid allocating a new on-heap vector for every call).
* You do NOT have to provide all the vectors to the index at once, but since this is a common scenario when prototyping, a convenience method is provided to do so. We will cover how to build an index incrementally later.
* For the overflow Builder parameter, the sweet spot is about 1.2 for in-memory construction and 1.5 for on-disk. (The more overflow is allowed, the fewer recomputations of best edges are required, but the more neighbors will be consulted in every search.)
* The alpha parameter controls the tradeoff between edge distance and diversity; usually 1.2 is sufficient for high-dimensional vectors; 2.0 is recommended for 2D or 3D datasets. See [the DiskANN paper](https://suhasjs.github.io/files/diskann_neurips19.pdf) for more details.
* The Bits parameter to GraphSearcher is intended for controlling your resultset based on external predicates and won’t be used in this tutorial.
#### Step 2: more control over GraphSearcher
Keeping the Builder the same, the updated search code looks like this:
```java
// search for a random vector using a GraphSearcher and SearchScoreProvider
VectorFloat> q = randomVector(originalDimension);
try (GraphSearcher searcher = new GraphSearcher(index)) {
SearchScoreProvider ssp = SearchScoreProvider.exact(q, VectorSimilarityFunction.EUCLIDEAN, ravv);
SearchResult sr = searcher.search(ssp, 10, Bits.ALL);
for (SearchResult.NodeScore ns : sr.getNodes()) {
System.out.println(ns);
}
}
```
Commentary:
* Searcher allocation is modestly expensive since there is a bunch of internal state to initialize at construction time. Therefore, JVector supports pooling searchers (e.g. with [ExplicitThreadLocal](https://javadoc.io/doc/io.github.jbellis/jvector/latest/io/github/jbellis/jvector/util/ExplicitThreadLocal.html), covered below).
* When managing GraphSearcher instances, you’re also responsible for constructing a SearchScoreProvider, which you can think of as: given a query vector, tell JVector how to compute scores for other nodes in the index. SearchScoreProvider can be exact, as shown here, or a combination of an ApproximateScoreFunction and a Reranker, covered below.
#### Step 3: Measuring recall
A blisteringly-fast vector index isn’t very useful if it doesn’t return accurate results. As a sanity check, SiftSmall includes a helper method _testRecall_. Wiring up that to our code mostly involves turning the SearchScoreProvider into a factory lambda:
```java
Function, SearchScoreProvider> sspFactory = q -> SearchScoreProvider.exact(q, VectorSimilarityFunction.EUCLIDEAN, ravv);
testRecall(index, queryVectors, groundTruth, sspFactory);
```
If you run the code, you will see slight differences in recall every time (printed by `testRecall`):
```
(OnHeapGraphIndex) Recall: 0.9898
...
(OnHeapGraphIndex) Recall: 0.9890
```
This is expected given the approximate nature of the index being created and the perturbations introduced by the multithreaded concurrency of the `build` call.
#### Step 4: write and load index to and from disk
The code:
```java
Path indexPath = Files.createTempFile("siftsmall", ".inline");
try (GraphIndexBuilder builder = new GraphIndexBuilder(bsp, ravv.dimension(), 16, 100, 1.2f, 1.2f)) {
// build the index (in memory)
OnHeapGraphIndex index = builder.build(ravv);
// write the index to disk with default options
OnDiskGraphIndex.write(index, ravv, indexPath);
}
// on-disk indexes require a ReaderSupplier (not just a Reader) because we will want it to
// open additional readers for searching
ReaderSupplier rs = ReaderSupplierFactor.open(indexPath);
OnDiskGraphIndex index = OnDiskGraphIndex.load(rs);
// measure our recall against the (exactly computed) ground truth
Function, SearchScoreProvider> sspFactory = q -> SearchScoreProvider.exact(q, VectorSimilarityFunction.EUCLIDEAN, index.getView());
testRecall(index, queryVectors, groundTruth, sspFactory);
```
Commentary:
* We can write indexes that are constructed in-memory, like this one, to disk with a single method call.
* Loading and searching against on-disk indexes require a ReaderSupplier, which supplies RandomAccessReader objects. The RandomAccessReader interface is intended to be extended by the consuming project. For instance, [DataStax Astra](https://www.datastax.com/products/datastax-astra) implements a RandomAccessReader backed by the Cassandra chunk cache. JVector provides two implementations out of the box.
* SimpleMappedReader: implemented using FileChannel.map, which means it is compatible with all Java versions that can run JVector, but also means it is limited to 2GB file sizes. SimpleMappedReader is primarily intended for example code.
* MemorySegmentReader: implemented using the newer MemorySegment API, with no file size limit, but is limited to Java 22+. (The actual MemorySegmentReader code is compatible with Java 20+, but [we left it in the 22+ module for convenience](https://github.com/jbellis/jvector/pull/296). The motivated reader is welcome to refactor the build to improve this.) If you have no specialized requirements then MemorySegmentReader is recommended for production.
#### Step 5: use compressed vectors in the search
Compressing the vectors with product quantization is done as follows:
```java
// compute and write compressed vectors to disk
Path pqPath = Files.createTempFile("siftsmall", ".pq");
try (DataOutputStream out = new DataOutputStream(new BufferedOutputStream(Files.newOutputStream(pqPath)))) {
// Compress the original vectors using PQ. this represents a compression ratio of 128 * 4 / 16 = 32x
ProductQuantization pq = ProductQuantization.compute(ravv,
16, // number of subspaces
256, // number of centroids per subspace
true); // center the dataset
// Note: before jvector 3.1.0, encodeAll returned an array of ByteSequence.
PQVectors pqv = pq.encodeAll(ravv);
// write the compressed vectors to disk
pqv.write(out);
}
```
* JVector also supports Binary Quantization, but [BQ is generally less useful than PQ since it takes such a large toll on search accuracy](https://thenewstack.io/why-vector-size-matters/).
Then we can wire up the compressed vectors to a two-phase search by getting the fast ApproximateScoreFunction from PQVectors, and the Reranker from the index View:
```java
ReaderSupplier rs = ReaderSupplierFactory.open(indexPath);
OnDiskGraphIndex index = OnDiskGraphIndex.load(rs);
// load the PQVectors that we just wrote to disk
try (ReaderSupplier pqSupplier = ReaderSupplierFactory.open(pqPath);
RandomAccessReader in = pqSupplier.get())
{
PQVectors pqv = PQVectors.load(in);
// SearchScoreProvider that does a first pass with the loaded-in-memory PQVectors,
// then reranks with the exact vectors that are stored on disk in the index
Function, SearchScoreProvider> sspFactory = q -> {
ApproximateScoreFunction asf = pqv.precomputedScoreFunctionFor(q, VectorSimilarityFunction.EUCLIDEAN);
Reranker reranker = index.getView().rerankerFor(q, VectorSimilarityFunction.EUCLIDEAN);
return new SearchScoreProvider(asf, reranker);
};
// measure our recall against the (exactly computed) ground truth
testRecall(index, queryVectors, groundTruth, sspFactory);
}
```
* PQVectors offers both precomputedScoreFunctionFor and scoreFunctionFor factories. As the name implies, the first precalculates the fragments of distance needed from the PQ codebook for assembly by ADC (asymmetric distance computation). This is faster for searching all but the smallest of indexes, but if you do have a tiny index or you need to perform ADC in another context, the scoreFunctionFor version with no precomputation will come in handy.
This set of functionality is the classic DiskANN design.
#### Step 6: building a larger-than-memory index
JVector can also apply PQ compression to allow indexing a larger than memory dataset: only the compressed vectors are kept in memory.
First we need to set up a PQVectors instance that we can add new vectors to, and a BuildScoreProvider using it:
```java
// compute the codebook, but don't encode any vectors yet
ProductQuantization pq = ProductQuantization.compute(ravv, 16, 256, true);
// as we build the index we'll compress the new vectors and add them to this List backing a PQVectors;
// this is used to score the construction searches
List> incrementallyCompressedVectors = new ArrayList<>();
PQVectors pqv = new PQVectors(pq, incrementallyCompressedVectors);
BuildScoreProvider bsp = BuildScoreProvider.pqBuildScoreProvider(VectorSimilarityFunction.EUCLIDEAN, pqv);
```
Then we need to set up an OnDiskGraphIndexWriter with full control over the construction process.
```java
Path indexPath = Files.createTempFile("siftsmall", ".inline");
Path pqPath = Files.createTempFile("siftsmall", ".pq");
// Builder creation looks mostly the same
try (GraphIndexBuilder builder = new GraphIndexBuilder(bsp, ravv.dimension(), 16, 100, 1.2f, 1.2f);
// explicit Writer for the first time, this is what's behind OnDiskGraphIndex.write
OnDiskGraphIndexWriter writer = new OnDiskGraphIndexWriter.Builder(builder.getGraph(), indexPath)
.with(new InlineVectors(ravv.dimension()))
.withMapper(new OnDiskGraphIndexWriter.IdentityMapper())
.build();
// output for the compressed vectors
DataOutputStream pqOut = new DataOutputStream(new BufferedOutputStream(Files.newOutputStream(pqPath))))
```
Once that’s done, we can index vectors one at a time:
```java
// build the index vector-at-a-time (on disk)
for (VectorFloat> v : baseVectors) {
// compress the new vector and add it to the PQVectors (via incrementallyCompressedVectors)
int ordinal = incrementallyCompressedVectors.size();
incrementallyCompressedVectors.add(pq.encode(v));
// write the full vector to disk
writer.writeInline(ordinal, Feature.singleState(FeatureId.INLINE_VECTORS, new InlineVectors.State(v)));
// now add it to the graph -- the previous steps must be completed first since the PQVectors
// and InlineVectorValues are both used during the search that runs as part of addGraphNode construction
builder.addGraphNode(ordinal, v);
}
```
Finally, we need to run cleanup() and write the index and the PQVectors to disk:
```java
// cleanup does a final enforcement of maxDegree and handles other scenarios like deleted nodes
// that we don't need to worry about here
builder.cleanup();
// finish writing the index (by filling in the edge lists) and write our completed PQVectors
writer.write(Map.of());
pqv.write(pqOut);
````
Commentary:
* The search code doesn’t change when switching to incremental index construction – it’s the same index structure on disk, just (potentially) much larger.
* OnDiskGraphIndexWriter::writeInline is threadsafe via synchronization, but care must be taken that the support structures are threadsafe as well if you plan to use them in a multithreaded scenario (which this example is not). Alternatively, you can serialize the updates to PQVectors and leave only the call to GraphIndexBuilder::addGraphNode concurrent. This represents the lion’s share of construction time so you will see good performance with that approach.
### Less-obvious points
* Embeddings models product output from a consistent distribution of vectors. This means that you can save and re-use ProductQuantization codebooks, even for a different set of vectors, as long as you had a sufficiently large training set to build it the first time around. ProductQuantization.MAX_PQ_TRAINING_SET_SIZE (128,000 vectors) has proven to be sufficiently large.
* JDK ThreadLocal objects cannot be referenced except from the thread that created them. This is a difficult design into which to fit caching of Closeable objects like GraphSearcher. JVector provides the ExplicitThreadLocal class to solve this.
* Fused ADC is only compatible with Product Quantization, not Binary Quantization. This is no great loss since [very few models generate embeddings that are best suited for BQ](https://thenewstack.io/why-vector-size-matters/). That said, BQ continues to be supported with non-Fused indexes.
* JVector heavily utilizes the Panama Vector API(SIMD) for ANN indexing and search. We have seen cases where the memory bandwidth is saturated during indexing and product quantization and can cause the process to slow down. To avoid this, the batch methods for index and PQ builds use a [PhysicalCoreExecutor](https://javadoc.io/doc/io.github.jbellis/jvector/latest/io/github/jbellis/jvector/util/PhysicalCoreExecutor.html) to limit the amount of operations to the physical core count. The default value is 1/2 the processor count seen by Java. This may not be correct in all setups (e.g. no hyperthreading or hybrid architectures) so if you wish to override the default use the `-Djvector.physical_core_count` property, or pass in your own ForkJoinPool instance.
### Advanced features
* Fused ADC is represented as a Feature that is supported during incremental index construction, like InlineVectors above. [See the Grid class for sample code](https://github.com/jbellis/jvector/blob/main/jvector-examples/src/main/java/io/github/jbellis/jvector/example/Grid.java).
* Anisotropic PQ is built into the ProductQuantization class and can improve recall, but nobody knows how to tune it (with the T/threshold parameter) except experimentally on a per-model basis, and choosing the wrong setting can make things worse. From Figure 3 in the paper:

* JVector supports in-place deletes via GraphIndexBuilder::markNodeDeleted. Deleted nodes are removed and connections replaced during GraphIndexBuilder::cleanup, with runtime proportional to the number of deleted nodes.
* To checkpoint a graph and reload it for continued editing, use OnHeapGraphIndex::save and GraphIndexBuilder.load.
## The research behind the algorithms
* Foundational work: [HNSW](https://ieeexplore.ieee.org/abstract/document/8594636) and [DiskANN](https://suhasjs.github.io/files/diskann_neurips19.pdf) papers, and [a higher level explainer](https://www.datastax.com/guides/hierarchical-navigable-small-worlds)
* [Anisotropic PQ paper](https://arxiv.org/abs/1908.10396)
* [Quicker ADC paper](https://arxiv.org/abs/1812.09162)
## Developing and Testing
This project is organized as a [multimodule Maven build](https://maven.apache.org/guides/mini/guide-multiple-modules.html). The intent is to produce a multirelease jar suitable for use as
a dependency from any Java 11 code. When run on a Java 20+ JVM with the Vector module enabled, optimized vector
providers will be used. In general, the project is structured to be built with JDK 20+, but when `JAVA_HOME` is set to
Java 11 -> Java 19, certain build features will still be available.
Base code is in [jvector-base](./jvector-base) and will be built for Java 11 releases, restricting language features and APIs
appropriately. Code in [jvector-twenty](./jvector-twenty) will be compiled for Java 20 language features/APIs and included in the final
multirelease jar targeting supported JVMs. [jvector-multirelease](./jvector-multirelease) packages [jvector-base](./jvector-base) and [jvector-twenty](./jvector-twenty) as a
multirelease jar for release. [jvector-examples](./jvector-examples) is an additional sibling module that uses the reactor-representation of
jvector-base/jvector-twenty to run example code. [jvector-tests](./jvector-tests) contains tests for the project, capable of running against
both Java 11 and Java 20+ JVMs.
To run tests, use `mvn test`. To run tests against Java 20+, use `mvn test`. To run tests against Java 11, use `mvn -Pjdk11 test`.
To run a single test class, use the Maven Surefire test filtering capability, e.g.,
`mvn -Dsurefire.failIfNoSpecifiedTests=false -Dtest=TestNeighborArray test`.
You may also use method-level filtering and patterns, e.g.,
`mvn -Dsurefire.failIfNoSpecifiedTests=false -Dtest=TestNeighborArray#testRetain* test`.
(The `failIfNoSpecifiedTests` option works around a quirk of surefire: it is happy to run `test` with submodules with empty test sets,
but as soon as you supply a filter, it wants at least one match in every submodule.)
You can run `SiftSmall` and `Bench` directly to get an idea of what all is going on here. `Bench` will automatically download required datasets to the `fvec` and `hdf5` directories.
The files used by `SiftSmall` can be found in the [siftsmall directory](./siftsmall) in the project root.
To run either class, you can use the Maven exec-plugin via the following incantations:
> `mvn compile exec:exec@bench`
or for Sift:
> `mvn compile exec:exec@sift`
`Bench` takes an optional `benchArgs` argument that can be set to a list of whitespace-separated regexes. If any of the
provided regexes match within a dataset name, that dataset will be included in the benchmark. For example, to run only the glove
and nytimes datasets, you could use:
> `mvn compile exec:exec@bench -DbenchArgs="glove nytimes"`
To run Sift/Bench without the JVM vector module available, you can use the following invocations:
> `mvn -Pjdk11 compile exec:exec@bench`
> `mvn -Pjdk11 compile exec:exec@sift`
The `... -Pjdk11` invocations will also work with `JAVA_HOME` pointing at a Java 11 installation.
To release, configure `~/.m2/settings.xml` to point to OSSRH and run `mvn -Prelease clean deploy`.
---